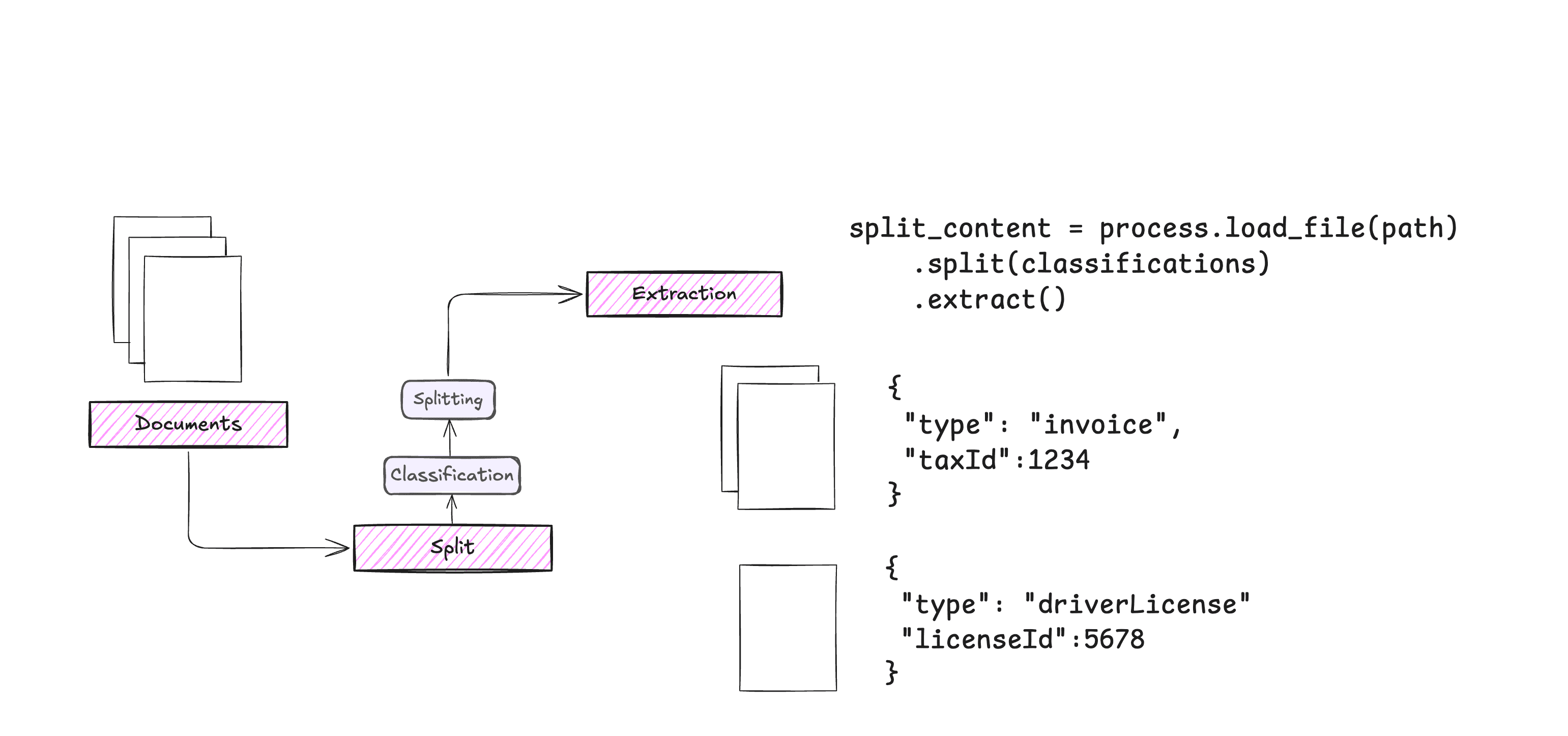
DiaMoE-TTS - Marco de síntesis del habla multidialectal de código abierto de Tsinghua y Giant Network
Últimos recursos sobre IAActualizado hace 5 meses Círculo de intercambio de inteligencia artificial 35.3K 00

¿Qué es DiaMoE-TTS?
DiaMoE-TTS es un marco de síntesis del habla multidialectal de código abierto desarrollado conjuntamente por la Universidad de Tsinghua y Giant Network, basado en el Alfabeto Fonético Internacional (AFI), para resolver los problemas de escasez de datos dialectales, incoherencia ortográfica y cambios fonológicos complejos. Elimina las diferencias entre dialectos gracias a una representación de fonemas unificada y estandarizada en el front-end del IPA, y adopta una arquitectura de Mezcla de Expertos (MoE, Mixture-of-Experts) sensible a los dialectos para permitir que distintas redes de expertos se centren en el aprendizaje de las características de los distintos dialectos, preservando el timbre y el ritmo únicos de cada dialecto. El marco se basa en F5-TTS Se construye introduciendo adaptadores de bajo rango (LoRA) y adaptadores condicionales para lograr una migración dialectal eficiente desde el punto de vista de los parámetros, y sólo es necesario ajustar un pequeño número de parámetros para completar la expansión dialectal. El entrenamiento se basa por completo en datos de código abierto, lo que elimina la necesidad de utilizar costosas etiquetas manuales y reduce el umbral técnico. Los experimentos demuestran que DiaMoE-TTS genera un habla natural y expresiva, logrando un rendimiento de muestra cero para dialectos desconocidos y dominios especializados (por ejemplo, la Ópera de Pekín) utilizando sólo unas pocas horas de datos.DiaMoE-TTS es compatible con 11 dialectos y el mandarín, y puede ampliarse a las lenguas europeas.
DiaMoE-TTS Características funcionales
- Interfaz unificada IPAAdoptar el Alfabeto Fonético Internacional (AFI) como sistema de entrada, construir un inventario de fonemas altamente escalable, soportar la anotación de fonemas para múltiples dialectos y lenguas, eliminar las diferencias entre dialectos y garantizar la coherencia de los modelos y la capacidad de generalización.
- Arquitectura de ME dialectalSe presenta la arquitectura Mixture-of-Experts para el conocimiento de dialectos, en la que diferentes redes de expertos se centran en el aprendizaje de las características de los distintos dialectos, y un mecanismo dinámico de gating selecciona automáticamente las rutas de expertos más adecuadas, preservando el timbre y el ritmo únicos de cada dialecto.
- Adaptación dialectal con pocos recursosA continuación se presenta un ejemplo de cómo lograr una rápida adaptación de dialectos de escasos recursos: adoptando una estrategia eficaz de migración de parámetros, la ampliación de dialectos puede llevarse a cabo ajustando sólo un pequeño número de parámetros, y la columna vertebral puede mantenerse congelada con el módulo MoE, evitando olvidar los conocimientos existentes.
- Métodos de formación multietapaEl modelo está diseñado para mejorar gradualmente el rendimiento del modelo y adaptarse a la diversidad dialectal, incluyendo la inicialización de la migración IPA, el co-entrenamiento multidialectal, la mejora de los expertos dialectales y las etapas de adaptación rápida con pocos recursos.
- Unidad de Datos AbiertosLa tecnología de síntesis de voz de la serie ASR se basa en datos de ASR de código abierto, lo que elimina la necesidad de un costoso etiquetado manual del habla, reduce el umbral técnico y permite una síntesis del habla escalable y basada en datos abiertos.
- Capacidad de generalización eficazEl sistema puede lograr una gran precisión de pronunciación en dialectos con pocos recursos, por ejemplo, 91,71 TP3T para el hakka, y pruebas de rendimiento con muestra cero para dialectos desconocidos y dominios especializados (por ejemplo, la Ópera de Pekín).
- Escenarios de aplicación enriquecidosAdmite la síntesis de voz de varios dialectos chinos y del mandarín, y puede ampliarse a las lenguas europeas. Es aplicable a los ámbitos de la protección de dialectos, la cultura y el entretenimiento, y proporciona apoyo técnico para la herencia de dialectos y el desarrollo de la industria cultural.
- cadena de herramientas completaProporcionar scripts de entrenamiento e inferencia, modelos preentrenados y front-ends IPA para conjuntos de datos de código abierto, con el fin de facilitar a los usuarios la puesta en marcha y su rápida aplicación, y acelerar el proceso de investigación y desarrollo.
Principales ventajas de DiaMoE-TTS
- Basado en datos y de código abiertoEl entrenamiento basado íntegramente en datos de código abierto elimina la necesidad de un costoso etiquetado manual del habla, lo que reduce el umbral técnico y el coste.
- Capacidad de generalización eficazEl resultado es una mayor precisión de la pronunciación en dialectos con pocos recursos y pruebas de rendimiento con muestra cero en dialectos desconocidos y ámbitos especializados (por ejemplo, la ópera de Pekín).
- Conservación y expansión dialectalesEs compatible con una amplia gama de dialectos chinos y mandarín, y puede ampliarse a las lenguas europeas, lo que supone un gran apoyo a la conservación de los dialectos y la diversidad lingüística.
- Adaptación y migración rápidasLa ampliación del nuevo dialecto se realiza adoptando una eficaz estrategia de migración de parámetros, que sólo requiere ajustar un pequeño número de parámetros para adaptarse rápidamente al nuevo dialecto.
- síntesis del habla naturalEl habla generada es natural y expresiva, y los resultados experimentales demuestran que sobresale en calidad del habla y expresividad.
¿Cuál es la página web oficial de DiaMoE-TTS?
- Repositorio GitHub:: https://github.com/GiantAILab/DiaMoE-TTS
- Biblioteca de modelos HuggingFace:: https://huggingface.co/RICHARD12369/DiaMoE_TTS
- Documento técnico arXiv:: https://www.arxiv.org/pdf/2509.22727
Personas para las que está indicado DiaMoE-TTS
- investigador dialectalObjetivo: Proporcionar herramientas eficaces para el estudio de las características fonológicas y la evolución fonológica de los dialectos chinos y otras lenguas, y ayudar a la investigación lingüística.
- Desarrollador de síntesis de vozEl objetivo es facilitar a los desarrolladores la rápida creación y optimización de sistemas de síntesis del habla multidialectales.
- Preservacionistas dialectalesContribuir al Proyecto de Preservación de Dialectos, que fomenta la diversidad lingüística grabando y transmitiendo dialectos en peligro mediante la tecnología de síntesis de voz.
- Profesionales de la cultura y el espectáculo: En los ámbitos del cine, la televisión, la radiodifusión y los juegos, puede utilizarse para producir contenidos vocales con características locales y potenciar la expresión cultural.
- educadorEl objetivo: desarrollar recursos de enseñanza de dialectos para ayudar a los estudiantes a aprender y comprender diferentes dialectos y promover la educación lingüística.
- entusiasta de la tecnología: Las personas interesadas en la síntesis de voz y la tecnología de inteligencia artificial pueden aprender y explorar a través del código fuente abierto y la documentación.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...