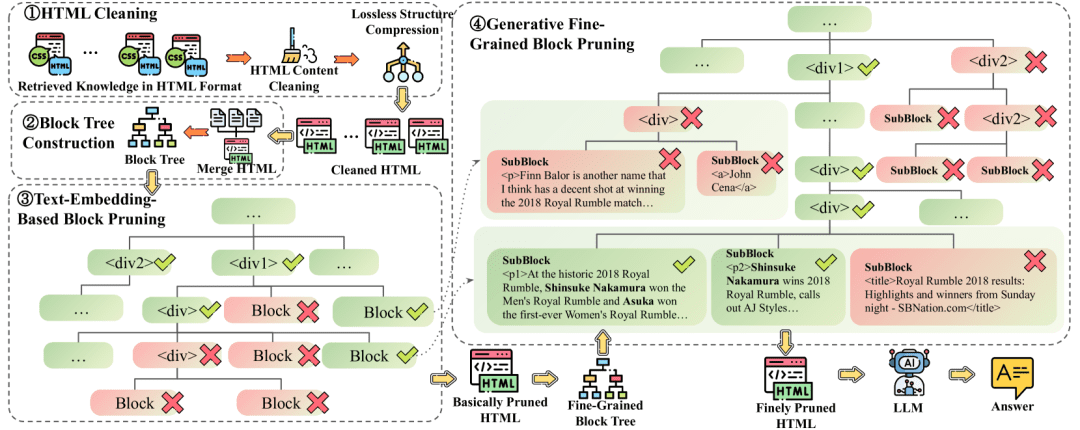
Firecrawl MCP Server: Servicio MCP de rastreo web basado en Firecrawl
Últimos recursos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 70.1K 00

Introducción general
Firecrawl MCP Server es una herramienta de código abierto desarrollada por MendableAI basada en la Modelo de Protocolo de Contexto (MCP), integrada con la API Firecrawl, proporciona un potente rastreo web y extracción de datos. Diseñado para modelos de IA como Cursor, Claude y otros clientes LLM, admite una amplia gama de operaciones, desde el rastreo de una sola página hasta el rastreo por lotes, la búsqueda y la extracción de datos estructurados. Tanto si se trata de renderización JavaScript de páginas web dinámicas, rastreo profundo y filtrado de contenidos, Firecrawl MCP Server realiza el trabajo de forma eficiente. La herramienta admite implementaciones en la nube y autoalojadas con reintentos automáticos, limitación de velocidad y sistemas de registro para desarrolladores, investigadores e ingenieros de datos. Desde marzo de 2025, el proyecto se actualiza continuamente en GitHub y goza de un amplio reconocimiento por parte de la comunidad.

Lista de funciones
- Agarre de una sola página: Extrae datos Markdown o estructurados de una URL especificada.
- rastreador masivoGestión eficaz de múltiples URL con soporte para operaciones en paralelo y limitación de velocidad integrada.
- Búsqueda en la Web: Extrae contenido de los resultados de búsqueda a partir de una consulta.
- rastreo profundo: Admite el descubrimiento de URL y el rastreo web multicapa.
- extracción de datosExtracción de información estructurada de páginas web mediante LLM.
- Renderizado JavaScript: Captura el contenido completo de una página web dinámica.
- Filtración inteligenteFiltrado de contenidos mediante inclusión/exclusión de etiquetas.
- Control de las condiciones: Proporciona consultas sobre el progreso de las tareas por lotes y el uso de créditos.
- sistema de registroRegistra el estado operativo, el rendimiento y los mensajes de error.
- Soporte para móviles y ordenadores de sobremesaAdaptación a los diferentes dispositivos de visualización.
Utilizar la ayuda
Proceso de instalación
Firecrawl MCP Server proporciona varios métodos de instalación para diferentes escenarios de uso. A continuación se detallan los pasos a seguir:
Forma 1: Ejecución rápida con npx
- Obtenga la clave API de Firecrawl (regístrese en el sitio web de Firecrawl para obtenerla).
- Abra un terminal y configure las variables de entorno:
export FIRECRAWL_API_KEY="fc-YOUR_API_KEY"
intercambiabilidad "fc-YOUR_API_KEY" para su clave real.
3. Ejecute la orden:
npx -y firecrawl-mcp
- Tras iniciarse correctamente, el terminal muestra
[INFO] FireCrawl MCP Server initialized successfully.
Modo 2: Instalación manual
- Instalación global:
npm install -g firecrawl-mcp - Establezca las variables de entorno (como arriba).
- Corriendo:
firecrawl-mcp
Enfoque 3: implantación autónoma
- Clonar un repositorio GitHub:
git clone https://github.com/mendableai/firecrawl-mcp-server.git cd firecrawl-mcp-server - Instale la dependencia:
npm install - Construir proyecto:
npm run build - Configura las variables de entorno y ejecútalo:
node dist/src/index.js
Forma 4: Ejecutar en el cursor
- seguro Cursor Versión 0.45.6 o superior.
- Abra Configuración del cursor > Funciones > Servidores MCP.
- Haga clic en "+ Añadir nuevo servidor MCP" y entre:
- Nombre.
firecrawl-mcp - Tipo.
command - Comando.
env FIRECRAWL_API_KEY=your-api-key npx -y firecrawl-mcp - Los usuarios de Windows que tengan problemas pueden intentarlo:
cmd /c "set FIRECRAWL_API_KEY=your-api-key && npx -y firecrawl-mcp"
- Nombre.
- Guarde y actualice la lista de servidores MCP, que el Agente Composer invoca automáticamente.
Vía 5: Correr sobre Windsurf
- compilador
./codeium/windsurf/model_config.json::{ "mcpServers": { "mcp-server-firecrawl": { "command": "npx", "args": ["-y", "firecrawl-mcp"], "env": { "FIRECRAWL_API_KEY": "YOUR_API_KEY_HERE" } } } } - Guarda y ejecuta Windsurf.
Configuración de variables de entorno
Configuración requerida
FIRECRAWL_API_KEYClave API de la nube, que debe establecerse cuando se utilizan servicios en la nube.
Configuraciones opcionales
FIRECRAWL_API_URLPuntos finales de la API para instancias autoalojadas, comohttps://firecrawl.your-domain.com.- Vuelva a intentar la configuración:
FIRECRAWL_RETRY_MAX_ATTEMPTSNúmero máximo de reintentos, por defecto 3.FIRECRAWL_RETRY_INITIAL_DELAYRetardo del primer reintento (milisegundos), por defecto 1000.FIRECRAWL_RETRY_MAX_DELAYRetardo máximo en milisegundos, por defecto 10000.FIRECRAWL_RETRY_BACKOFF_FACTORFactor de retroceso: factor de retroceso, por defecto 2.
- Supervisión del crédito:
FIRECRAWL_CREDIT_WARNING_THRESHOLDUmbral de aviso, por defecto 1000.FIRECRAWL_CREDIT_CRITICAL_THRESHOLDUmbral de emergencia, por defecto 100.
Ejemplo de configuración
Uso de la nube:
export FIRECRAWL_API_KEY="your-api-key"
export FIRECRAWL_RETRY_MAX_ATTEMPTS=5
export FIRECRAWL_RETRY_INITIAL_DELAY=2000
export FIRECRAWL_CREDIT_WARNING_THRESHOLD=2000
Funciones principales
Función 1: raspado de una sola página (firecrawl_scrape)
- procedimiento::
- Después de iniciar el servidor, envíe una petición POST:
curl -X POST http://localhost:端口/firecrawl_scrape \ -H "Content-Type: application/json" \ -d '{"url": "https://example.com", "formats": ["markdown"], "onlyMainContent": true, "timeout": 30000}' - Devuelve el contenido principal en formato Markdown.
- Después de iniciar el servidor, envíe una petición POST:
- Descripción de los parámetros::
onlyMainContent: Sólo se extraen los elementos principales.includeTags/excludeTagsEspecifique las etiquetas HTML que desea incluir o excluir.
- escenario de aplicación: Extraiga rápidamente la información esencial de un artículo o una página.
Función 2: Batch Crawl (firecrawl_batch_scrape)
- procedimiento::
- Envía una solicitud masiva:
curl -X POST http://localhost:端口/firecrawl_batch_scrape \ -H "Content-Type: application/json" \ -d '{"urls": ["https://example1.com", "https://example2.com"], "options": {"formats": ["markdown"]}}' - Obtener el ID de la operación, por ejemplo
batch_1. - Comprueba el estado:
curl -X POST http://localhost:端口/firecrawl_check_batch_status \ -H "Content-Type: application/json" \ -d '{"id": "batch_1"}'
- Envía una solicitud masiva:
- caracterizaciónLimitación de velocidad y procesamiento paralelo integrados para la recopilación de datos a gran escala.
Función 3: Búsqueda en la Web (firecrawl_search)
- procedimiento::
- Enviar una solicitud de búsqueda:
curl -X POST http://localhost:端口/firecrawl_search \ -H "Content-Type: application/json" \ -d '{"query": "AI tools", "limit": 5, "scrapeOptions": {"formats": ["markdown"]}}' - Devuelve el contenido Markdown de los resultados de la búsqueda.
- Enviar una solicitud de búsqueda:
- utilice: Acceso en tiempo real a los datos de la página web pertinentes para la consulta.
Función 4: rastreo profundo (firecrawl_crawl)
- procedimiento::
- Iniciar una solicitud de rastreo:
curl -X POST http://localhost:端口/firecrawl_crawl \ -H "Content-Type: application/json" \ -d '{"url": "https://example.com", "maxDepth": 2, "limit": 100}' - Devuelve los resultados del rastreo.
- Iniciar una solicitud de rastreo:
- parámetros::
maxDepthcontrolar la profundidad de rastreo.limitLimite el número de páginas.
Función 5: Extracción de datos (firecrawl_extract)
- procedimiento::
- Envía una solicitud de extracción:
curl -X POST http://localhost:端口/firecrawl_extract \ -H "Content-Type: application/json" \ -d '{"urls": ["https://example.com"], "prompt": "Extract product name and price", "schema": {"type": "object", "properties": {"name": {"type": "string"}, "price": {"type": "number"}}}}' - Devuelve datos estructurados.
- Envía una solicitud de extracción:
- caracterización: Soporte para extracción LLM, esquema personalizado para asegurar el formato de salida.
Trucos y consejos
- Vista de registro: Vigila los registros del terminal en tiempo de ejecución (por ejemplo.
[INFO] Starting scrape) para depurar. - tratamiento de erroresSi te encuentras
[ERROR] Rate limit exceededAjuste los parámetros de reintento o espere. - Integración con LLMEn el Cursor o Claude La herramienta se invoca automáticamente introduciendo los requisitos de rastreo directamente en el archivo
Mediante las operaciones anteriores, los usuarios pueden implantar y utilizar fácilmente Firecrawl MCP Server para satisfacer diversas necesidades de datos web.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...