
Un artículo claro Destilación del Conocimiento (Destilación): que el "pequeño modelo" también pueda tener "gran sabiduría".
Base de conocimientos de IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 53.2K 00

La destilación de conocimientos es una técnica de aprendizaje automático cuyo objetivo es transferir el aprendizaje de un modelo grande preentrenado (es decir, un "modelo maestro") a un "modelo alumno" más pequeño. Las técnicas de destilación pueden ayudarnos a desarrollar modelos generativos más ligeros para su uso en ámbitos como el diálogo inteligente y la creación de contenidos.
más cercano (de lugares) Destilación Esta palabra se ve muy a menudo.
El equipo de DeepSeek, que dio la campanada hace dos días, publicó el DeepSeek-R1, cuyo gran modelo con 670B parámetros migró con éxito sus capacidades a un modelo ligero con 7B parámetros mediante técnicas de aprendizaje por refuerzo y destilación.
El modelo destilado supera a los modelos tradicionales del mismo tamaño e incluso se acerca al mejor modelo pequeño de OpenAI, OpenAI-o1-mini.
En el campo de la inteligencia artificial, los grandes modelos lingüísticos (por ejemplo, GPT-4, DeepSeek-R1 ) ha demostrado excelentes capacidades de razonamiento y generación con cientos de miles de millones de parámetros. Sin embargo, sus enormes requisitos computacionales y elevados costes de despliegue limitan seriamente su aplicación en escenarios como los dispositivos móviles y la computación de borde.
¿Cómo comprimir el tamaño del modelo sin perder rendimiento?Destilación de conocimientos(Destilación del Conocimiento) es una técnica clave para resolver este problema.
1. ¿Qué es la destilación de conocimientos?
La destilación de conocimientos es una técnica de aprendizaje automático cuyo objetivo es transferir el aprendizaje de un modelo grande preentrenado (es decir, un "modelo maestro") a un "modelo alumno" más pequeño.
En el aprendizaje profundo, se utiliza como una forma de compresión de modelos y transferencia de conocimientos, especialmente para redes neuronales profundas a gran escala.
La esencia de la destilación de conocimientos esmigración de conocimientosque imita la distribución de salida del modelo del profesor para que el modelo del alumno herede su capacidad de generalización y su lógica de razonamiento.
- Modelo de profesor(Modelo de profesor): suele ser un modelo complejo con un gran número de parámetros y suficiente entrenamiento (por ejemplo, DeepSeek-R1), cuya salida contiene no sólo los resultados de la predicción, sino también implícitamente la información de similitud entre categorías.
- Modelos de estudiantes(Modelo del alumno: Un modelo pequeño y compacto con menos parámetros que permite la transferencia de competencias al coincidir con los objetivos blandos del modelo del profesor.
A diferencia del aprendizaje profundo tradicional, en el que el objetivo es entrenar una red neuronal artificial para que haga predicciones que se parezcan más a las salidas de muestra proporcionadas en el conjunto de datos de entrenamiento, la destilación de conocimientos requiere que el modelo del alumno no solo se ajuste a la respuesta correcta (un objetivo difícil), sino que también aprenda la "lógica de pensamiento" del modelo del profesor. -es decir, la salida deldistribución de probabilidad(objetivo blando).
Por ejemplo, en la tarea de clasificación de imágenes, el profesor modelo no sólo indicará "esta imagen es un gato" (90% confianza), sino que también dará posibilidades como "parece un zorro" (5%), "otros animales " (5%) y otras posibilidades.
Estos valores de probabilidad son como los "puntos fáciles" que marca el profesor al corregir las hojas de examen. Al captar las correlaciones (por ejemplo, los gatos y los zorros tienen orejas puntiagudas y características del pelo similares), el modelo de alumno acabará aprendiendo a ser más flexible en su capacidad de discriminación en lugar de memorizar mecánicamente respuestas estándar.
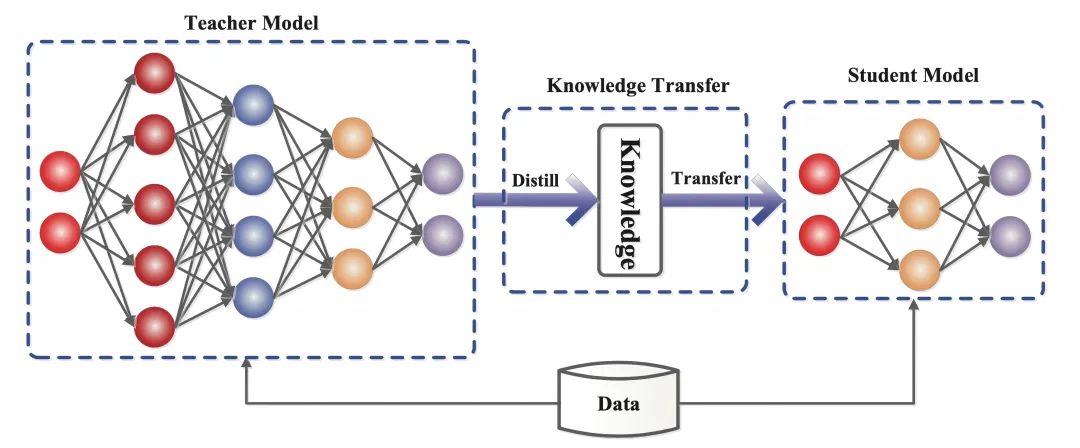
2. Conocimiento del funcionamiento de la destilación
En el artículo de 2015 Distilling the Knowledge in a Neural Network, que propone dividir el entrenamiento en dos fases con propósitos diferentes, los autores establecen una analogía: mientras que la forma larvaria de muchos insectos está optimizada para extraer energía y nutrientes del entorno, la forma adulta es completamente diferente, optimizada para viajar y reproducirse, mientras que el aprendizaje profundo tradicional utiliza los mismos modelos en las fases de entrenamiento y despliegue, aunque tengan requisitos diferentes.
La interpretación de "conocimiento" en los documentos también varía:
Antes de la publicación del artículo, se tendía a equiparar los conocimientos del modelo de entrenamiento con los valores de los parámetros aprendidos, lo que hacía difícil ver cómo se podían mantener los mismos conocimientos cambiando la forma del modelo.
Una visión más abstracta del conocimiento es que se trata de algo aprendido.Asignación del vector de entrada al vector de salida.
Las técnicas de destilación de conocimientos no sólo reproducen los resultados de los modelos de los profesores, sino que también imitan sus "procesos de pensamiento". En la era de los LLM, la destilación de conocimientos permite transferir cualidades abstractas como el estilo, la capacidad de razonamiento y la alineación con las preferencias y valores humanos.
La realización de la destilación de conocimientos puede dividirse en tres etapas fundamentales:
2.1 Generación de objetivos blandos: "fuzzificación" de las respuestas
El modelo de profesor se pasaAlta temperatura SoftmaxLa tecnología transforma las respuestas "en blanco y negro" en "pistas difusas" que contienen información detallada.
A medida que aumenta la temperatura (Temperatura) (por ejemplo, T=20), la distribución de probabilidad de la salida del modelo es más suave.
Por ejemplo, la sentencia original "gato (90%), zorro (5%)".
Puede convertirse en "Gato (60%), Zorro (20%), Otro (20%)".
Este ajuste obliga a los modelos de los alumnos a centrarse en las correlaciones entre categorías (por ejemplo, los gatos y los zorros tienen orejas de forma similar) en lugar de memorizar mecánicamente las etiquetas.
2.2 Diseño de la función objetivo: equilibrio entre objetivos blandos y duros
Los objetivos de aprendizaje del modelo de estudiante son dos:
- Imitar la lógica del pensamiento del profesor(Objetivo blando): aprendizaje de las relaciones entre clases mediante el emparejamiento de las distribuciones de probabilidad de alta temperatura de los profesores.
- Recuerda la respuesta correcta.(Objetivo difícil): Garantizar que no disminuya la precisión básica.
La función de pérdida del modelo del alumno es una combinación ponderada de objetivos blandos y duros, y los pesos de ambos deben ajustarse dinámicamente.
Por ejemplo, al asignar ponderaciones de 70% a los objetivos blandos y 30% a los duros, es similar a que los alumnos dediquen 70% a estudiar las soluciones del profesor y 30% a consolidar las respuestas estándar, logrando en última instancia un equilibrio entre flexibilidad y precisión.
2.3 Regulación dinámica de los parámetros de temperatura, control de la "granularidad de transferencia" de conocimientos
El parámetro de la temperatura es el "botón de dificultad" de la destilación intelectual:
- Modo de alta temperatura(por ejemplo, T=20): las respuestas son muy ambiguas y adecuadas para transmitir asociaciones complejas (por ejemplo, distinguir entre diferentes razas de gatos).
- modo de baja temperatura(por ejemplo, T = 1): las respuestas se aproximan a la distribución original y son adecuadas para tareas sencillas (por ejemplo, reconocimiento de números).
- estrategia dinámica: Absorción exhaustiva de conocimientos con altas temperaturas al principio, y enfriamiento después para centrarse en las características clave.
Por ejemplo, las tareas de reconocimiento de voz requieren temperaturas más bajas para mantener la precisión. Este proceso es similar al de un profesor que ajusta la profundidad de la instrucción al nivel del alumno, desde la heurística hasta la realización de exámenes.
3. Importancia de la destilación de conocimientos
Los modelos con mejor rendimiento para una tarea determinada suelen ser demasiado grandes, lentos o caros para la mayoría de los casos de uso en el mundo real, pero su excelente rendimiento se debe a su tamaño y a su capacidad de preentrenamiento en grandes cantidades de datos de entrenamiento.
En cambio, los modelos más pequeños, aunque más rápidos y menos exigentes desde el punto de vista computacional, son menos precisos, menos refinados y tienen menos conocimientos que los modelos más grandes con más parámetros.
Aquí es donde entra en juego, por ejemplo, el valor de la aplicación de la destilación de conocimientos:
El gran modelo de 670B parámetros de DeepSeek-R1 migra sus capacidades a un modelo ligero de 7B parámetros mediante una técnica de destilación del conocimiento: el DeepSeek-R1-7B, que supera en todos los aspectos a los modelos sin inferencia como el GPT-4o-0513.DeepSeek-R1-14B supera al QwQ-32BPreview en todas las métricas de evaluación, mientras que el DeepSeek-R1-32B y DeepSeek-R1-70B superan significativamente a o1-mini en la mayoría de los puntos de referencia.
Estos resultados demuestran el gran potencial de la destilación. La destilación de conocimientos se ha convertido en una importante herramienta técnica.
En el campo del procesamiento del lenguaje natural, muchos institutos de investigación y empresas utilizan técnicas de destilación para comprimir grandes modelos lingüísticos en versiones más pequeñas para tareas como la traducción, los sistemas de diálogo y la clasificación de textos.
Por ejemplo, los grandes modelos, una vez destilados, pueden ejecutarse en dispositivos móviles para ofrecer servicios de traducción en tiempo real sin depender de potentes recursos informáticos en la nube.
El valor de la destilación del conocimiento es aún más significativo en IoT y edge computing. Mientras que los grandes modelos tradicionales suelen requerir el soporte de potentes clústeres de GPU, los modelos pequeños se destilan para poder ejecutarse en microprocesadores o dispositivos integrados con un consumo de energía mucho menor.
Esta tecnología no sólo reduce drásticamente los costes de implantación, sino que también permite un mayor uso de los sistemas inteligentes en ámbitos como la sanidad, la conducción autónoma y los hogares inteligentes.
En el futuro, el potencial de aplicación de la destilación de conocimientos será aún más amplio. Con el desarrollo de la IA generativa, la tecnología de destilación puede ayudarnos a desarrollar modelos generativos más ligeros para el diálogo inteligente, la creación de contenidos y otros ámbitos.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...