
¿Cómo calcular el número de parámetros de un modelo grande y qué significan 7B, 13B y 65B?
Base de conocimientos de IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 94.5K 00

Recientemente, muchas personas dedicadas al entrenamiento y la inferencia de grandes modelos han debatido la relación entre el número de parámetros del modelo y su tamaño. Por ejemplo, la famosa serie alpaca de grandes modelos LLaMA contiene cuatro versiones con diferentes tamaños de parámetros, LLaMA-7B, LLaMA-13B, LLaMA-33B y LLaMA-65B.
La "B" aquí es una abreviatura de "Billion", que significa mil millones. Así, el modelo LLaMA-7B más pequeño contiene unos 7.000 millones de parámetros, mientras que el modelo LLaMA-65B más grande contiene unos 65.000 millones de parámetros.
Entonces, ¿cómo se calculan estos recuentos de parámetros? Además, ¿cuál es el nivel aproximado de recuento de parámetros de modelos grandes correspondiente a un archivo de modelo de 100 GB? ¿Miles de millones, decenas de miles de millones, cientos de miles de millones o billones? Este artículo responderá a estas preguntas en profundidad.
I. Métodos para calcular la cantidad de grandes parámetros del modelo
Tomaremos como ejemplo el Transformer, la infraestructura del gran modelo, para analizar en detalle el proceso de recuento de parámetros.
Un estándar Transformador El modelo consta de L capas idénticas apiladas una encima de otra, y cada capa contiene dos partes principales: la capa de autoatención (SAL) y la capa de red neuronal feed-forward (MLP).
1. Autoatención
El mecanismo de autoatención es el núcleo del transformador. Tanto si se trata de autoatención como de autoatención multicabezal (MHA), el cálculo de la cantidad de parámetros del núcleo es el mismo.
En la capa de autoatención, la secuencia de entrada se divide primero en tres vectores: un vector de consulta (Query, Q), un vector de clave (Key, K) y un vector de valor (Value, V). En MHA, estos tres vectores se dividen a su vez en varias cabezas, cada una de las cuales es responsable de centrarse en una parte diferente de la secuencia de entrada.

- Autoatención de una sola cabeza. Q, K, V se transforman linealmente mediante una matriz de pesos de forma [h, h], donde h es la dimensión de la capa oculta. Así, el número total de parámetros de Q, K, V es 3h². Además, hay una capa de transformación lineal para la salida con la misma forma de matriz de pesos [h, h]. Por lo tanto, el número total de parámetros para la autoatención de una sola cabeza es 4h² (ignora el término de sesgo).
- Atención Multicabezal (AMC). Supongamos que hay n_cabezas, cada una con dimensión h_cabeza = h / n_cabeza. Cada cabeza tiene una matriz de pesos Q, K, V independiente de la forma [h, h_cabeza]. Por lo tanto, la cantidad paramétrica de la matriz de pesos Q, K, V para cada cabeza es 3 * h * h_head = 3h²/n_head. El número total de cantidades paramétricas para las n_cabezas es n_head * (3h²/n_head) = 3h². Por último, la forma de la matriz de pesos de transformación lineal para la capa de salida es [h, h]. Por lo tanto, el número total de parámetros de la MHA también es 4h² (ignora el término de sesgo).
Por lo tanto, el número de parámetros de la capa de autoatención puede aproximarse a 4h², tanto para cabezas únicas como múltiples.
2. Capa de red neuronal feed-forward (MLP)
La capa MLP consta de dos capas lineales. La primera capa lineal amplía la dimensión de la capa oculta h a 4h, y la segunda capa lineal reduce la dimensión de 4h a h.

- La matriz de pesos de la primera capa lineal tiene la forma [h, 4h] y el número de parámetros es 4h².
- La segunda capa lineal tiene una matriz de pesos de la forma [4h, h] con la misma cantidad paramétrica de 4h².
Por tanto, el número total de parámetros de la capa MLP es de 8h² (sin tener en cuenta el término de sesgo).
3. Normalización de capas
Después de cada capa de Autoatención y MLP, y después de la última capa de salida del Transformador, suele haber una operación de Normalización de Capas. Cada capa de Normalización de Capas contiene dos parámetros entrenables:
- Parámetro de escala (gamma): La forma es [h].
- Parámetro de traslación (beta): la forma es [h].
Dado que cada capa del Transformador tiene dos Capas de Normalización (después de la Autoatención y del MLP respectivamente) más una después de la capa de salida, el número total de parámetros de Normalización de Capas para la capa L del Transformador es (2L + 1) * 2h.
4. Incrustación
Primero hay que convertir el texto de entrada en vectores de palabras mediante la capa de incrustación de palabras. Suponiendo que el tamaño de la lista de palabras sea V y la dimensión del vector de palabras sea h, el número de parámetros de la capa de incrustación de palabras es Vh.
5. Capa de salida
La matriz de pesos de la capa de salida suele compartirse con la capa de incrustación de palabras (Weight Tying) para reducir el número de parámetros y mejorar potencialmente el rendimiento. Por lo tanto, si se comparte el peso, la capa de salida no suele introducir un número adicional de parámetros. Si no se comparte, el número de parámetros es Vh.
6. Codificación posicional
La codificación de la posición se utiliza para proporcionar al modelo información sobre la posición de las palabras en la secuencia de entrada.
- Códigos de posición entrenables. Si se utiliza la codificación posicional entrenable, el número de parámetros es N * h, donde N es la longitud máxima de la secuencia. Por ejemplo, la longitud máxima de secuencia de ChatGPT es 4k.
- Código de posición relativa (por ejemplo, RoPE o ALiBi). Estos métodos no introducen parámetros entrenables.
Debido al número relativamente pequeño de parámetros codificados posicionalmente, suelen ser insignificantes en el cálculo del número total de parámetros.
7. Cálculo del número total de participantes
En resumen, el número total de parámetros para un modelo de transformador de capa L es:
Número total de parámetros = L * (parámetro Self-Attention + parámetro MLP + parámetro LayerNorm * 2) + parámetro Embedding + parámetro de la capa de salida + parámetro LayerNorm (después de la capa de salida)
Número total de parámetros ≈ L * (4h² + 8h² + 4h) + Vh + (Vh opcional) + 2h
Número total de parámetros ≈ L * (12h² + 4h) + Vh + 2h (suponiendo que la capa de salida comparte pesos con la capa de incrustación de palabras)
Cuando la dimensión oculta h es grande, los términos primarios 4h y 2h son despreciables y el número de parámetros del modelo puede aproximarse aún más como:
Número total de parámetros ≈ 12Lh² + Vh
8. Número estimado de participantes en el LLaMA
La siguiente tabla muestra algunos de los parámetros clave de las distintas versiones de LLaMA y la estimación de sus recuentos de parámetros:
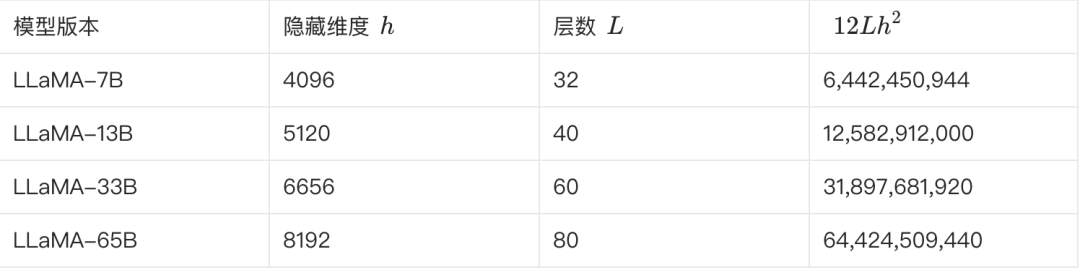
**Podemos comprobarlo según la fórmula anterior. Tomando LLaMA-7B como ejemplo, según la tabla, L=32, h=4096, V=32000.**
Número estimado de parámetros ≈ 12 * 32 * 4096² + 32000 * 4096 ≈ 6,55B
Esta estimación se acerca más a los 6.700 millones. Otras versiones pueden estimarse y validarse de este modo.
II. Conversión de grandes cantidades paramétricas del modelo en tamaños del modelo
Una vez entendido cómo se calcula el número de parámetros, a continuación veremos cómo se convierten el número de parámetros y el tamaño del modelo.
Seguimos utilizando LLaMA-7B como ejemplo, que tiene unos 7.000 millones de participantes.
- Cálculos teóricos. Si cada parámetro se almacena en formato FP32 (número en coma flotante de 32 bits que ocupa 4 bytes), el tamaño teórico de LLaMA-7B es: 7B * 4 bytes = 28GB.
- Almacenamiento físico. Para ahorrar espacio de almacenamiento y mejorar la eficiencia computacional, los pesos del modelo se almacenan normalmente en un formato de menor precisión, como FP16 (número en coma flotante de 16 bits que ocupa 2 bytes) o BF16. Cuando se utiliza el almacenamiento FP16, el tamaño de LLaMA-7B es teóricamente: 7B * 2 bytes = 14GB.
- Otros factores. Además de los parámetros de peso, el archivo del modelo también puede contener información sobre el estado del optimizador (por ejemplo, el impulso y la varianza del optimizador Adam), la lista de palabras, la configuración del modelo, etc., que ocuparán espacio de almacenamiento adicional. Además, algunos parámetros (por ejemplo, gamma y beta para la normalización de capas) pueden almacenarse en formato FP32.
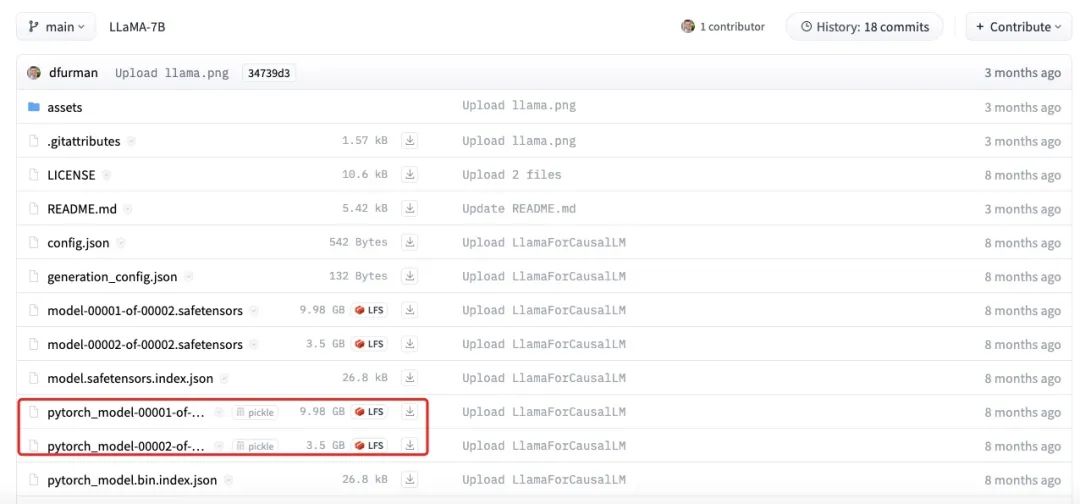
La figura anterior muestra el tamaño real del archivo del modelo LLaMA-7B. Puede verse que el tamaño total de cada parte es de unos 13,5 GB, lo que se aproxima más a nuestra estimación de 14 GB. Las pequeñas diferencias pueden deberse a errores de redondeo, parámetros de sesgo o al hecho de que algunos parámetros todavía se almacenan utilizando FP32.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...