
FG-CLIP 2 - 360 Modelo de lenguaje visual multimodal de código abierto para gráficos
Últimos recursos sobre IAPublicado hace 5 meses Círculo de intercambio de inteligencia artificial 28.3K 00

Qué es FG-CLIP 2
FG-CLIP 2 es el modelo gráfico de lenguaje visual multimodal (VL-M) líder mundial lanzado por el 360 AI Research Institute, que ha superado a modelos similares de Google y Meta en 29 pruebas comparativas autorizadas, lo que lo convierte en el VL-M más potente. Puede identificar con precisión detalles como pelos, manchas, colores, expresiones faciales y relaciones espaciales en una imagen, por ejemplo, distinguir entre distintas razas de gatos, juzgar la posición de objetos dentro y fuera de la pantalla, e incluso comprender la relación de oclusión en escenas complejas. También admite la comprensión detallada del chino y el inglés, lo que colma la laguna de los modelos multimodales chinos, y puede realizar con precisión tareas como la recuperación de textos largos en chino y la clasificación de regiones. Adopta una estrategia de entrenamiento en dos fases: primero alinea globalmente la semántica gráfica y después se centra en la alineación local de los detalles; combinada con un sistema de optimización colaborativa en cinco dimensiones, mejora la antiinterferencia y la robustez del modelo.
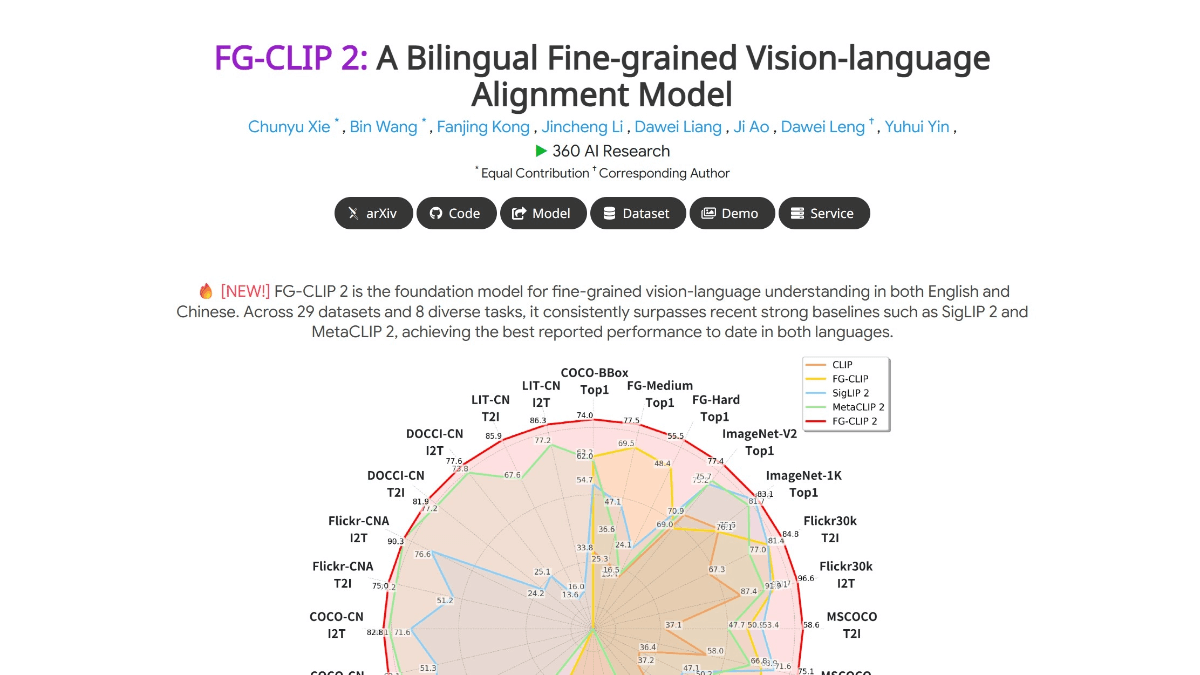
Características funcionales de FG-CLIP 2
- Asistencia bilingüe: Puede gestionar tareas tanto en inglés como en chino para una asistencia nativa verdaderamente bilingüe.
- Comprensión detalladaReconocimiento preciso de los detalles de una imagen, como los atributos de los objetos, las relaciones espaciales, etc., para mejorar la precisión de la alineación del lenguaje visual.
- Atención dinámica: Se centra de forma inteligente en las áreas clave de una imagen para manejar con eficacia escenas visuales complejas.
- Alineación jerárquica: Combinar macroescenarios y microdetalles para mejorar progresivamente la comprensión del modelo.
- Optimizar las sinergias bilingües: Equilibrar la comprensión de inglés y chino para mejorar el rendimiento global en tareas bilingües.
- Respuesta de alta concurrencia: Admite una respuesta rápida en escenarios de alta concurrencia para garantizar el tiempo real y la eficiencia.
- Entrada adaptable: Ajusta dinámicamente la resolución para adaptarse a imágenes de entrada de distintos tamaños.
- Amplios recursos de código abiertoCódigo completo, pesos del modelo y conjuntos de datos de entrenamiento para facilitar la investigación y el desarrollo.
Principales ventajas de FG-CLIP 2
- Comprensión detallada a nivel de píxel: Puede identificar con precisión detalles como pelos, manchas, colores, expresiones y relaciones espaciales en imágenes, como distinguir entre distintas razas de gatos, determinar la posición de objetos dentro y fuera de la pantalla e incluso comprender las relaciones de oclusión en escenas complejas.
- Conocimientos bilingües de inglés y chinoEste modelo permite una comprensión detallada del chino y el inglés, llena el vacío existente en los modelos multimodales chinos y puede realizar con precisión tareas como la recuperación de textos largos en chino y la clasificación de regiones.
- Métodos de formación innovadoresEl objetivo de este proyecto es desarrollar una estrategia de formación en dos etapas para alinear globalmente la semántica gráfica y, a continuación, centrarse en la alineación local de los detalles; se combina con un sistema de optimización colaborativa en cinco dimensiones para mejorar la antiinterferencia y la robustez del modelo.
- Conjuntos de datos de alta calidad: Basado en el conjunto de datos FineHard de desarrollo propio, contiene miles de millones de pares de muestras gráficas en chino e inglés, así como decenas de millones de anotaciones de áreas locales y muestras difíciles de negativizar, lo que garantiza la captación precisa de los detalles por parte del modelo.
- Mecanismo de atención dinámicaEl enfoque inteligente en regiones clave de una imagen mejora la capacidad del modelo para procesar tareas visuales complejas.
- Arquitectura de alineación jerárquica: Combinación de macroescenas y microdetalles para mejorar progresivamente la comprensión del modelo y aumentar la precisión de la alineación visual y verbal.
- Optimización de las estrategias bilingües de sinergiaEquilibrar la comprensión del inglés y el chino para corregir los desequilibrios de rendimiento en tareas bilingües.
- Alta velocidad de respuesta simultáneaEstructura de doble torre explícita: se utiliza una estructura de doble torre explícita para dar soporte a una respuesta rápida en escenarios de alta concurrencia, garantizando el tiempo real y la eficiencia.
- Tamaño de entrada adaptableEl mecanismo de resolución dinámica permite al modelo manejar de forma adaptativa entradas de distintos tamaños, lo que aumenta su flexibilidad y adaptabilidad.
¿Cuál es la página web oficial de FG-CLIP 2?
- Página web del proyecto:: https://360cvgroup.github.io/FG-CLIP/
- Repositorio Github:: https://github.com/360CVGroup/FG-CLIP
- Documento técnico arXiv:: https://arxiv.org/pdf/2510.10921
Población para FG-CLIP 2
- Desarrollador de robótica domésticaLa necesidad de que los robots comprendan órdenes complejas en el entorno doméstico, la capacidad de FG-CLIP 2 de comprender el lenguaje visual de forma precisa puede mejorar significativamente la experiencia de interacción con el robot.
- Ingeniero de sistemas de seguridadEn el campo de la vigilancia de la seguridad, FG-CLIP 2 puede identificar y localizar objetivos con rapidez y precisión, mejorando la eficacia y fiabilidad de los sistemas de seguridad.
- Equipo técnico de comercio electrónico: FG-CLIP 2 puede optimizar las funciones de búsqueda y recomendación de productos, mejorar la experiencia del usuario, reducir el coste de la adaptación multilingüe y es adecuado para los equipos técnicos de las plataformas de comercio electrónico.
- Desarrollador de conducción autónomaEl sistema de conducción autónoma FG-CLIP 2 reconoce con precisión objetos y escenas en el entorno de la carretera, lo que aumenta la seguridad y fiabilidad del sistema.
- Analista de imagen médicaFG-CLIP 2: El FG-CLIP 2 puede ayudar a los médicos en el diagnóstico por imagen y mejorar la precisión y eficacia del diagnóstico, adecuado para profesionales del campo del análisis de imágenes médicas.
- Desarrolladores de tecnología educativaFG-CLIP 2: A la hora de desarrollar herramientas educativas inteligentes, FG-CLIP 2 puede enriquecer el contenido y la forma de la enseñanza aportando conocimientos relevantes basados en el contenido de las imágenes.
- Equipo de creación de contenidosEn la edición de imágenes y la producción de vídeo, el FG-CLIP 2 puede encontrar rápidamente las secuencias adecuadas basándose en descripciones de texto, lo que aumenta la eficacia creativa.
- Desarrollador de sistemas inteligentes de atención al clienteFG-CLIP 2 comprende el contenido de las imágenes subidas por los usuarios, proporciona respuestas y sugerencias más precisas y mejora la calidad del servicio al cliente.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...