DreamOmni2 - Modelo multimodal de edición y generación de imágenes de IA de código abierto de la HKUST
Últimos recursos sobre IAPublicado hace 5 meses Círculo de intercambio de inteligencia artificial 34.5K 00

Qué es DreamOmni2
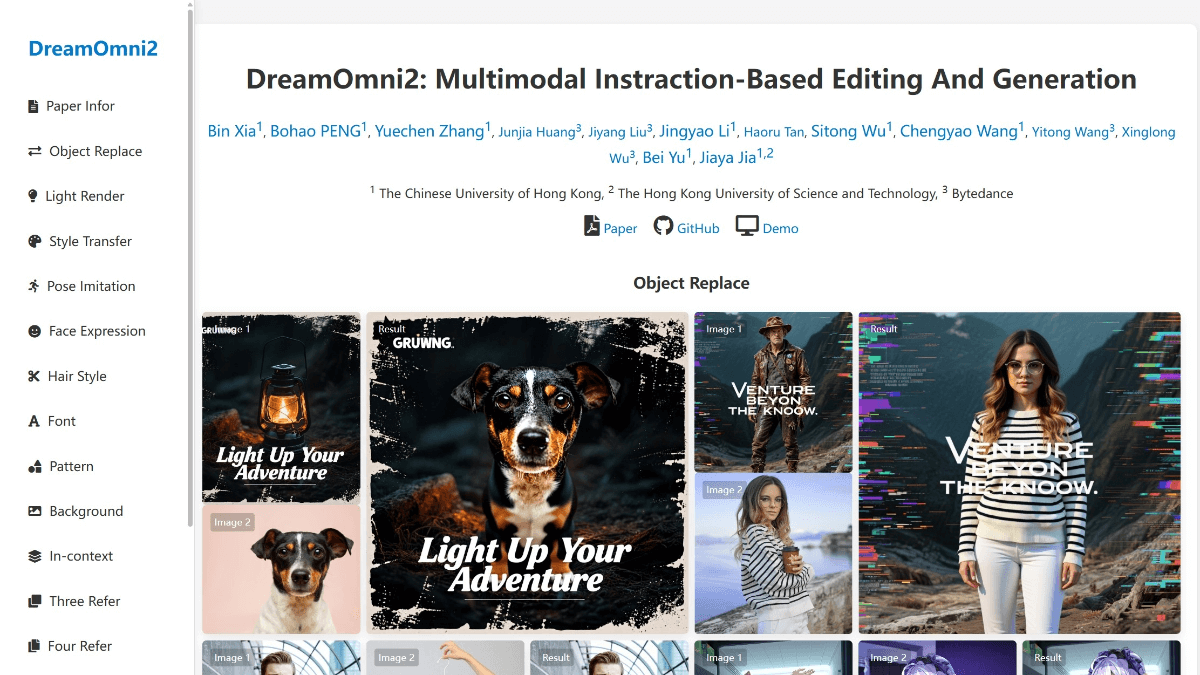
DreamOmni2 es un modelo multimodal de edición y generación de imágenes de IA de código abierto creado por el equipo de Jiajia en la HKUST. Puede procesar simultáneamente comandos de texto e imagen y admitir múltiples imágenes de referencia, lo que proporciona a los creadores métodos de creación más flexibles. El modelo se entrena mediante un proceso de síntesis de datos en tres etapas, que entrena conjuntamente el modelo de generación/edición y el modelo de lenguaje visual, manteniendo eficazmente la identidad del sujeto de la imagen.DreamOmni2 obtiene buenos resultados en tareas de edición y generación de comandos multimodales, superando a los actuales modelos de código abierto y comparándose o superando a los modelos comerciales en algunos aspectos. Puede utilizarse en una gran variedad de escenarios, como la fotografía de productos, el flujo de trabajo de diseño, la edición de retratos y la pintura creativa.
Características de DreamOmni2
- procesamiento multimodal de instrucciones: Admite comandos de texto e imagen para trabajar tanto con objetos concretos como con conceptos abstractos como materiales, texturas, estilos, etc., proporcionando a los creadores formas más ricas de expresarse.
- Cartas multirreferencia: La posibilidad de combinar varias imágenes de referencia para su edición y generación proporciona a los creadores una mayor flexibilidad para satisfacer necesidades creativas complejas y variadas.
- Síntesis de datos y formaciónSe utiliza un proceso de síntesis de datos en tres etapas, que incluye métodos de mezcla de características, modelos de edición y extracción para generar datos de entrenamiento, y también se diseñan esquemas de codificación de índices y compensación de codificación de posiciones para evitar la confusión de píxeles en entradas de imágenes múltiples y mejorar el efecto de entrenamiento y la calidad de generación del modelo.
- formación conjuntaEl entrenamiento conjunto de un modelo generativo/de edición con un modelo de lenguaje visual (VLM) para manejar mejor órdenes complejas permite al modelo comprender y ejecutar con mayor precisión las órdenes multimodales del usuario.
- Mantenimiento de la coherencia de la identidadEn el proceso de edición, las características de identidad del sujeto de la imagen pueden mantenerse eficazmente para garantizar la coherencia entre la imagen editada y el sujeto original, y evitar la pérdida o confusión de las características del sujeto causadas por la edición.
- Ventajas de rendimientoEn tareas de edición y generación de comandos multimodales, DreamOmni2 supera con creces a los actuales modelos SOTA de código abierto, e incluso iguala o supera a los modelos comerciales en algunos aspectos, proporcionando a los usuarios resultados de edición y generación de imágenes de mayor calidad.
- Código abierto y facilidad de usoEl código, los pesos de los modelos y los conjuntos de datos de entrenamiento están disponibles de forma gratuita en GitHub y Hugging Face, y admiten la ejecución local, lo que facilita a los usuarios realizar inferencia local en GPU compatibles con CUDA con suficiente memoria de vídeo, reduciendo el umbral de uso y mejorando la accesibilidad de los modelos.
Principales ventajas de DreamOmni2
- Comprensión de la instrucción multimodalCapacidad para procesar comandos tanto de texto como de imagen, para comprender y realizar con precisión tareas de edición complejas, como la modificación de materiales, texturas, estilos y otros conceptos abstractos.
- Soporte de gráficos multirreferencia: Puede combinarse con múltiples imágenes de referencia para su edición y generación, lo que proporciona a los creadores una mayor flexibilidad para satisfacer diversas necesidades creativas.
- Mantenimiento de la coherencia de la identidadEn el proceso de edición, las características de identidad del sujeto de la imagen se mantienen de forma efectiva para garantizar que la imagen editada sea altamente coherente con el sujeto original y evitar la pérdida o confusión de las características del sujeto.
- Mecanismo conjunto de formaciónEl entrenamiento conjunto de modelos generativos/de edición con modelos de lenguaje visual mejora la comprensión y ejecución de órdenes complejas y genera imágenes que se ajustan mejor a la intención del usuario.
- rendimiento superior: Supera significativamente a los modelos de código abierto actuales, y en algunos aspectos incluso supera a los modelos comerciales, en tareas de edición y generación de comandos multimodales, proporcionando resultados de edición y generación de imágenes de alta calidad.
¿Cuál es el sitio web oficial de DreamOmni2?
- Página web del proyecto:: https://pbihao.github.io/projects/DreamOmni2/index.html
- Repositorio Github:: https://github.com/dvlab-research/DreamOmni2
- Documento técnico arXiv:: https://arxiv.org/pdf/2510.06679
- Experiencia Dirección:: https://huggingface.co/spaces/wcy1122/DreamOmni2-Gen
¿A quién va dirigido DreamOmni2?
- Diseñador creativo: Puede materializar rápidamente ideas de diseño, generar múltiples estilos de borradores de diseño y mejorar la eficacia del trabajo.
- camarógrafosPermite el posprocesamiento de fotografías de productos para mejorar el efecto visual de los productos y satisfacer las necesidades de los distintos clientes.
- artistasCrea dibujos y pinturas rápidos, explorando diferentes estilos e ideas para inspirar el arte.
- agencia de publicidad: Genere rápidamente materiales publicitarios para satisfacer los requisitos de diferentes temas y estilos publicitarios.
- Creadores individualesCreatividad: Aplica fácilmente ideas creativas y produce contenidos de imagen personalizados para satisfacer las necesidades creativas individuales.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...