FastVLM - Modelado de lenguaje visual de Apple
Últimos recursos sobre IAActualizado hace 7 meses Círculo de intercambio de inteligencia artificial 45.7K 00

Qué es FastVLM
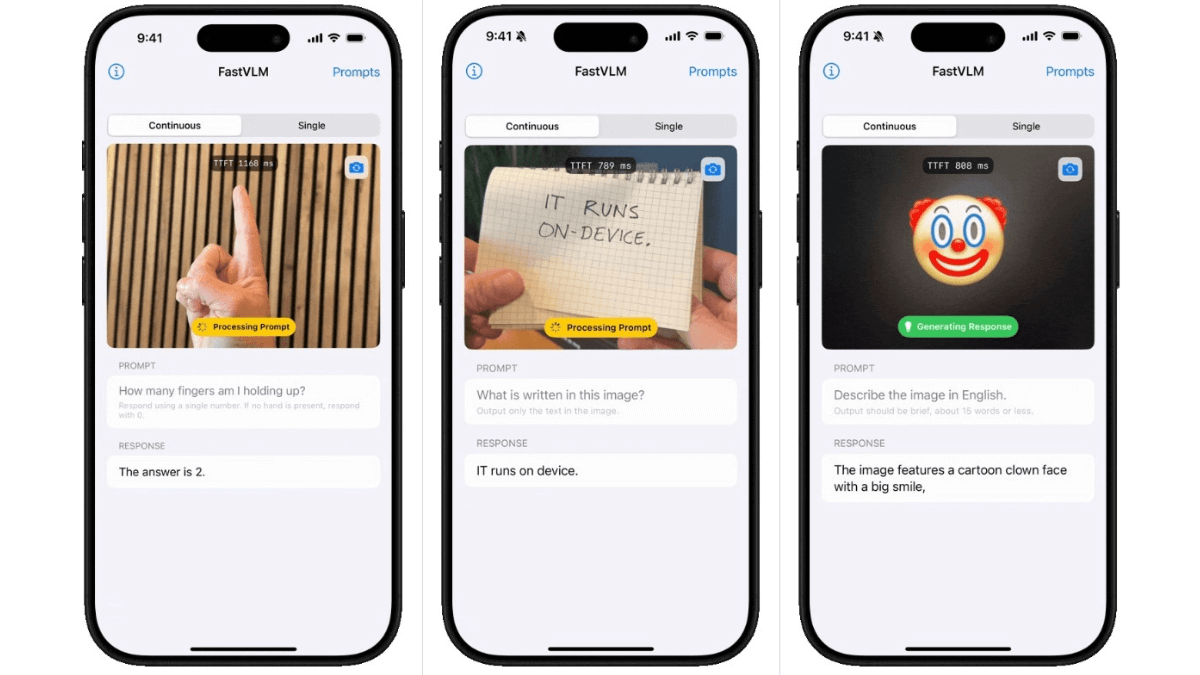
FastVLM (Fast Vision Language Model) es un eficaz modelo de lenguaje visual introducido por Apple. Con el codificador visual híbrido FastViTHD como núcleo, incorpora arquitecturas convolucionales y Transformer para reducir significativamente el número de tokens visuales, el tiempo de codificación y la latencia. Al procesar imágenes de alta resolución, la velocidad de codificación es 85 veces superior a la de modelos comparables, el tiempo hasta la generación del primer token (TTFT) mejora 3,2 veces y el tamaño del codificador visual es menor, lo que facilita su implantación en dispositivos móviles.
Características de FastVLM
- Procesamiento visual eficazEl sistema FastVLM reduce drásticamente el número de tokens visuales y mejora significativamente la velocidad de procesamiento de la información visual mediante un codificador visual híbrido que combina arquitecturas convolucionales y Transformer, y destaca especialmente en el procesamiento de imágenes de alta resolución.
- Interacción de baja latenciaEl tiempo de generación del primer token del modelo se acorta significativamente, y puede responder rápidamente a las entradas del usuario, lo que resulta adecuado para escenarios de interacción en tiempo real, como los asistentes gráficos móviles de preguntas y respuestas, para proporcionar información instantánea a los usuarios.
- Diseño ligeroEl tamaño significativamente reducido del codificador de visión facilita la implantación en dispositivos móviles y de inteligencia de borde, reduce los requisitos de hardware y mejora la portabilidad del modelo y la gama de aplicaciones.
- alta precisiónEn varias pruebas de referencia, el rendimiento de FastVLM es comparable al de modelos más grandes, y su capacidad para comprender y generar con precisión contenidos relacionados con imágenes garantiza la utilidad del modelo.
- Arquitectura simplificadaEl equilibrio entre el número de tokens y la resolución se consigue únicamente ajustando el tamaño de la imagen de entrada sin poda adicional de tokens, lo que simplifica el diseño del modelo y reduce la complejidad de desarrollo e implantación.
Principales ventajas de FastVLM
- Capacidad de procesamiento eficienteEl FastVLM utiliza un codificador visual híbrido, que combina arquitecturas convolucionales y de transformadores, para reducir significativamente el número de tokens visuales y mejorar la eficacia de la codificación, especialmente en el procesamiento de imágenes de alta resolución, con velocidades de codificación hasta 85 veces superiores a las de modelos comparables.
- Respuesta de baja latenciaEl tiempo hasta la primera generación de tokens (TTFT) se acorta drásticamente y la velocidad de respuesta es rápida, lo que lo hace adecuado para escenarios de interacción en tiempo real, como los asistentes gráficos móviles de preguntas y respuestas, capaces de dar respuestas rápidamente.
- Diseño ligeroEl tamaño considerablemente reducido del codificador de visión, que es 3,4 veces menor que el de modelos comparables, facilita la implantación en dispositivos móviles y dispositivos inteligentes periféricos, reduce los requisitos de hardware y mejora la portabilidad del modelo.
- alta precisiónEn varias pruebas de referencia, el rendimiento de FastVLM es comparable al de modelos más grandes, y su capacidad para comprender y generar con precisión contenidos relacionados con imágenes garantiza la utilidad del modelo.
- Diseño simplificadoEl equilibrio entre el número de tokens y la resolución se consigue únicamente ajustando el tamaño de la imagen de entrada sin poda adicional de tokens, lo que simplifica el diseño del modelo y reduce la complejidad de desarrollo e implantación.
¿Cuál es el sitio web oficial de FastVLM?
- Repositorio GitHub:: https://github.com/apple/ml-fastvlm
- Biblioteca de modelos HuggingFace:: https://huggingface.co/collections/apple/fastvlm-68ac97b9cd5cacefdd04872e
- Documento técnico arXiv:: https://www.arxiv.org/pdf/2412.13303
A quién va dirigido FastVLM
- Usuarios de dispositivos móvilesFastVLM es adecuado para usuarios de teléfonos inteligentes o tabletas que necesitan acceder rápidamente a información relacionada con las imágenes, como estudiantes, viajeros y personas que se desplazan al trabajo.
- Usuarios de wearables inteligentesPara quienes utilicen gafas inteligentes u otros dispositivos portátiles, FastVLM puede proporcionar alertas de escenas en tiempo real y asistencia informativa para mejorar la experiencia del usuario.
- Educadores y estudiantesEn el campo de la educación, FastVLM puede ayudar a profesores y alumnos a adquirir rápidamente conocimientos mediante cuestionarios de imágenes para facilitar la enseñanza y el aprendizaje.
- Empleados de la empresaEn situaciones de oficina, FastVLM puede ayudar a los empleados a procesar rápidamente texto y datos en imágenes para mejorar la eficiencia laboral de quienes necesitan trabajar en movimiento.
- Desarrollador tecnológicoPara los desarrolladores que trabajan en aplicaciones móviles o dispositivos inteligentes, FastVLM proporciona un modelo de lenguaje visual eficiente y ligero que puede utilizarse para crear una gran variedad de funciones de interacción inteligentes.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...