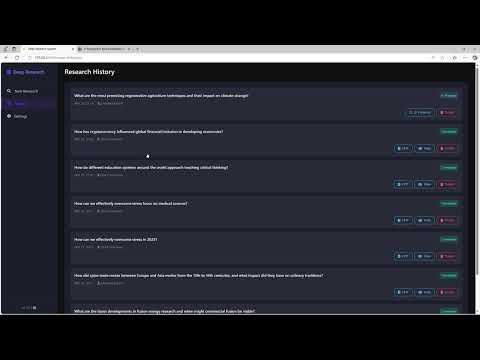
dsRAG: motor de recuperación de datos no estructurados y consultas complejas
Últimos recursos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 55.2K 00

Introducción general
dsRAG es un motor de recuperación de alto rendimiento diseñado para gestionar consultas complejas sobre datos no estructurados. Su rendimiento es especialmente bueno en la gestión de consultas complejas en textos densos, como informes financieros, documentos jurídicos y trabajos académicos. dsRAG emplea tres enfoques clave para mejorar el rendimiento: segmentación semántica, autogeneración contextual y extracción de segmentos relevantes. Estos enfoques permiten a dsRAG alcanzar una precisión significativamente mayor que la línea de base tradicional de RAG en tareas complejas de cuestionario abierto. Además, dsRAG admite una amplia gama de opciones de configuración que pueden personalizarse en función de las necesidades del usuario. Su diseño modular permite a los usuarios integrar fácilmente distintos componentes, como bases de datos vectoriales, modelos de incrustación y reordenadores, para lograr resultados de recuperación óptimos.
En comparación con las líneas de base RAG (Retrieval-Augmented Generation) tradicionales, dsRAG logra índices de precisión significativamente más altos en tareas complejas de cuestionario abierto. Por ejemplo, en la prueba de referencia FinanceBench, dsRAG alcanza una precisión de 96,61 TP3T, frente a los 321 TP3T de la línea de base RAG tradicional. dsRAG mejora significativamente el rendimiento de la recuperación mediante métodos clave como la segmentación semántica, el contexto automático y la extracción de segmentos relevantes.

Lista de funciones
- segmentación semántica: Utiliza LLM para segmentar documentos con el fin de mejorar la precisión de la recuperación.
- Generación automática de contextosGeneración de cabeceras de bloque con contexto a nivel de documento y párrafo para mejorar la calidad de la incrustación.
- Extracción de segmentos relevantes: Combina de forma inteligente bloques de texto relacionados en el momento de la consulta para generar párrafos más largos.
- Soporte de múltiples bases de datos vectorialespor ejemplo, BasicVectorDB, WeaviateVectorDB, ChromaDB, etc.
- Compatible con varios modelos integradospor ejemplo, OpenAIEmbedding, CohereEmbedding, etc.
- Compatible con múltiples reordenadorespor ejemplo, CohereReranker, VoyageReranker, etc.
- Base de conocimientos persistenteSoporte para la persistencia de objetos de bases de conocimiento en disco para su posterior carga y consulta.
- Compatibilidad con múltiples formatos de documentoSoporte para PDF, Markdown y otros formatos de documento, como análisis sintáctico y procesamiento.
Utilizar la ayuda
montaje
Para instalar el paquete Python para dsRAG, puede ejecutar el siguiente comando:
pip install dsrag
Asegúrate de tener las claves API para OpenAI y Cohere y establécelas como variables de entorno.
Inicio rápido
Puede utilizar la funcióncreate_kb_from_filecrea una nueva base de conocimientos directamente a partir de un archivo:
from dsrag.create_kb import create_kb_from_file
file_path = "dsRAG/tests/data/levels_of_agi.pdf"
kb_id = "levels_of_agi"
kb = create_kb_from_file(kb_id, file_path)
Los objetos de la base de conocimientos se guardan automáticamente en el disco, por lo que no es necesario guardarlos explícitamente.
Ahora, puedes hacerte una mejor idea de lo que ocurre con sukb_idCargue la base de conocimientos y utilice la funciónquerySe consultan los métodos:
from dsrag.knowledge_base import KnowledgeBase
kb = KnowledgeBase("levels_of_agi")
search_queries = ["What are the levels of AGI?", "What is the highest level of AGI?"]
results = kb.query(search_queries)
for segment in results:
print(segment)
Personalización básica
Puede personalizar la configuración de la base de conocimientos, por ejemplo, utilizando sólo OpenAI:
from dsrag.llm import OpenAIChatAPI
from dsrag.reranker import NoReranker
llm = OpenAIChatAPI(model='gpt-4o-mini')
reranker = NoReranker()
kb = KnowledgeBase(kb_id="levels_of_agi", reranker=reranker, auto_context_model=llm)
A continuación, utiliceadd_documentpara añadir un documento:
file_path = "dsRAG/tests/data/levels_of_agi.pdf"
kb.add_document(doc_id=file_path, file_path=file_path)
construya
El objeto de la base de conocimientos acepta documentos (en forma de texto sin procesar) y realiza sobre ellos el chunking y el embedding, así como otras operaciones de preprocesamiento. Cuando se introduce una consulta, el sistema realiza la búsqueda vectorial en la base de datos, la reordenación y la extracción de segmentos relevantes, y finalmente devuelve el resultado.
Los objetos de la base de conocimientos son persistentes por defecto y su configuración completa se guarda como un archivo JSON para facilitar su reconstrucción y actualización.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...