
Razonamiento con grandes modelos lingüísticos: equilibrio entre "subpensar" y "sobrepensar"
Base de conocimientos de IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 54.2K 00

Los grandes modelos lingüísticos (LLM) están evolucionando rápidamente, y su capacidad de razonamiento se ha convertido en un indicador clave de su nivel de inteligencia. En particular, los modelos con grandes capacidades de razonamiento, como los de OpenAI o1yDeepSeek-R1yQwQ-32B responder cantando Kimi K1.5 Éstos han atraído una gran atención por su capacidad para resolver problemas complejos imitando los procesos profundos del pensamiento humano. Esta capacidad suele implicar una técnica llamada Inference-Time Scaling, que permite al modelo dedicar más tiempo a explorar y corregir a medida que genera respuestas.
Sin embargo, una mirada más profunda revela que estos modelos suelen caer en dos extremos en su razonamiento:Infravalorar responder cantando Pensar demasiado.
no es suficiente para reflexionar Se refiere al frecuente cambio de ideas en el razonamiento del modelo, lo que dificulta centrarse en una dirección prometedora para profundizar. La salida del modelo puede estar llena de palabras como "alternativamente", "pero espera", "déjame reconsiderarlo", etc. que como se muestra en la figura siguiente, dando lugar a una respuesta final errónea. Este fenómeno puede analogarse a la falta de atención humana, que afecta a la validez del razonamiento.

pensando demasiado En cambio, el modelo genera largas e innecesarias "cadenas de pensamiento" sobre problemas sencillos. Por ejemplo, para un problema aritmético básico como "2+3=?" Por ejemplo, para un problema aritmético básico como "2+3=?", algunos modelos pueden requerir cientos o incluso miles de horas de trabajo. token para verificar o explorar iterativamente múltiples soluciones, como se muestra a continuación. Aunque los procesos de pensamiento complejos son beneficiosos para los problemas difíciles, en escenarios sencillos esto sin duda resulta en un desperdicio de recursos computacionales.
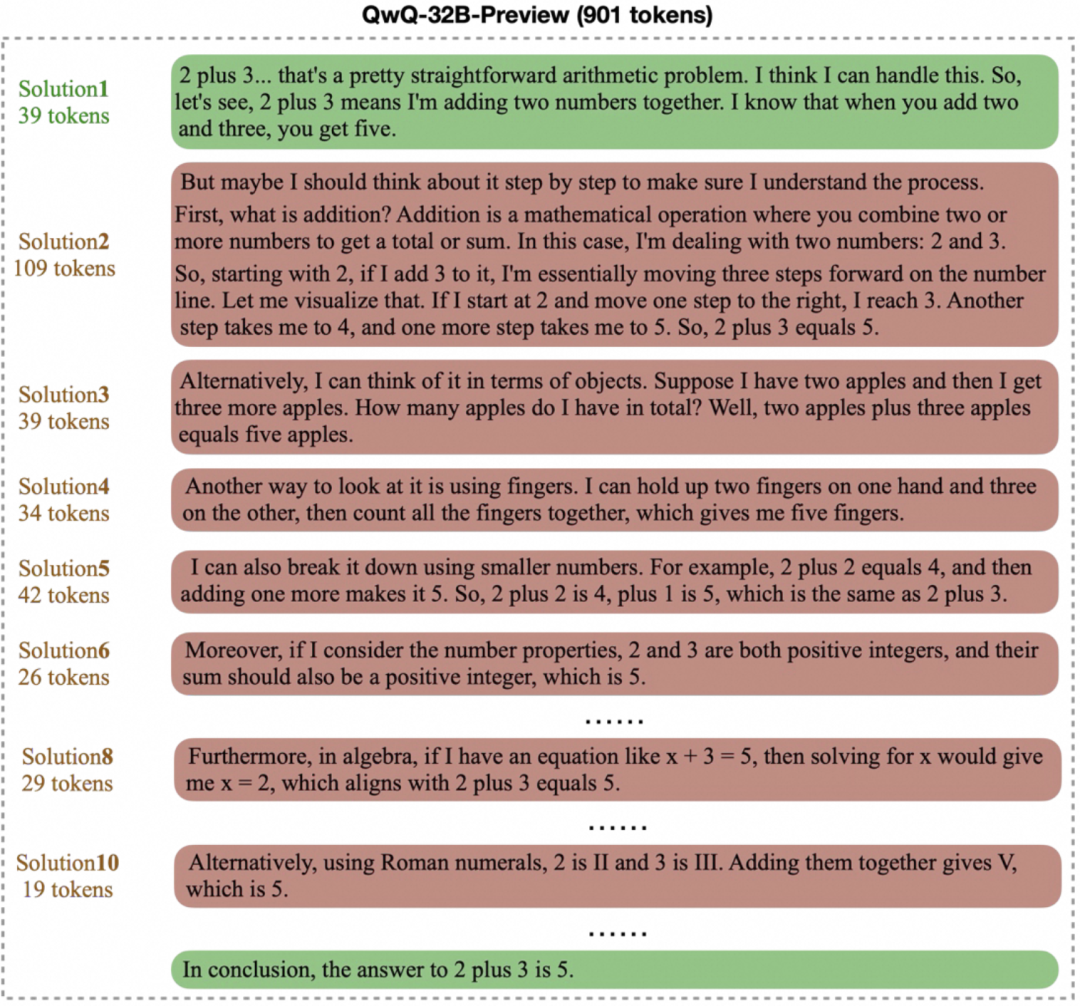
Juntas, estas dos preguntas apuntan a un reto central: ¿cómo mejorar la eficacia del pensamiento del modelo garantizando al mismo tiempo la calidad de las respuestas? Un modelo ideal debería ser capaz de encontrar y dar la respuesta correcta en el menor tiempo posible.
Para hacer frente a este reto.EvalScope El proyecto introduce EvalThink con el objetivo de proporcionar una herramienta estandarizada para evaluar la eficiencia de pensamiento de un modelo. En este documento, utilizaremos el MATH-500 Por ejemplo, el análisis del conjunto de datos incluye DeepSeek-R1-Distill-Qwen-7B El rendimiento de una serie de modelos de razonamiento, incluidos los que se centran en seis dimensiones: razonamiento modelo token Número, a la primera token Número, reflexiones restantes token Números,token Eficacia, número de subcadenas de pensamiento y precisión.
Metodología y proceso de evaluación
El proceso de evaluación consta de dos etapas principales: la evaluación del razonamiento del modelo y la evaluación de la eficacia del pensamiento del modelo.
Evaluación del razonamiento del modelo
El objetivo de esta fase es obtener el modelo en MATH-500 Resultados brutos de inferencia y precisión de base en el conjunto de datos.MATH-500 El conjunto de datos contiene 500 problemas matemáticos de dificultad variable (del Nivel 1 al Nivel 5).
Preparación del entorno de evaluación
La evaluación puede realizarse accediendo a un servicio de razonamiento compatible con la API de OpenAI.EvalScope El marco también admite el uso de transformers La biblioteca se revisa localmente. Para quienes tengan que tratar con largas cadenas de pensamiento (posiblemente más de 10.000 token) del modelo de inferencia utilizando vLLM tal vez ollama Los marcos de inferencia eficientes como éstos despliegan modelos que pueden acelerar considerablemente el proceso de evaluación.
para DeepSeek-R1-Distill-Qwen-7B A modo de ejemplo, utilice vLLM El comando de ejemplo para desplegar el servicio es el siguiente:
VLLM_USE_MODELSCOPE=True CUDA_VISIBLE_DEVICES=0 python -m vllm.entrypoints.openai.api_server --model deepseek-ai/DeepSeek-R1-Distill-Qwen-7B --served-model-name DeepSeek-R1-Distill-Qwen-7B --trust_remote_code --port 8801
Revisión del razonamiento ejecutivo
aprobar (una factura o inspección, etc.) EvalScope (utilizado como expresión nominal) TaskConfig Configure la dirección API del modelo, el nombre, el conjunto de datos, el tamaño del lote y los parámetros de generación y, a continuación, ejecute la tarea de evaluación. A continuación se muestra un ejemplo de código Python:
from evalscope import TaskConfig, run_task
task_config = TaskConfig(
api_url='http://0.0.0.0:8801/v1/chat/completions', # 推理服务地址
model='DeepSeek-R1-Distill-Qwen-7B', # 模型名称 (需与部署时一致)
eval_type='service', # 评测类型:服务
datasets=['math_500'], # 数据集
dataset_args={'math_500': {'few_shot_num': 0, 'subset_list': ['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5']}}, # 数据集参数,包含难度级别
eval_batch_size=32, # 并发请求数
generation_config={
'max_tokens': 20000, # 最大生成 token 数,设置较大值防截断
'temperature': 0.6, # 采样温度
'top_p': 0.95, # top-p 采样
'n': 1, # 每个请求生成一个回复
},
)
run_task(task_config)
Una vez finalizada la evaluación, el modelo se exportará en MATH-500 Precisión en cada nivel de dificultad (AveragePass@1):
| Model | Dataset | Metric | Subset | Num | Score | Cat.0 |
|-----------------------------|-----------|---------------|----------|-----|--------|---------|
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 1 | 43 | 0.9535 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 2 | 90 | 0.9667 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 3 | 105 | 0.9587 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 4 | 128 | 0.9115 | default |
| DeepSeek-R1-Distill-Qwen-7B | math_500 | AveragePass@1 | Level 5 | 134 | 0.8557 | default |
Evaluación de la eficiencia del pensamiento modelo
Tras obtener la inferenciaEvalThink Intervenciones de componentes para análisis de eficiencia más profundos. Las métricas de evaluación básicas incluyen:
- razonamiento modelizado
token(Fichas de razonamiento)Cadenas de pensamiento durante la generación de respuestas (como en el modelo O1/R1)</think>(lo que precede a la bandera) contenida en eltokenImporte total. - acertar a la primera
tokenNúmero (primeras fichas correctas)Desde el inicio de la salida del modelo hasta la primera aparición de una respuesta correcta identificable.tokenCantidad. - Reflexiones pendientes
tokenFichas de reflexión:: Desde la primera posición de respuesta correcta hasta el final de la cadena de pensamientotokenCantidad. Esto refleja en parte el coste de continuar la validación o exploración después de que el modelo haya encontrado una respuesta. - Num Pensamiento:: Mediante el recuento de significantes específicos (p. ej.
alternatively,but wait,let me reconsider) para estimar la frecuencia con la que el modelo cambia de idea. tokenEficacia de las fichas:: Medir la eficacia del pensamientotokenIndicador de porcentaje, calculado como primera vez correctatokenNúmeros y razonamiento generaltokenLa media de la relación entre el número de (sólo se contaron las muestras con respuestas correctas):
Eficacia de las fichas = 1⁄N ∑ Primera Correcta Fichasi⁄Razonamiento Tokensi
donde N es el número de preguntas contestadas correctamente. Cuanto mayor sea el valor, más "eficiente" será el pensamiento del modelo.
A efectos de determinar el "derecho de primera token número", un marco de evaluación que se basa en la ProcessBench La idea es utilizar un modelo de juez independiente, por ejemplo Qwen2.5-72B-Instructpara comprobar los pasos de inferencia y localizar la posición en la que se produce la respuesta correcta más pronto. La aplicación consiste en descomponer la salida del modelo en pasos (estrategia opcional: por separador específico) separatorPalabras clave de prensa keywordso reescrito y rebanado con la ayuda del LLM llm), y luego dejar que el modelo de árbitro juzgue a cada uno.
Ejemplo de código para realizar una evaluación de la eficiencia de think:
from evalscope.third_party.thinkbench import run_task
# 配置裁判模型服务
judge_config = dict(
api_key='EMPTY',
base_url='http://0.0.0.0:8801/v1', # 假设裁判模型也部署在此服务
model_name='Qwen2.5-72B-Instruct',
)
# 配置待评估模型的信息
model_config = dict(
report_path='./outputs/2025xxxx', # 上一步推理结果路径
model_name='DeepSeek-R1-Distill-Qwen-7B', # 模型名称
tokenizer_path='deepseek-ai/DeepSeek-R1-Distill-Qwen-7B', # Tokenizer 路径,用于计算 token
dataset_name='math_500', # 数据集名称
subsets=['Level 1', 'Level 2', 'Level 3', 'Level 4', 'Level 5'], # 数据集子集
split_strategies='separator', # 推理步骤分割策略
judge_config=judge_config
)
max_tokens = 20000 # 过滤 token 过长的输出
count = 200 # 每个子集抽样数量,加速评测
# 运行思考效率评估
run_task(model_config, output_dir='outputs', max_tokens=max_tokens, count=count)
Los resultados de la evaluación detallarán las seis métricas dimensionales del modelo en cada nivel de dificultad.
Análisis y discusión de los resultados
El equipo de investigación utilizó EvalThink derecha DeepSeek-R1-Distill-Qwen-7B y otros modelos (QwQ-32ByQwQ-32B-PreviewyDeepSeek-R1yDeepSeek-R1-Distill-Qwen-32B) y se añadió un modelo matemático especializado no inferencial Qwen2.5-Math-7B-Instruct A modo de comparación.
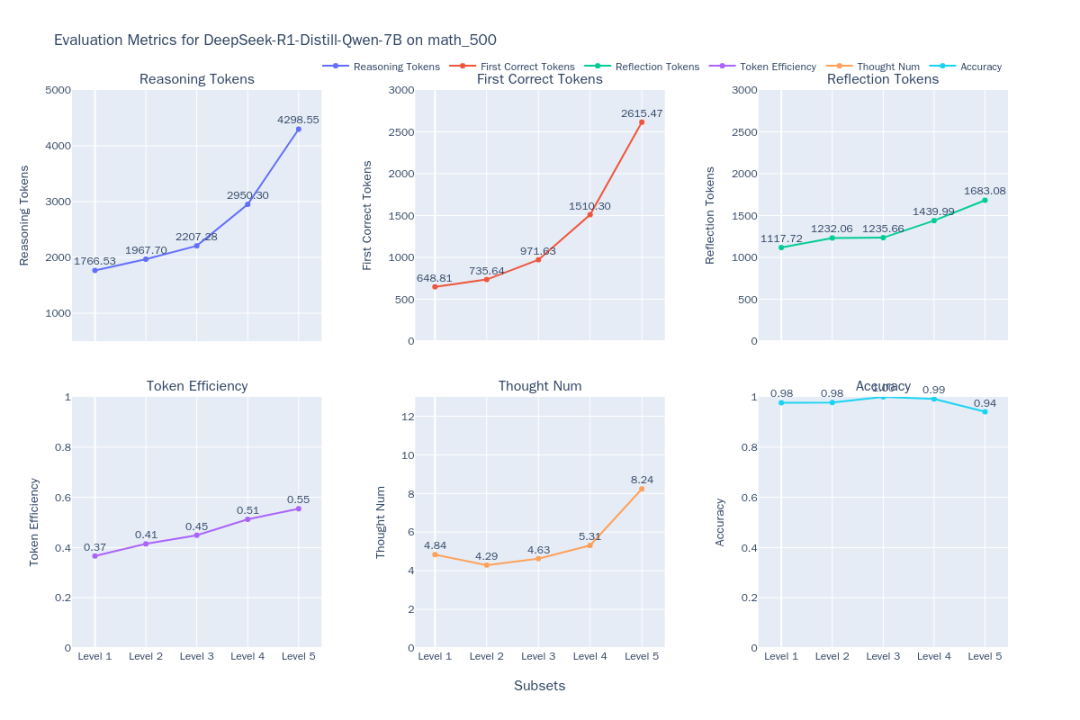
Figura 1: Indicador de eficiencia del pensamiento DeepSeek-R1-Distill-Qwen-7B
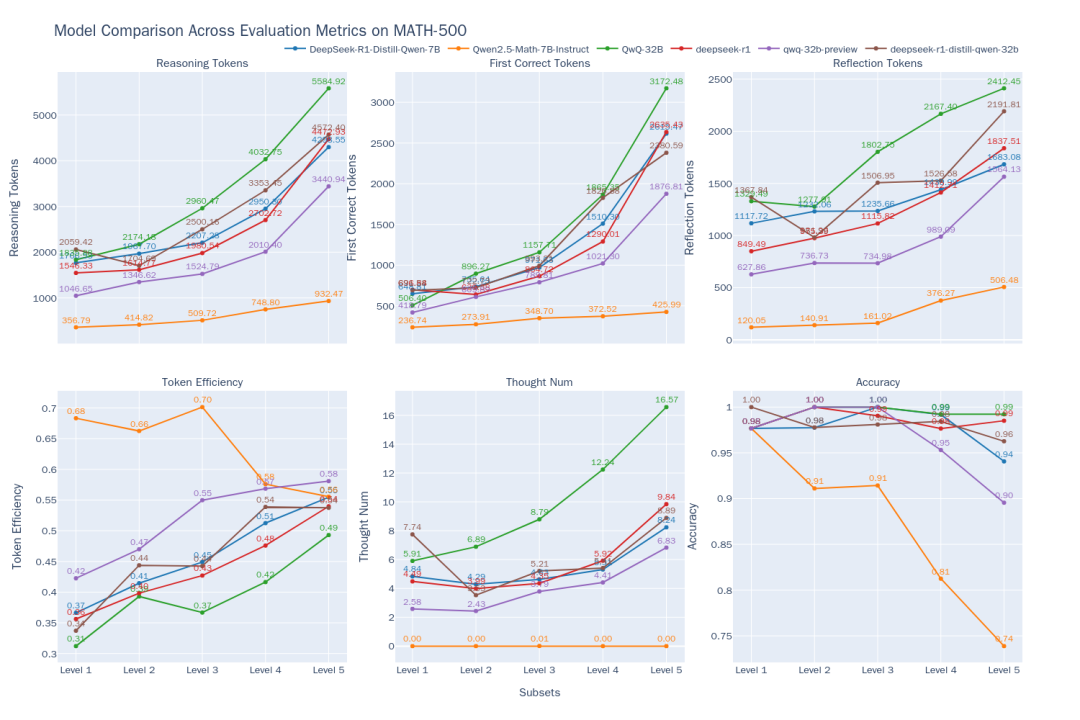
Figura 2: Comparación de la eficacia del pensamiento de los 6 modelos en diferentes niveles de dificultad de MATH-500
Los resultados de la comparación muestran las siguientes tendencias (Figura 2):
- Correlación dificultad-rendimientoA medida que aumenta la dificultad del problema (de Nivel 1 a Nivel 5), disminuye la precisión de la mayoría de los modelos. Sin embargo.
QwQ-32Bresponder cantandoDeepSeek-R1sobresalir en problemas difíciles.QwQ-32Bmayor precisión en el nivel 5. Al mismo tiempo, el resultado de todos los modelostokenTodos los números son más largos a medida que aumenta la dificultad, lo que concuerda con la expectativa de "razonar mientras se expande": el modelo necesita "pensar" más para resolver el rompecabezas. - Clase O1/R1 Propiedades del modelo de razonamiento:
- Mejora de la eficiencia:: Curiosamente, para
DeepSeek-R1responder cantandoQwQ-32BEste tipo de modelo de inferencia, aunque la salida se alarga, latokenEficiencia (efectiva)tokenporcentaje) también aumenta con la dificultad (DeepSeek-R1De 36% a 54%.QwQ-32B(de 31% a 49%). Esto sugiere que su pensamiento adicional en los problemas difíciles es más "rentable", mientras que en los problemas sencillos puede haber un cierto "exceso de pensamiento", por ejemplo, una validación iterativa innecesaria.QwQ-32B(utilizado como expresión nominal)tokenEl consumo es alto en general, lo que puede ser una de las razones por las que puede mantener un alto índice de precisión en el Nivel 5, pero también deja entrever una tendencia a pensar demasiado las cosas. - Caminos del pensamiento:
DeepSeekEl número de subcadenas de pensamiento para los modelos en serie es relativamente estable en los niveles 1 a 4, pero aumenta drásticamente en el nivel 5, el más difícil, lo que sugiere que el nivel 5 supone un reto importante para estos modelos y requiere múltiples intentos. Por el contrario.QwQ-32BEl modelo en serie presenta un crecimiento más suave en el número de cadenas de pensamiento, lo que refleja diferentes estrategias de afrontamiento.
- Mejora de la eficiencia:: Curiosamente, para
- Limitaciones de los modelos no inferenciales:: Modelos matemáticos especializados
Qwen2.5-Math-7B-InstructLa precisión disminuye drásticamente cuando se trata de problemas difíciles, y su rendimientotokenLa cifra es muy inferior a la de los modelos de razonamiento (alrededor de un tercio). Esto sugiere que, aunque tales modelos pueden ser más rápidos y consumir menos recursos en problemas comunes, la falta de procesos de pensamiento más profundos les da un "techo" de rendimiento significativo en tareas de razonamiento complejas.
Consideraciones metodológicas y limitaciones
en aplicación EvalThink Hay varios puntos que deben tenerse en cuenta al realizar una evaluación:
- Definición de indicadores:
- propuesto en este documento
tokenLos indicadores de eficiencia, basados en los conceptos de "pensamiento excesivo" y "pensamiento insuficiente" de la literatura, se centran principalmente entokenLa cantidad, una medida simplificada del proceso de pensamiento, no logra captar todos los detalles de la calidad del pensamiento. - El cálculo del número de subcadenas de pensamiento se basa en palabras clave predefinidas, y puede ser necesario ajustar la lista de palabras clave para que los distintos modelos reflejen con precisión sus patrones de pensamiento.
- propuesto en este documento
- Ámbito de aplicación:
- Las métricas actuales se validan principalmente en conjuntos de datos de razonamiento matemático, y su eficacia en otros escenarios, como el cuestionario abierto y la generación de ideas, aún está por probar.
- cater
DeepSeek-R1-Distill-Qwen-7Bse basa en un modelo matemático de destilación delMATH-500Puede haber una ventaja natural en el rendimiento del conjunto de datos. Los resultados de la evaluación deben interpretarse en el contexto del modelo.
- Dependencia del modelo de adjudicación:
tokenEl cálculo de la eficiencia se basa en el modelo de juez (JM) para juzgar con precisión la corrección de los pasos de razonamiento. EnProcessBench4Se trata de una tarea difícil para los modelos existentes, como señala el estudio, y suele requerir modelos muy capaces para estar a la altura.- Los errores de apreciación en el modelo de arbitraje pueden repercutir directamente en
tokenprecisión de los indicadores de eficiencia, por lo que es fundamental elegir el modelo de arbitraje adecuado.
En pocas palabras.EvalThink Se proporciona un conjunto de marcos y métricas para evaluar cuantitativamente la eficacia del pensamiento LLM, revelando el rendimiento de los distintos modelos en términos de precisión,token entre consumo y profundidad de pensamiento. Estos resultados son útiles para orientar la formación de modelos (p. ej. GRPO y SFT), es informativo desarrollar modelos de próxima generación que sean más eficientes y puedan ajustar de forma adaptativa la profundidad del pensamiento en función de la dificultad del problema.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...