DINOv3 - Modelo base de visión autosupervisada de próxima generación de Meta AI
Últimos recursos sobre IAActualizado hace 7 meses Círculo de intercambio de inteligencia artificial 53.8K 00

¿Qué es DINOv3?
DINOv3 Sí Meta IA DINOv3 es un modelo base de visión autosupervisada de nueva generación que adopta el paradigma del aprendizaje autosupervisado para aprender las características de las imágenes sin datos de etiquetado. Al mejorar la preparación de los datos e introducir el anclaje Gram, se resuelve el problema de la degradación de características y se mejora la capacidad de generalización.DINOv3 proporciona dos arquitecturas de red troncal, ViT y ConvNeXt, de las cuales ViT-7B es la versión más grande en la actualidad, que contiene 6.700 millones de parámetros. El modelo puede generar representaciones de rasgos densos de alta calidad que captan con precisión las relaciones locales y la información espacial de las imágenes. Ofrece buenos resultados en diversas tareas visuales, como la clasificación de imágenes, la detección de objetivos, la segmentación semántica, etc., y puede superar a muchos modelos profesionales sin necesidad de realizar ajustes específicos para cada tarea.
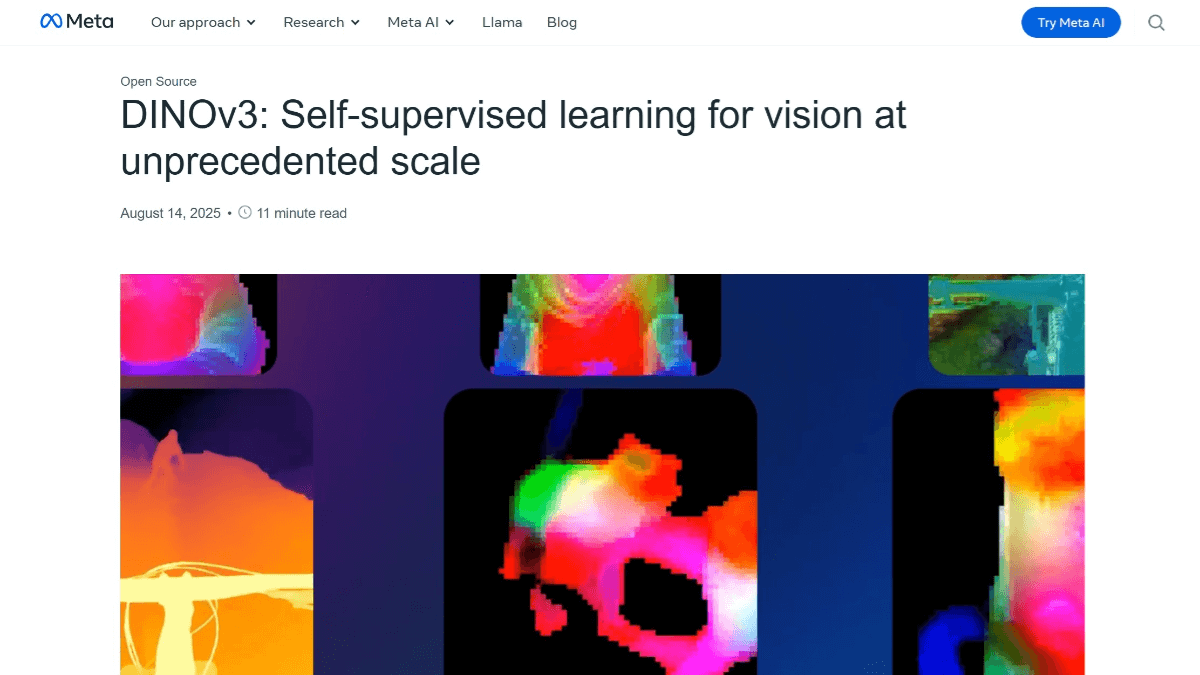
Características de DINOv3
- Capacidad de aprendizaje autosupervisadoEl modelo puede aprender características de la imagen sin datos etiquetados, y la capacidad de generalización del modelo se mejora con la preparación de los datos y la introducción del anclaje Gram para resolver el problema de la degradación de las características en el entrenamiento a largo plazo.
- Múltiples arquitecturas de red troncal: Existen dos arquitecturas de red troncal, ViT y ConvNeXt, para satisfacer diferentes necesidades informáticas, siendo ViT-7B la versión más grande hasta la fecha, con 6.700 millones de parámetros.
- Representación de características de alta calidadLa tecnología de la imagen: puede generar representaciones de rasgos densos de alta calidad que capturan con precisión las relaciones locales y la información espacial de las imágenes para una amplia gama de tareas visuales.
- Versatilidad multitarea: obtiene buenos resultados en tareas como la clasificación de imágenes, la detección de objetivos, la segmentación semántica, etc., superando a muchos modelos profesionales sin un ajuste fino específico de la tarea y reduciendo significativamente los costes de inferencia.
- Extracción de características de alta resoluciónPermite la extracción de características de alta resolución para situaciones que requieren características de alta precisión, como el análisis de imágenes médicas y la vigilancia del medio ambiente.
Principales ventajas de DINOv3
- Potente aprendizaje autosupervisadoNo requiere una gran cantidad de datos etiquetados y consigue un aprendizaje eficaz mediante un innovador mecanismo de autosupervisión que resuelve el problema de la degradación de las características y mejora la capacidad de generalización del modelo.
- Opciones de arquitectura flexiblesLas arquitecturas de red troncal ViT y ConvNeXt están disponibles para satisfacer diferentes requisitos de recursos informáticos y tareas, equilibrando rendimiento y eficiencia.
- Representación de características de alta calidadLas características generadas capturan con precisión las relaciones locales de la imagen y la información espacial, y son adecuadas para una amplia gama de tareas visuales con un rendimiento excelente.
- Versatilidad multitareaSupera a los modelos profesionales sin ajuste específico en tareas como la clasificación de imágenes, la detección de objetivos, la segmentación semántica, etc., reduciendo los costes de desarrollo.
- Extracción de características de alta resoluciónLa función de extracción de características de alta resolución es adecuada para el análisis de imágenes médicas, la vigilancia del medio ambiente y otras situaciones que requieren una gran precisión.
- Código abierto y facilidad de uso: Código y modelos de código abierto, compatibilidad con las bibliotecas Hugging Face Hub y Transformers, facilidad para iniciarse rápidamente en el desarrollo de aplicaciones.
¿Cuál es la página web oficial de DINOv3?
- Página web del proyecto:: https://ai.meta.com/blog/dinov3-self-supervised-vision-model/
- Biblioteca de modelos HuggingFace:: https://huggingface.co/docs/transformers/main/en/model_doc/dinov3
- Documentos técnicos:: https://ai.meta.com/research/publications/dinov3/
Para quién es DINOv3
- Investigadores en visión por ordenadorDINOv3 proporciona potentes capacidades de aprendizaje autosupervisado y representaciones de características de alta calidad adecuadas para los profesionales dedicados a la investigación de tareas visuales como la clasificación de imágenes, la detección de objetivos y la segmentación semántica.
- Desarrollador de aprendizaje profundoEl código fuente abierto y los modelos preentrenados hacen que DINOv3 sea ideal para que los desarrolladores de aprendizaje profundo creen y desplieguen rápidamente aplicaciones de visión para escenarios que requieren un desarrollo y una optimización eficientes.
- Especialista en imagen médicaLa capacidad de extracción de características de alta resolución tiene un gran potencial en el campo del análisis de imágenes médicas para tareas de diagnóstico médico que requieren características de alta precisión, como el análisis de rayos X, TC y RM.
- Vigilancia medioambiental y profesionales de los Sistemas de Información Geográfica (SIG)DINOv3: DINOv3 puede utilizarse para tareas de vigilancia del medio ambiente, como el análisis de imágenes por satélite y la vigilancia de la deforestación, proporcionando apoyo técnico a los trabajos relacionados con los SIG.
- Ingeniero de visión robótica: Las características de visión de alta precisión y la versatilidad multitarea de DINOv3 lo hacen ideal para sistemas de visión robótica destinados a tareas de percepción visual en entornos complejos, como los robots de exploración de Marte.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...