Crawl4AI: herramienta asíncrona de código abierto para extraer datos estructurados sin LLM
Últimos recursos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 84.8K 00

Introducción general
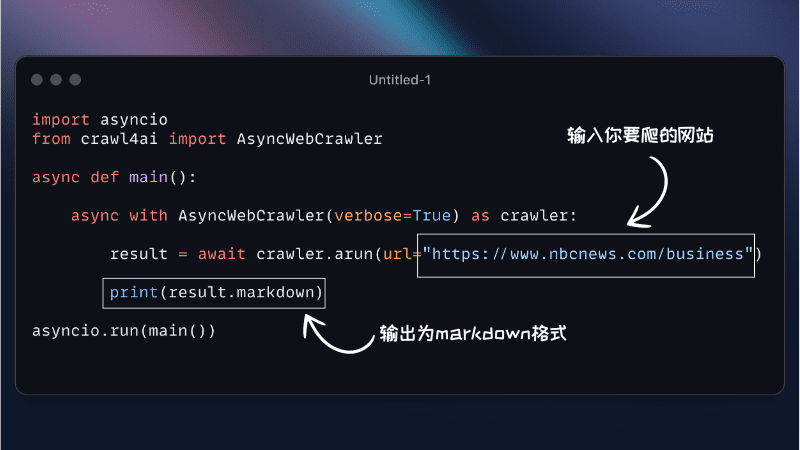
Crawl4AI es una herramienta de rastreo web asíncrona de código abierto diseñada para grandes modelos lingüísticos (LLM) y aplicaciones de inteligencia artificial (IA). Simplifica el rastreo web y el proceso de extracción de datos, soporta el rastreo web eficiente, y proporciona formatos de salida LLM-amigables como JSON, HTML limpiado y Markdown.Crawl4AI soporta el rastreo de múltiples URLs al mismo tiempo, completamente libre y de código abierto, adecuado para una variedad de necesidades de rastreo de datos.
Documentación oficial de ayuda
Lista de funciones
- Arquitectura asíncrona: procesamiento eficaz de varias páginas web, rastreo rápido de datos
- Múltiples formatos de salida: soporta JSON, HTML, Markdown
- Rastreo multi-URL: rastrea varias páginas web al mismo tiempo
- Extracción de etiquetas multimedia: extrae etiquetas de imagen, audio y vídeo
- Extracción de enlaces: extrae todos los enlaces externos e internos
- Extracción de metadatos: extraer metadatos de las páginas
- Ganchos personalizados: compatibilidad con autenticación, cabeceras de petición y modificaciones de página.
- Personalización de los agentes de usuario
- Captura de pantalla de la página: Captura de pantalla de la página de rastreo
- Ejecutar JavaScript personalizado: Ejecutar varios JavaScripts personalizados antes del rastreo
- Soporte de proxy: mejora de la privacidad y el acceso
- Gestión de sesiones: manejo de escenarios complejos de rastreo multipágina
Utilizar la ayuda
Proceso de instalación
Crawl4AI ofrece opciones de instalación flexibles para una variedad de escenarios de uso. Puede instalarlo como un paquete Python o utilizar Docker.
Instalación con pip
- Instalación básica
pip install crawl4aiEsto instalará la versión asíncrona de Crawl4AI por defecto, utilizando Playwright para el rastreo web.
- Instalación manual de Playwright (si es necesario)
playwright installo
python -m playwright install chromium
Instalación con Docker
- Extracción de una imagen Docker
docker pull unclecode/crawl4ai - Ejecución de contenedores Docker
docker run -it unclecode/crawl4ai
Normas de uso
- Uso básico
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() results = crawler.crawl(["https://example.com"]) print(results) - Ajustes personalizados
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler( user_agent="CustomUserAgent", headers={"Authorization": "Bearer token"}, custom_js=["console.log('Hello, world!')"] ) results = crawler.crawl(["https://example.com"]) print(results) - Extracción de datos específicos
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() results = crawler.crawl(["https://example.com"], extract_media=True, extract_links=True) print(results) - Gestión de sesiones
from crawl4ai import AsyncWebCrawler crawler = AsyncWebCrawler() session = crawler.create_session() session_results = session.crawl(["https://example.com"]) print(session_results)
Crawl4AI ofrece un amplio conjunto de funciones y opciones de configuración flexibles para una gran variedad de necesidades de rastreo web y de datos. Gracias a sus detalladas guías de instalación y uso, los usuarios pueden empezar a utilizarlo fácilmente y aprovechar al máximo las potentes funciones de la herramienta.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...