
Diseño y aplicación de DeepSearch y DeepResearch
Base de conocimientos de IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 62.4K 00


Sólo estamos en febrero y la búsqueda profunda ya se perfila como el nuevo estándar de búsqueda para 2025. Gigantes como Google y OpenAI han presentado sus productos de "Búsqueda Profunda" en un esfuerzo por adelantarse a la ola tecnológica. (También estamos orgullosos de haber lanzado nuestro producto de código abiertonode-deepresearch).
Perplejidad hizo lo propio con su Deep Research, mientras que X AI de Musk fue un paso más allá al integrar capacidades de búsqueda profunda directamente en su Grok 3, que es esencialmente una variante de la Investigación Profunda.
Francamente, el concepto de búsqueda profunda no es una gran innovación; es esencialmente lo que el año pasado llamábamos RAG (Retrieval Augmented Generation) o búsqueda multisalto. Pero a finales de enero de este año, con Búsqueda profunda-r1 ha ganado una atención y un crecimiento sin precedentes.
El pasado fin de semana, tanto Baidu Search como Tencent WeChat Search han integrado Deepseek-r1 en sus motores de búsqueda.Los ingenieros de IA se dieron cuenta de que laAl incorporar al sistema de búsqueda procesos de pensamiento y razonamiento a largo plazo, es posible lograr una recuperación más precisa y profunda que nunca.
Pero, ¿por qué se produce este cambio ahora? A lo largo de 2024, la "Deep(Re)Search" no parece haber llamado mucho la atención. Hay que recordar que a principios de 2024, el Stanford NLP Lab publicó TORMENTA Proyecto, generación de informes largos basados en la web. ¿Será porque "Deep Search" suena más a moda que más QA, RAG o STORM? Sinceramente, a veces basta con un cambio de marca para que el sector adopte de repente algo que ya existe.
Creemos que el verdadero punto de inflexión será el lanzamiento de OpenAI en septiembre de 2024.o1-previewIntrodujo el concepto de "computación en tiempo de prueba" y cambió sutilmente la percepción del sector.El término "computar mientras se razona" se refiere a invertir más recursos computacionales en la fase de razonamiento (es decir, la fase en la que el gran modelo lingüístico genera el resultado final), en lugar de centrarse en las fases de preentrenamiento o postentrenamiento. Algunos ejemplos clásicos son el razonamiento de cadena de pensamiento (Chain-of-Thought, CoT) y enfoques como"Wait" Técnicas como la inyección (también conocida como control presupuestario) que dan al modelo un mayor margen para la reflexión interna, como la evaluación de múltiples respuestas potenciales, una planificación más profunda y la autorreflexión antes de dar una respuesta final.
Esta filosofía de "computar mientras se razona", así como los modelos que se centran en el razonamiento, llevan a los usuarios a aceptar una noción de "gratificación diferida":Cambie tiempos de espera más largos por resultados de mayor calidad y utilidad. Como en el famoso Experimento del Malvavisco de Stanford, los niños que pueden resistir la tentación de comerse un malvavisco enseguida para poder comerse dos más tarde suelen tener más éxito a largo plazo. deepseek-r1 consolida aún más esta experiencia de usuario, que la mayoría de los usuarios ha aceptado implícitamente, le guste o no.
Esto supone un cambio significativo con respecto a las necesidades de búsqueda tradicionales. En el pasado, si su solución no podía dar una respuesta en 200 milisegundos, equivalía prácticamente al fracaso. Pero en 2025, los desarrolladores de búsquedas experimentados y RAG Ingenieros, antepongan la precisión top-1 y la recuperación a la latencia. Los usuarios se han acostumbrado a tiempos de procesamiento más largos: mientras puedan ver al sistema luchando con el<thinking>.
En 2025, mostrar el proceso de razonamiento se ha convertido en una práctica habitual, y muchas interfaces de chat se muestran en áreas de interfaz de usuario específicas. <think> El contenido.
En este artículo, discutiremos los principios de DeepSearch y DeepResearch examinando nuestra implementación de código abierto. Presentaremos las principales decisiones de diseño y señalaremos las posibles advertencias.
¿Qué es la búsqueda profunda?
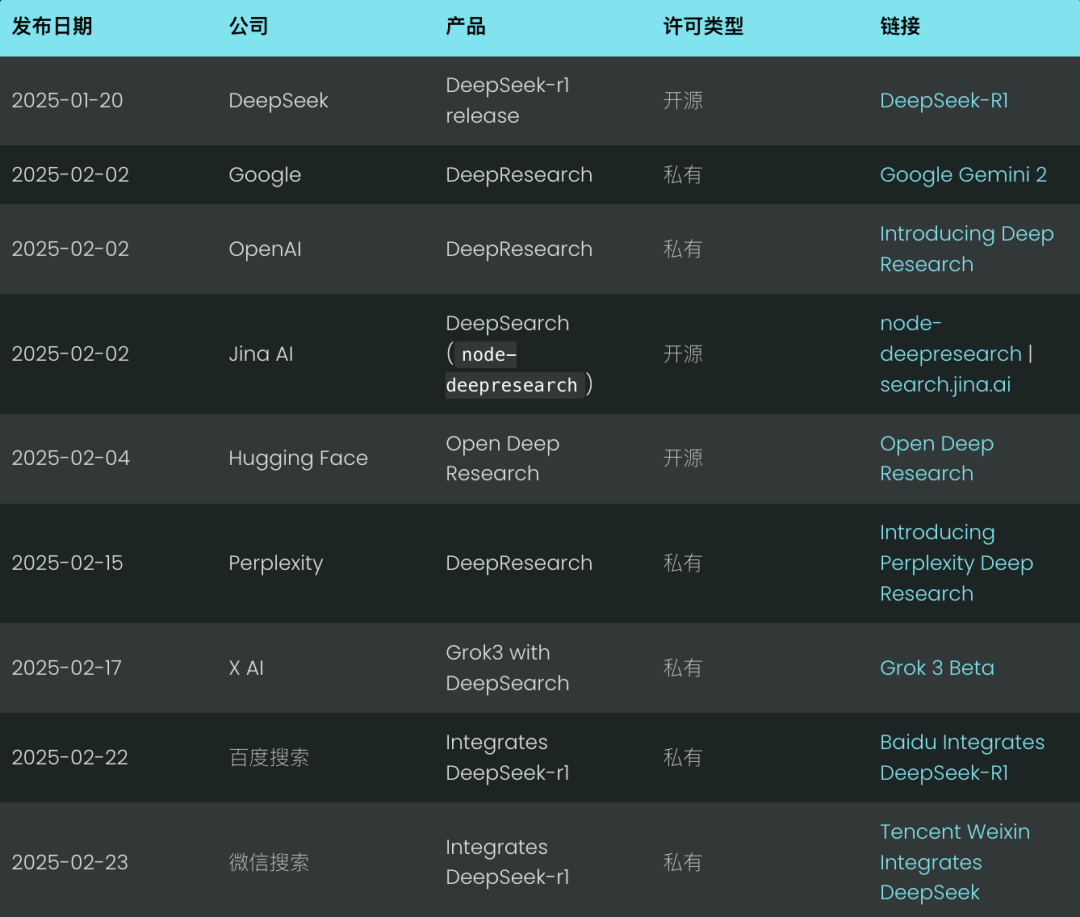
La idea central de DeepSearch es encontrar la respuesta óptima pasando por las tres etapas de búsqueda, lectura y razonamiento hasta encontrar la respuesta óptima. La sesión de búsqueda explora Internet utilizando un motor de búsqueda, mientras que la sesión de lectura se centra en el análisis exhaustivo de páginas web concretas (por ejemplo, utilizando Jina Reader). La sesión de razonamiento se encarga de evaluar el estado actual y decidir si el problema original debe dividirse en subproblemas más pequeños o si deben probarse estrategias de búsqueda alternativas.
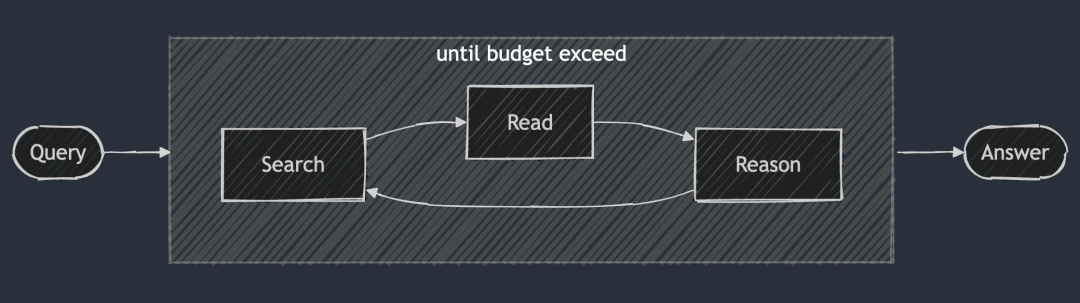 DeepSearch - Búsqueda continua, lectura de páginas web y razonamiento hasta encontrar (o superar) la respuesta. ficha (Presupuesto).
DeepSearch - Búsqueda continua, lectura de páginas web y razonamiento hasta encontrar (o superar) la respuesta. ficha (Presupuesto).
A diferencia del sistema 2024 RAG, que normalmente ejecuta un único proceso de generación de búsquedas, DeepSearch realiza múltiples iteraciones que requieren condiciones de parada explícitas. Estas condiciones pueden basarse en límites de uso de tokens o en el número de intentos fallidos.
Pruebe DeepSearch en search.jina.ai y observe la <thinking>en él para ver si puedes detectar dónde se produce el bucle.
Dicho de otro modo.DeepSearch puede verse como un agente LLM equipado con varias herramientas web, como motores de búsqueda y lectores web.El Agente analiza las observaciones actuales y las acciones pasadas para determinar el siguiente curso de acción: si dar una respuesta directamente o continuar explorando la red. Esto construye una arquitectura de máquina de estados, en la que el LLM se encarga de controlar las transiciones entre estados.
En cada punto de decisión, tiene dos opciones: puede crear pistas que permitan al modelo generativo estándar producir instrucciones de acción específicas o, alternativamente, puede utilizar un modelo de inferencia especializado como Deepseek-r1 para deducir de forma natural la siguiente acción que debe realizarse. Sin embargo, incluso con r1, será necesario interrumpir periódicamente su proceso generativo para inyectar la salida de la herramienta (por ejemplo, resultados de búsqueda, contenido de páginas web) en el contexto y pedirle que continúe con el proceso de razonamiento.
En última instancia, se trata sólo de detalles de aplicación. Tanto si estás elaborando palabras clave como si simplemente utilizas un modelo de inferencia, la funciónTodos siguen los principios básicos de diseño de DeepSearch: buscar, leer e inferir.del ciclo continuo.
¿Y qué es DeepResearch?
DeepResearch añade a DeepSearch un marco estructurado para generar informes de investigación de formato largo. Su flujo de trabajo comienza generalmente con la creación de una tabla de contenidos, y luego aplica sistemáticamente DeepSearch a cada sección requerida del informe: desde la introducción, a los trabajos relacionados, a la metodología, a la conclusión final. Cada sección del informe se genera introduciendo preguntas de investigación específicas en DeepSearch. Por último, todas las secciones se integran en una sola pista para mejorar la coherencia de la narrativa general del informe.
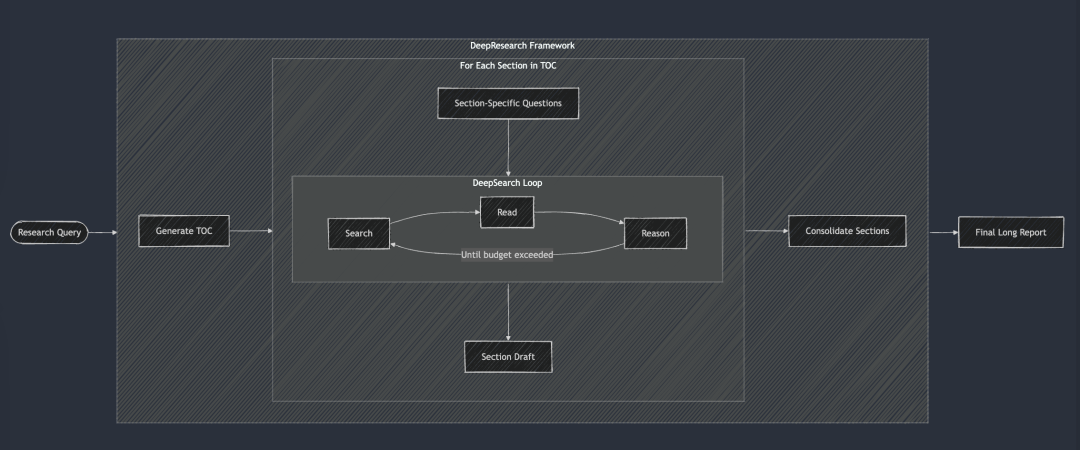 DeepSearch es la base de DeepResearch. Cada capítulo se construye de forma iterativa a través de DeepSearch y luego se mejora la coherencia general antes de generar el informe largo final.
DeepSearch es la base de DeepResearch. Cada capítulo se construye de forma iterativa a través de DeepSearch y luego se mejora la coherencia general antes de generar el informe largo final.
En 2024, también realizamos internamente el proyecto "Investigación", y en aquel momento, para garantizar la coherencia del informe, adoptamos un enfoque bastante estúpido, que consistía en tener en cuenta todos los capítulos en cada iteración, y realizar múltiples mejoras de coherencia. Pero ahora parece que este enfoque es un poco demasiado duro, porque los grandes modelos lingüísticos actuales tienen una ventana de contexto superlarga, y es posible completar las revisiones coherentes de una sola vez, lo que resulta mucho más eficaz.
Sin embargo, no publicamos el proyecto "Investigación" por varias razones:
Lo más destacable es que la calidad de los informes no cumplía sistemáticamente nuestros estándares internos. Lo probamos con dos consultas internas conocidas: "Análisis de la competencia de Jina AI" y "Estrategia de producto de Jina AI". Los resultados fueron decepcionantes, los informes eran mediocres y mediocres, y no nos dieron ninguna sorpresa. En segundo lugar, la fiabilidad de los resultados de búsqueda es escasa, y la ilusión es un problema grave. Por último, la legibilidad general es mala, con muchas repeticiones y redundancias entre secciones. En resumen, no vale nada. Y el informe es tan largo que resulta una pérdida de tiempo y una lectura improductiva.
Sin embargo, este proyecto también nos ha aportado una valiosa experiencia y ha generado una serie de subproductos:
Por ejemplo.Nuestro profundo conocimiento de la fiabilidad de los resultados de las búsquedas y de la importancia de la comprobación de hechos a nivel de párrafo e incluso de frase nos llevó directamente al posterior desarrollo del punto final g.jina.ai.También nos dimos cuenta del valor de la expansión de las consultas y empezamos a invertir esfuerzos en la formación de Small Language Models (SLM) para la expansión de consultas. Por último, nos gustó mucho el nombre ReSearch, que es a la vez una expresión inteligente de la idea de reinventar la búsqueda y un juego de palabras. Era una pena no utilizarlo, así que acabamos usándolo para el anuario de 2024.
En el verano de 2024, nuestro proyecto "Investigación" adoptó un enfoque "incremental", centrado en la generación de informes más largos. Comienza con la generación simultánea del índice del informe (TOC), seguida de la generación simultánea del contenido de todos los capítulos. Por último, cada capítulo se revisa progresivamente de forma asíncrona, teniendo en cuenta en cada revisión el contenido global del informe. En el vídeo de demostración de arriba, la consulta que utilizamos fue "Análisis de la competencia para Jina AI".
DeepSearch vs DeepResearch
Mucha gente tiende a confundir DeepSearch con DeepResearch. Pero, en nuestra opinión, resuelven problemas completamente distintos.DeepSearch es el componente básico de DeepResearch, el motor central de este último.
DeepResearch se centra en la redacción de informes de investigación largos, legibles y de alta calidad.No se trata sólo de buscar información, es un proyecto sistemáticoEl proyecto DeepSearch se diseñó para ser una herramienta muy eficaz para la función de búsqueda, lo que requiere la integración de elementos de visualización eficaces (por ejemplo, gráficos, tablas), una estructura lógica de capítulos que garantice un flujo fluido entre subcapítulos, terminología coherente en todo el texto, evitar la redundancia de información y el uso de transiciones suaves para enlazar los contextos. Estos elementos no están directamente relacionados con la funcionalidad de búsqueda subyacente.
Para resumir las diferencias entre DeepSearch y DeepResearch, véase la tabla siguiente. Cabe mencionar queTanto DeepSearch como DeepResearch son inseparables de los modelos de contexto e inferencia largos, pero por razones ligeramente distintas.
DeepResearch necesita contextos largos para generar informes largos, lo cual es comprensible. Y aunque DeepSearch pueda parecer una herramienta de búsqueda, también necesita recordar intentos de búsqueda anteriores y el contenido de las páginas web para planificar operaciones posteriores, por lo que los contextos largos son igualmente esenciales.

Más información sobre la aplicación DeepSearch
Enlace de código abierto: https://github.com/jina-ai/node-DeepResearch
En el corazón de DeepResearch se encuentra su mecanismo de razonamiento circular. A diferencia de la mayoría de los sistemas GAR, que intentan responder a las preguntas en un solo paso, nosotros utilizamos un bucle iterativo. Continúa buscando información, leyendo fuentes relevantes y razonando hasta que encuentra una respuesta o se le acaba el presupuesto de tokens. He aquí un esqueleto condensado de este gran bucle while:
// 主推理循环
while (tokenUsage < tokenBudget && badAttempts <= maxBadAttempts) {
// 追踪进度
step++; totalStep++;// Obtener la emisión actual de la cola de huecos, o utilizar la emisión original si no está disponible.
const preguntaactual = huecos.longitud > 0 ? gaps.shift() : pregunta;/
/ Generar avisos en función del contexto actual y de las acciones permitidas
system = getPrompt(diaryContext, allQuestions, allKeywords.
allowReflect, allowAnswer, allowRead, allowSearch, allowCoding.
badContext, allKnowledge, unvisitedURLs);/
/ Deja que LLM decida qué hacer a continuación
const result = await LLM.generateStructuredResponse(sistema, mensajes, esquema);
thisStep = result.object;/
/ Realizar las acciones seleccionadas (responder, reflexionar, buscar, visitar, codificar)
if (thisStep.action === 'answer') {
// Procesar acciones de respuesta...
} else if (thisStep.action === 'reflect') {
// Procesamiento de acciones reflexivas...
} // ... Y así sucesivamente para las otras acciones
}Para garantizar la estabilidad y la estructura de la producción, se adoptó una medida clave:Desactivar selectivamente determinadas operaciones en cada paso.
Por ejemplo, desactivamos la operación "visitar" cuando no hay ninguna URL en memoria, e impedimos que el Agente repita la operación "responder" inmediatamente si la última respuesta fue rechazada. Este mecanismo de restricción guía al Agente en la dirección correcta y evita que dé vueltas en el mismo sitio.
señal del sistema
Para el diseño de los avisos del sistema, utilizamos etiquetas XML para definir las distintas partes, lo que nos permite generar avisos del sistema y contenidos generados más robustos. Al mismo tiempo, descubrimos que directamente en el esquema JSON de description campos con restricciones de campo para obtener mejores resultados. Es cierto que, en teoría, los modelos de inferencia como DeepSeek-R1 pueden generar automáticamente la mayoría de las palabras clave. Sin embargo, dadas las restricciones de la longitud del contexto y nuestra necesidad de un control preciso del comportamiento del Agente, esta forma de escribir explícitamente las palabras clave es más fiable en la práctica.
function getPrompt(params...) {
const sections = [];// Añadir una Cabecera con comandos del sistema
sections.push("Eres un asistente de investigación de IA especializado en razonamiento multipaso...") ;
// Añadir fragmentos de conocimiento acumulado (si existen)
if (conocimiento?.longitud) {
sections.push("[entrada de conocimiento]");;
}// Añadir información de contexto para acciones anteriores
if (context?.length) {
sections.push("[Historial de acciones]");;
}
// Añade los intentos fallidos y las estrategias aprendidas
if (badContext?.length) {
sections.push("[intentos fallidos]");;
sections.push("[estrategia mejorada]");;
}
// Definir las opciones de acción disponibles en función del estado actual
sections.push("[definiciones de acciones disponibles]");;
// Añadir instrucciones de formato de respuesta
sections.push("Por favor, responda en formato JSON válido y que se ajuste estrictamente al esquema JSON.");;
return secciones.join("nn");
}
El problema de la falta de conocimientos
En DeepSearch, elUna "pregunta de carencia de conocimientos" se refiere a una carencia de conocimientos que el Agente debe cubrir antes de responder a la pregunta principal.En lugar de intentar responder directamente a la pregunta original, el Agente identifica y resuelve subpreguntas que construyen la base de conocimientos necesaria.
Es una forma muy elegante de hacerlo.
// 在“反思行动”中识别出知识空白问题后
if (newGapQuestions.length > 0) {
// 将新问题添加到队列的头部
gaps.push(...newGapQuestions);// Añade siempre la pregunta original al final de la cola
gaps.push(preguntaoriginal);
}
Crea una cola FIFO (First In First Out) con un mecanismo de rotación que sigue las siguientes reglas:
- Las nuevas preguntas sobre lagunas de conocimiento se priorizan y se colocan a la cabeza de la cola.
- La pregunta original siempre está al final de la cola.
- El sistema extrae las incidencias de la cabecera de la cola en cada paso para procesarlas.
La sutileza de este diseño es que mantiene un contexto compartido para todos los problemas. Es decir, cuando se resuelve un problema de falta de conocimientos, los conocimientos adquiridos pueden aplicarse inmediatamente a todos los problemas posteriores y, con el tiempo, nos ayudarán también a resolver el problema original.
Cola FIFO frente a recursividad
Además de las colas FIFO, también podemos utilizar la recursividad, que corresponde a una estrategia de búsqueda en profundidad. Para cada problema de "brecha de conocimiento", la recursividad crea una pila de llamadas completamente nueva con un contexto independiente. El sistema debe resolver por completo cada problema (y todos sus posibles subproblemas) antes de volver al problema principal.
Como ejemplo, una simple recursión de problemas de brecha de conocimiento profundo de 3 niveles, con los números en los círculos etiquetando el orden en que se resuelven los problemas.
En el modo recursivo, el sistema debe resolver por completo Q1 (y sus posibles subproblemas derivados) antes de poder pasar a otros problemas. Esto contrasta con el enfoque de colas, que volvería a Q1 después de resolver 3 problemas de lagunas de conocimiento.
En la práctica, hemos comprobado que los métodos recursivos dificultan el control del presupuesto. Dado que los subproblemas pueden seguir engendrando nuevos subproblemas, es difícil determinar cuánto presupuesto de fichas debe asignárseles sin unas directrices claras. La ventaja de la recursividad en términos de aislamiento contextual claro palidece en comparación con la complejidad del control del presupuesto y la posibilidad de retrasos en los retornos. En cambio, el diseño de las colas FIFO equilibra bien la profundidad y la amplitud, garantizando que el sistema siga acumulando conocimientos, mejore de forma incremental y, en última instancia, vuelva al problema original en lugar de hundirse en un atolladero recursivo potencialmente infinito.
Reescritura de consultas
Un reto bastante interesante que nos encontramos fue cómo reescribir eficazmente la consulta de búsqueda del usuario:
// 在搜索行为处理器中
if (thisStep.action === 'search') {
// 搜索请求去重
const uniqueRequests = await dedupQueries(thisStep.searchRequests, existingQueries);// Reescribir consultas en lenguaje natural para convertirlas en expresiones de búsqueda más eficaces
const optimisedQueries = await rewriteQuery(uniqueRequests);
// Garantizar que no se dupliquen las búsquedas anteriores
const newQueries = await dedupQueries(optimisedQueries, allKeywords);
// Realizar una búsqueda y almacenar los resultados
for (const query of newQueries) {
const results = await searchEngine(query);
if (results.length > 0) {
storeResults(resultados);
allKeywords.push(consulta);
}
}
}
Descubrimos queLa reescritura de consultas es mucho más importante de lo esperado y podría decirse que es uno de los factores más críticos a la hora de determinar la calidad de los resultados de las búsquedas.Un buen reescritor de consultas no sólo transforma el lenguaje natural del usuario en algo más apropiado para la BM25 Los algoritmos procesan formularios de palabras clave que también amplían la consulta para abarcar más respuestas potenciales en diferentes idiomas, tonos y formatos de contenido.
En cuanto a la desduplicación de consultas, inicialmente probamos un esquema basado en LLM, pero descubrimos que era difícil controlar con precisión el umbral de similitud y los resultados no eran satisfactorios. Al final, optamos por jina-embeddings-v3. Su excelente rendimiento en la tarea de similitud semántica de textos nos permitió lograr fácilmente la desduplicación entre idiomas sin tener que preocuparnos de que las consultas no inglesas se vieran filtradas por falsos positivos. Casualmente, fue el modelo Embedding el que acabó desempeñando un papel clave. Al principio no teníamos intención de utilizarlo para la recuperación en memoria, pero nos sorprendió comprobar que funcionaba con gran eficacia en la tarea de eliminación de duplicados.
Rastreo de contenidos web
El rastreo web y el procesamiento de contenidos también son una parte crucial del proceso, en el que utilizamos el Jina Lector Además del contenido completo de la página web, recopilamos fragmentos de resumen devueltos por los motores de búsqueda, que sirven como información de apoyo para el razonamiento posterior. Estos fragmentos pueden considerarse un resumen conciso del contenido de la página web.
// 访问行为处理器
async function handleVisitAction(URLs) {
// 规范化并过滤已访问过的 URL
const uniqueURLs = normalizeAndFilterURLs(URLs);// Procesar cada URL en paralelo
const results = await Promise.all(uniqueURLs.map(async url => {
intentar {
// Obtener y extraer el contenido
const content = await readUrl(url);
// Almacenado como conocimiento
addToKnowledge(`¿Qué hay en ${url}? `, content, [url], `url');
return {url, éxito: verdadero};
} catch (error) {
return {url, éxito: falso};
} finally {
visitedURLs.push(url);
}
}));
// Actualizar los registros en función de los resultados
updateDiaryWithVisitResults(resultados).
}
Para facilitar el rastreo, normalizamos las URL y limitamos el número de URL a las que se accede por paso para controlar la huella de memoria del agente.
gestión de la memoria
Un reto clave en el razonamiento multipaso es la gestión eficiente de la memoria del agente. El sistema de memoria que hemos diseñado distingue entre lo que cuenta como "memoria" y lo que cuenta como "conocimiento". Pero en cualquier caso, todos forman parte del contexto de la pista LLM, separados por diferentes etiquetas XML:
// 添加知识条目
function addToKnowledge(question, answer, references, type) {
allKnowledge.push({
question: question,
answer: answer,
references: references,
type: type, // 'qa', 'url', 'coding', 'side-info'
updated: new Date().toISOString()
});
}// Registrar los pasos en el log
function addToDiary(paso, acción, pregunta, resultado, evaluación) {
diaryContext.push(`
En el paso ${paso}, tomaste **${acción}** sobre la pregunta: "${pregunta}".
[Detalles y resultados] [Evaluación (si procede)] `); y
}
Dada la tendencia hacia contextos muy largos en el LLM 2025, hemos optado por abandonar las bases de datos vectoriales en favor de un enfoque de memoria contextual.La memoria del Agente consta de tres partes dentro de una ventana contextual: conocimientos adquiridos, sitios web visitados y registros de intentos fallidos. Este enfoque permite al Agente acceder directamente al historial completo y al estado del conocimiento durante el proceso de razonamiento sin pasos adicionales de recuperación.
Evaluación de las respuestas
También descubrimos que la generación de respuestas y la evaluación se realizaban mejor colocándolas en palabras clave diferentes.En nuestra aplicación, cuando se recibe un nuevo problema, primero se identifican los criterios de evaluación y luego se evalúan caso por caso. El evaluador se remite a un número reducido de ejemplos para evaluar la coherencia, lo que resulta más fiable que la autoevaluación.
// 独立评估阶段
async function evaluateAnswer(question, answer, metrics, context) {
// 根据问题类型确定评估标准
const evaluationCriteria = await determineEvaluationCriteria(question);// Evalúe cada criterio individualmente
const resultados = [];
para (criterio de evaluaciónCriterios) {
const result = await evaluarSingleCriterio(criterio, pregunta, respuesta, contexto);
results.push(resultado);
}
// Determinar si la respuesta supera la evaluación global
devolver {
pasar: resultados.cada(r => r.pasar),
think: resultados.map(r => r.razonamiento).join('n')
};
}
Control presupuestario
El control presupuestario no consiste sólo en ahorrar costes, sino en garantizar que el sistema aborda adecuadamente los problemas antes de que se agote el presupuesto y evita devolver las respuestas antes de tiempo.Desde el lanzamiento de DeepSeek-R1, nuestra forma de pensar sobre el control presupuestario ha pasado de limitarse a ahorrar presupuesto a fomentar un pensamiento más profundo y esforzarse por obtener respuestas de alta calidad.
En nuestra aplicación, exigimos explícitamente al sistema que identifique las lagunas de conocimiento antes de intentar responder.
if (thisStep.action === 'reflect' && thisStep.questionsToAnswer) {
// 强制深入推理,添加子问题
gaps.push(...newGapQuestions);
gaps.push(question); // 别忘了原始问题
}
Al tener la flexibilidad de activar y desactivar determinadas acciones, podemos dirigir el sistema para que utilice herramientas que profundicen en el razonamiento.
// 在回答失败后
allowAnswer = false; // 强制代理进行搜索或反思
Para evitar malgastar fichas en caminos no válidos, limitamos el número de intentos fallidos. Cuando nos acercamos al límite del presupuesto, activamos el "Modo Bestia" para asegurarnos de dar una respuesta de todos modos y evitar irnos a casa con las manos vacías.
// 启动野兽模式
if (!thisStep.isFinal && badAttempts >= maxBadAttempts) {
console.log('Enter Beast mode!!!');// Configure las preguntas para orientar las respuestas decisivas
sistema = getPrompt(
diaryContext, allQuestions, allKeywords.
false, false, false, false, false, false, // desactivar otras operaciones
badContext, allKnowledge, unvisitedURLs.
true // Activar Modo Bestia
);
// Forzar la generación de respuestas
const result = await LLM.generateStructuredResponse(system, messages, answerOnlySchema);
estePaso = resultado.objeto;
estePaso.isFinal = true;
}
El mensaje de aviso del Modo Bestia es deliberadamente exagerado, ¡informando claramente al LLM de que ahora debe tomar una decisión decisiva para dar una respuesta basada en la información disponible!
<action-answer>
🔥 启动最高战力! 绝对优先! 🔥Primera Directiva:
- ¡Elimine toda vacilación! Es mejor dar una respuesta que permanecer en silencio.
- Se puede adoptar una estrategia localizada - ¡utilizando toda la información conocida!
- Permitir la reutilización de intentos fallidos anteriores
- Cuando no pueda decidirse: basándose en la información disponible, ¡ataque con decisión!
¡El fracaso no es una opción! ¡Asegúrate de alcanzar tus objetivos! ⚡️
</action-answer>
Esto garantiza que, incluso ante preguntas difíciles o vagas, podamos dar una respuesta útil en lugar de nada.
llegar a un veredicto
Puede decirse que DeepSearch supone un importante avance en la tecnología de búsqueda a la hora de tratar consultas complejas. Desglosa todo el proceso en pasos independientes de búsqueda, lectura y razonamiento, superando muchas de las limitaciones de los sistemas tradicionales RAG de una sola ronda o de cuestionarios multisalto.
Durante el proceso de desarrollo, hemos reflexionado constantemente sobre cómo debería ser la futura base tecnológica de búsqueda en 2025, a la vista de los drásticos cambios que se han producido en todo el sector de la búsqueda tras el lanzamiento de DeepSeek-R1. ¿Qué nuevas necesidades están surgiendo? ¿Qué necesidades están obsoletas? ¿Cuáles son las pseudonecesidades?
Si echamos la vista atrás a la implantación de DeepSearch, hemos identificado cuidadosamente lo que se esperaba y era esencial, lo que dábamos por sentado y no necesitábamos realmente, y lo que no habíamos previsto en absoluto pero resultó ser crítico.
En primer lugar.Es esencial disponer de un LLM de contexto largo que genere la salida en un formato canónico (por ejemplo, esquema JSON).. Quizás también se necesite un modelo de inferencia para mejorar el razonamiento de las acciones y la expansión de las consultas.
Las extensiones de consulta también son absolutamente necesariasya sea mediante SLM, LLM o modelos de inferencia especializados, es una parte ineludible del proceso. Pero después de realizar este proyecto, nos dimos cuenta de que SLM podría no ser adecuado para la tarea, porque la expansión de consultas tiene que ser intrínsecamente multilingüe y no puede limitarse a la simple sustitución de sinónimos o a la extracción de palabras clave. Tiene que ser lo bastante exhaustivo como para tener una base de tokens que abarque varios idiomas (de modo que la escala pueda alcanzar fácilmente los 300 millones de parámetros), y tiene que ser lo bastante inteligente como para pensar de forma innovadora. Así pues, el escalado de consultas mediante SLM por sí solo puede no funcionar.
Las habilidades de búsqueda y lectura en Internet son, sin duda, una prioridad absoluta.Por suerte, nuestro [Lector (r.jina.ai)] ha funcionado muy bien y no sólo es potente sino también escalable, lo que me ha inspirado para pensar en cómo podemos mejorar nuestro punto final de búsqueda (s.jina.ai) hay muchas inspiraciones que pueden centrarse en la optimización en la siguiente iteración.
Los modelos vectoriales son útiles, pero se utilizan en lugares completamente inesperados. Al principio pensamos que se utilizaría para la recuperación en memoria, o junto con una base de datos vectorial para comprimir el contexto, pero ninguna de las dos cosas resultó necesaria. Al final, descubrimos que lo mejor era utilizar el modelo vectorial para la desduplicación, que es básicamente una tarea de similitud semántica textual. Dado que el número de consultas y lagunas de conocimiento suele ser de cientos, es perfectamente suficiente calcular la similitud coseno directamente en memoria sin utilizar una base de datos vectorial.
No utilizamos el modelo RerankerEn teoría, el modelo Embeddings y Reranker puede utilizarse como herramienta para ayudar a determinar qué URLs deben tener prioridad de acceso en función de la consulta, el título de la URL y el fragmento de resumen. Para los modelos Embeddings y Reranker, la capacidad multilingüe es un requisito básico, ya que las consultas y preguntas son multilingües. El procesamiento de contextos largos es útil para los modelos Embeddings y Reranker, pero no es un factor decisivo. No encontramos ningún problema causado por el uso de vectores, probablemente gracias a que los jina-embeddings-v3 (una excelente longitud de contexto de 8192 tokens). En conjunto, losjina-embeddings-v3 responder cantando jina-reranker-v2-base-multilingual Siguen siendo mi primera opción, tienen soporte multilingüe, rendimiento SOTA y buen manejo de contextos largos.
Al final, el marco del Agente resultó innecesario. En cuanto al diseño del sistema, hemos preferido mantenernos cerca de las capacidades nativas de los LLM y hemos evitado introducir capas de abstracción innecesarias.El SDK de IA de Vercel proporciona una gran comodidad a la hora de adaptarse a diferentes proveedores de LLM, lo que reduce enormemente el esfuerzo de desarrollo, ya que sólo hay que cambiar una línea de código para crear un nuevo LLM en el Géminis Cambiando entre Studio, OpenAI y Google Vertex AI. La gestión de memoria proxy tiene sentido, pero introducir un marco especializado para ello es cuestionable. Personalmente, creo que confiar demasiado en los frameworks puede construir una barrera entre LLM y el desarrollador, y el azúcar sintáctico que proporcionan puede convertirse en una carga para el desarrollador. Muchos frameworks LLM/RAG ya han validado esto. Es más sabio abrazar las capacidades nativas de LLM y evitar estar atado a los frameworks.
Este post es de WeChat: Jina AI
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...