
Razonamiento complejo con grandes modelos de OpenAI-o1
Base de conocimientos de IAPublicado hace 1 año Círculo de intercambio de inteligencia artificial 43.2K 00

En 2022 OpenAI lanzó ChatGPT, que se convirtió en la APP más rápida del mundo en superar los cientos de millones de usuarios, y en ese momento la gente pensó que estábamos más cerca de la IA real. Pero la gente pronto descubrió que ChatGPT podía mantener conversaciones e incluso escribir poemas y artículos, pero seguía siendo insatisfactoria en lógica simple, como la famosa "fresa" con varios tallos de "r" en ella.
Ahora, dos años después, OpenAI ha lanzado el modelo o1, que ha desatado una acalorada discusión sobre la metodología que hay detrás, con su potente capacidad de razonamiento lógico y la poderosa capacidad de ocultación de tecnología de OpenAI. En este artículo, hemos peinado algunos artículos relacionados para echar un vistazo al desarrollo de la capacidad de razonamiento complejo de los grandes modelos, utilizando como guía la especulación sobre la tecnología del modelo o1.
01 Antecedentes
La cadena de pensamiento es un concepto de la psicología cognitiva y la educación que describe el proceso gradual por el que se desarrolla el pensamiento de las personas a medida que resuelven problemas o toman decisiones. En lugar de pasar directamente de la pregunta a la respuesta, el proceso implica múltiples pasos, cada uno de los cuales puede implicar recopilar, analizar, evaluar y revisar conclusiones previas. De este modo, los individuos son capaces de abordar problemas complejos de forma más sistemática y construir soluciones racionales.
El aprendizaje supervisado, o aprendizaje supervisado, es la forma más común de entrenamiento de modelos en el campo del aprendizaje automático, ya que utiliza conjuntos de datos etiquetados para que el modelo aprenda de ellos con el fin de clasificar con precisión los datos o predecir resultados. A medida que se introducen datos en el modelo, el aprendizaje supervisado ajusta las ponderaciones del modelo hasta que éste produce un ajuste adecuado.
Supervised Fine-Tune, o SFT para abreviar, se refiere al aprendizaje supervisado en el que entrenamos un modelo con un conjunto de datos centrado en una tarea concreta sobre un modelo base existente, con vistas a su capacidad de aprender de él para resolver la tarea concreta.
Aprendizaje por refuerzoEl aprendizaje por refuerzo es uno de los tres paradigmas básicos del aprendizaje automático, junto con el aprendizaje supervisado y el no supervisado. El aprendizaje por refuerzo se centra en encontrar un equilibrio entre la exploración (lo desconocido) y la explotación (lo conocido), lo que permite a los modelos aprender los comportamientos adecuados con el objetivo de maximizar los beneficios a largo plazo.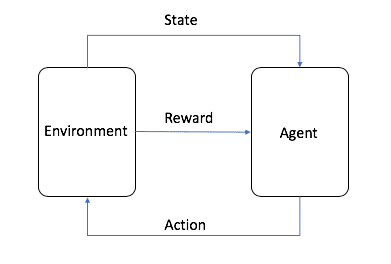
La imagen es de AWS, como se muestra en la figura, en el aprendizaje por refuerzo, el Agente es el objetivo final que necesitamos entrenar, e interactúa con el entorno establecido (Environment) y genera Recompensa y transferencia de estado, el Agente aprende en base a la Recompensa y elige mejor la siguiente Acción, por lo que el ciclo es el proceso de entrenamiento. Este ciclo es el proceso de entrenamiento del aprendizaje por refuerzo.
En el proceso de entrenamiento de LLM, RL juega un papel importante, y se ha convertido en un consenso de la industria que la fase de pre-entrenamiento se alinea con la ayuda de RLHF. En el aprendizaje por refuerzo de LLM, normalmente necesitamos otro modelo para simular el entorno para recompensar la salida de LLM, que se llama Modelo de Recompensa, o RM para abreviar.
Tendremos múltiples modelos: el modelo Actor, el modelo Crítico y el modelo Recompensa. En consonancia con el marco estándar de entrenamiento RL anterior, el Actor y el Crítico forman el Agente y la Recompensa se entrena como el Entorno en el proceso de entrenamiento RL.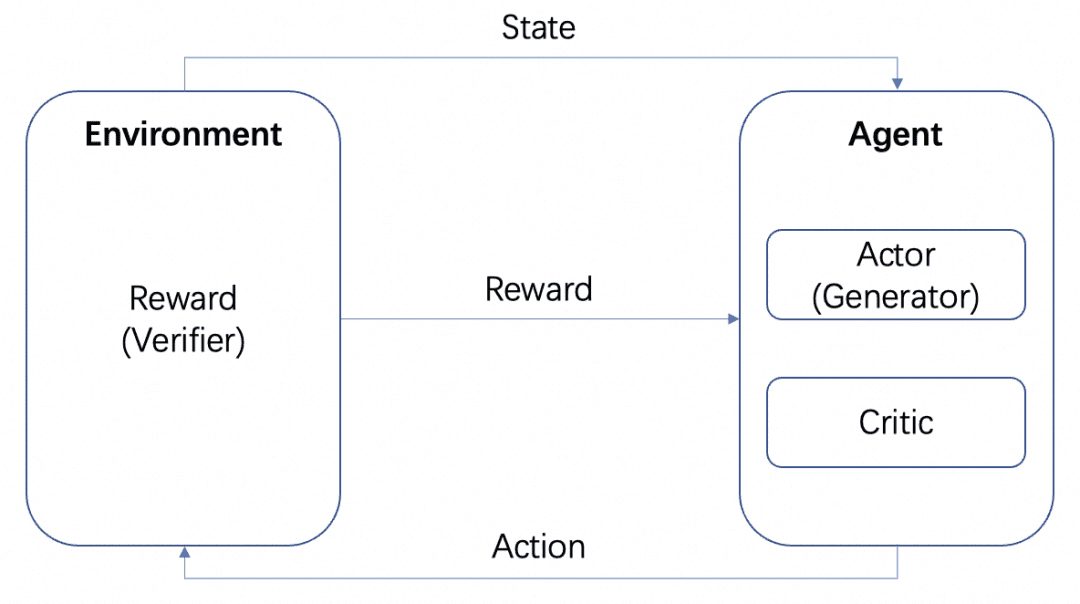
Pero después del entrenamiento, podemos desplegar modelos Actor o Recompensa por separado, donde el modelo Actor es nuestro Generador y el modelo Recompensa es el Verificador que usamos para medir la calidad de la generación del Generador, que es la estructura Generador-Verificador que menciona OpenAI en el paper Verifiquemos paso a paso. Esta es la estructura Generador-Verificador mencionada en el documento de OpenAI Verifiquemos paso a paso.
Y los modelos de recompensa pueden clasificarse en función de lo detallados que sean sus comentarios:
-Modelo de Recompensa Basado en Procesos PRM: PRM da retroalimentación basada en los resultados intermedios de LLM.
-Outcome Based Reward Model ORM: ORM da feedback sólo después del resultado final.
A continuación abordamos estos dos conceptos en escenarios específicos.
Monte Carlo Tree Search Monte Carlo Tree Search, o MCTS, es un algoritmo de búsqueda en árbol con la idea central de que, en cada paso, se intentan múltiples comportamientos y se predicen los posibles pagos futuros de los comportamientos, centrándose en la exploración selectiva de algunos de los comportamientos más gratificantes.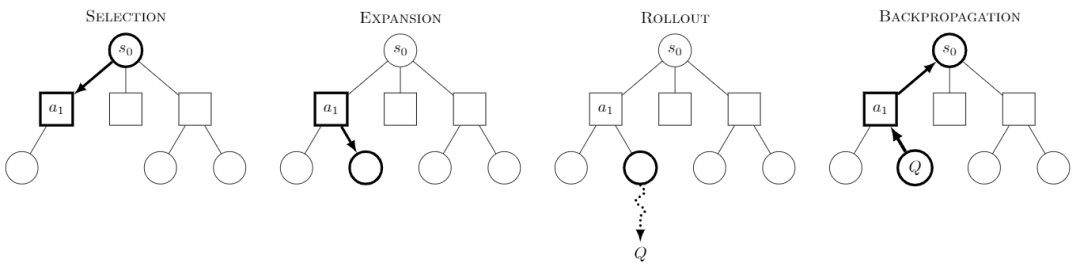
Imagen de Wikipedia. Se dice que cada búsqueda se divide en cuatro pasos:
-Selección: seleccionar un nodo
-Expansión: genera un nuevo nodo a partir de este nodo para ser explorado.
-Rollout: realizar una simulación a lo largo de este nuevo nodo para producir un resultado.
-Propagación hacia atrás: los resultados de la simulación se propagan hacia atrás, actualizando los nodos de las rutas.
Explorando continuamente, obtenemos un árbol y cada nodo tiene un posible resultado de la exploración y podemos buscar en este árbol para obtener el mejor camino o resultado.
MCTS para RL ha producido modelos bien conocidos como AlphaZero, que realiza los pasos de Selección y Despliegue utilizando modelos entrenables, reduciendo así el gran espacio de búsqueda y el coste de simulación de MCTS para obtener eficientemente la solución óptima. El enfoque de AlphaZero consiste en utilizar modelos entrenables para realizar los pasos de Selección y Despliegue, reduciendo así el gran espacio de búsqueda y el coste de simulación de MCTS para obtener eficientemente la solución óptima, por ejemplo, utilizando la Red de Políticas para buscar eficientemente el siguiente paso posible, y utilizando la Red de Valores para determinar el valor de cada paso en lugar de la simulación de Despliegue.
Capacidad de razonamiento multipaso de o1 Cuando se trata del modelo o1, tenemos que hablar de su asombrosa capacidad de razonamiento multipaso, y el sitio web de OpenAI da varios ejemplos para mostrar su capacidad de razonamiento multipaso en contraseñas, códigos, matemáticas, crucigramas, etc. El ejemplo relacionado con "contraseñas" es "HAY TRES R'S EN STRAWBERRY", que también es un buen ejemplo de cómo se descodificaba antes. En el ejemplo relacionado con "password", el resultado de la descodificación es "THERE ARE THREE R'S IN STRAWBERRY", que también es el resultado de la otrora "password". ChatGPT Capacidad de razonamiento para responder.
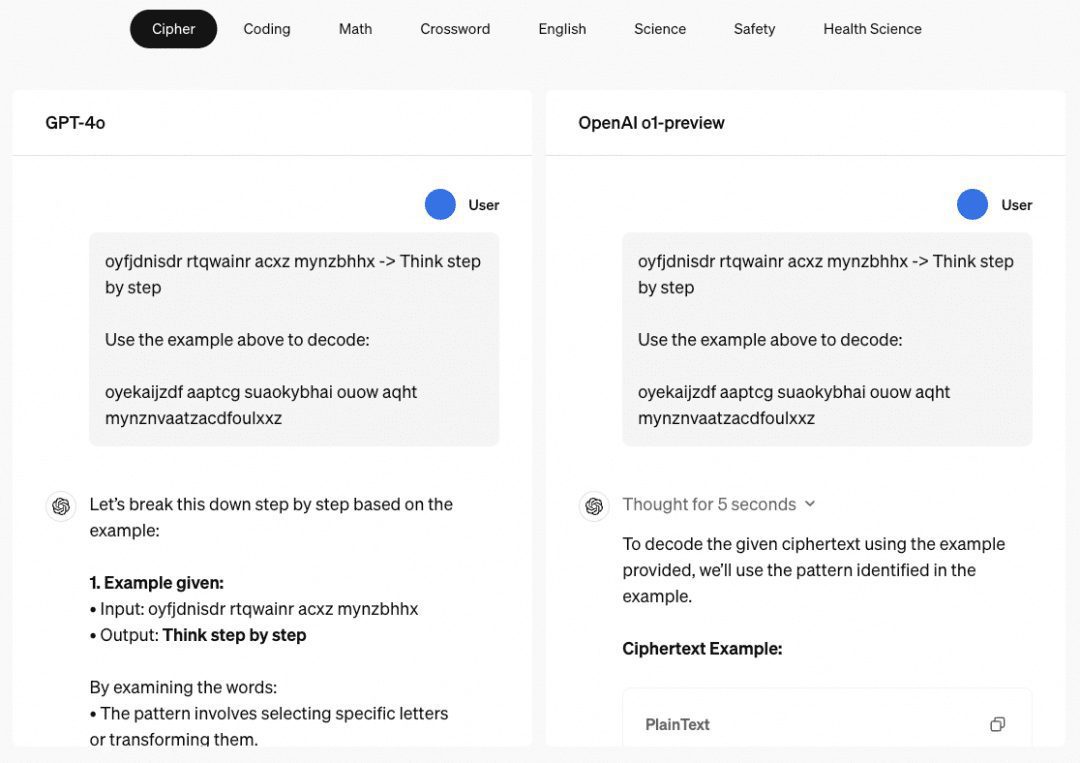
Por lo tanto, hemos estudiado una serie de documentos principalmente en este sentido, cotejados y resumidos como se describe a continuación.
02 Palabra clave ingeniería
Antes de introducir la ingeniería de palabras clave utilizada para mejorar la capacidad de inferencia del modelo, tenemos que entender qué es el aprendizaje de pocos ejemplos (Few-Shot Learning). En la actualidad, el entrenamiento de la IA suele requerir una gran cantidad de datos de ejemplo, mientras que si el aprendizaje se realiza utilizando sólo una cantidad muy pequeña de datos de ejemplo, se conoce como Few-Shot, o Zero-Shot, si no se dan ejemplos en absoluto.
El artículo "Chain of Thought Prompting Elicits Reasoning in Large Language Models" propone un enfoque de Pocos Tiros para mejorar el razonamiento matemático de los modelos:
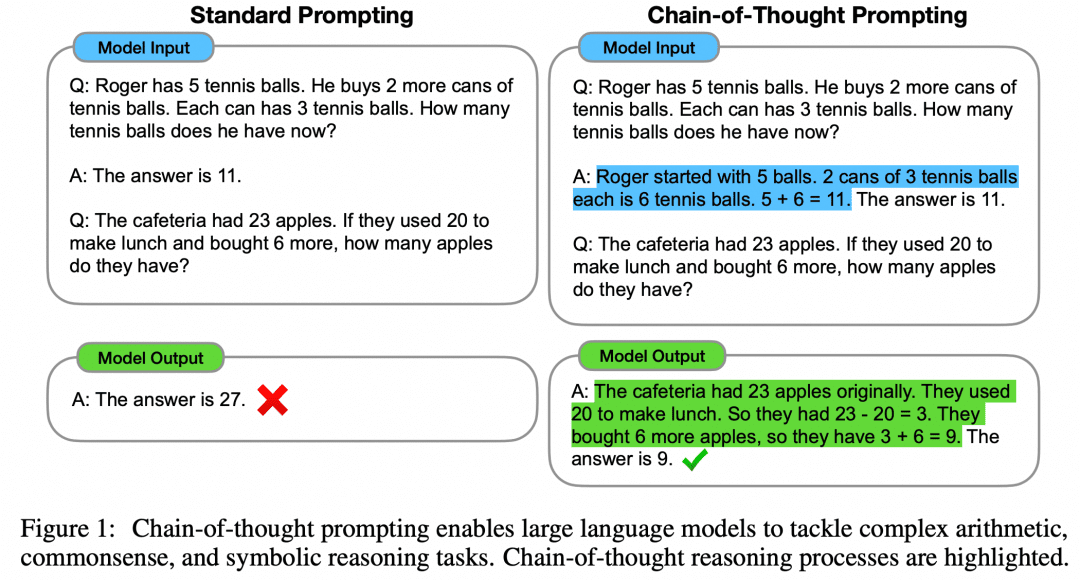
Como se muestra en la figura, el lado izquierdo da una muestra para que LLM aprenda en el Prompt de entrada LLM, que es Few-Shot Learning, pero su efecto sigue siendo insatisfactorio. El artículo propone este paradigma Few-Shot con CoT en el lado derecho. Así, a la derecha, en Few-Shot, no sólo se dan la pregunta y la respuesta de un ejemplo, sino también el proceso intermedio y el resultado. Los autores descubrieron que la Few-Shot Prompt construida de este modo utilizando CoT mejora la inferencia del modelo.
A medida que el propio modelo mejora y se realizan más investigaciones, el artículo "Large Language Models are Zero-Shot Reasoners" revela además que Zero-Shot también puede utilizar CoT para mejorar las capacidades del modelo:

En lugar de tomarse la molestia de construir un proceso intermedio de CoT, o incluso de construir ejemplos para Few-Shot, un simple "Pensemos paso a paso" puede mejorar el LLM. Parece una obviedad. Este Prompt fue tomado más tarde y cambiado por OpenAI a "Verifiquemos paso a paso", y este documento es ahora el núcleo de repetidas lecturas por cualquiera que quiera entender o1.
Por supuesto, construir CoT sobre la ingeniería de palabras clave no puede ser la única razón por la que o1 es tan potente, pero CoT, un enfoque paso a paso para avanzar en la lógica, se ha convertido en la dirección dominante para aumentar el razonamiento en grandes modelos.
03 CoT + Ajuste fino supervisado
Por supuesto, ha habido intentos de enseñar las capacidades de razonamiento multipaso de CoT a los LLM utilizando SFT. "STaR: Bootstrapping Reasoning With Reasoning" es un primer intento. La imagen de abajo es de ese documento: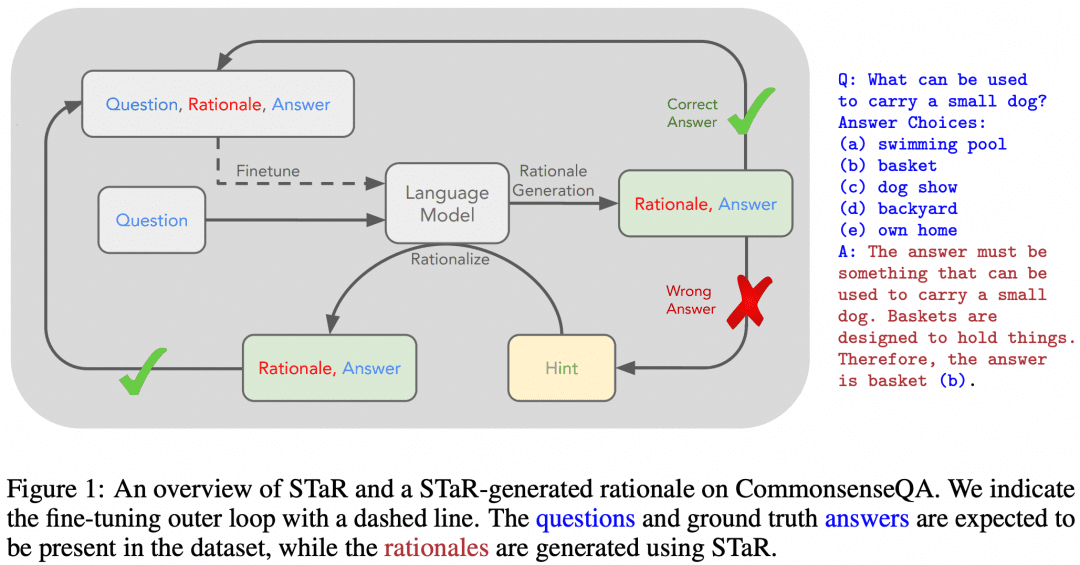
La idea del artículo es la siguiente. En primer lugar, utilizamos el enfoque de ingeniería de palabras clave descrito anteriormente para que el modelo intente razonar con CoT sobre el conjunto de datos, lo que dará lugar a un lote de respuestas que, naturalmente, tendrá respuestas correctas e incorrectas:
Si obtenemos una respuesta correcta, consideramos que el CoT correspondiente generado por el modelo es un CoT de alta calidad; a continuación, recopilamos dichas muestras de "pregunta-CoT-respuesta" de alta calidad para obtener un nuevo conjunto de datos, y utilizamos este conjunto de datos para SFT nuestro LLM, y continuando con el bucle, podemos obtener el LLM con mejor capacidad de razonamiento. LLM;
Si hay algunas preguntas que el LLM siempre responde incorrectamente, entonces dejamos que el LLM vea directamente la "Pregunta+Respuesta", y dejamos que genere una CoT desde la pregunta hasta la respuesta, y podemos pensar que la CoT generada por el LLM es correcta cuando se conoce la respuesta, y esta parte de la muestra "Pregunta-CoT-Respuesta" también se puede utilizar para el entrenamiento. La muestra "Pregunta-CdT-Respuesta" también puede utilizarse para el entrenamiento.
Como este estudio es bastante antiguo, ahora es fácil encontrarle las lagunas, por ejemplo, LLM en realidad tiene a menudo "proceso erróneo pero resultado correcto" o "proceso correcto pero resultado erróneo", lo que significa que las muestras que utilizamos para el entrenamiento de arriba en realidad no son de tan alta calidad. Esto significa que las muestras que utilizamos para el entrenamiento anterior no son realmente de tan alta calidad. Entonces, ¿cómo conseguir un proceso de inferencia más correcto?
04 Búsqueda en árbol Monte Carlo
Hemos aprendido más arriba que el CdT descompone la lógica que va de la pregunta a la respuesta en un proceso de pensamiento intermedio tras otro proceso de pensamiento intermedio, así que ¿puede utilizarse el MCTS para buscar el mejor paso de pensamiento para el siguiente paso de razonamiento y, por tanto, la mejor cadena de pensamientos de razonamiento? Naturalmente, sí.
Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers idearon un algoritmo MCTS de este tipo, llamado rStar, y publicaron el proyecto en GitHub. La imagen de abajo es del artículo, y ¿no se parece a la imagen MCTS de arriba?
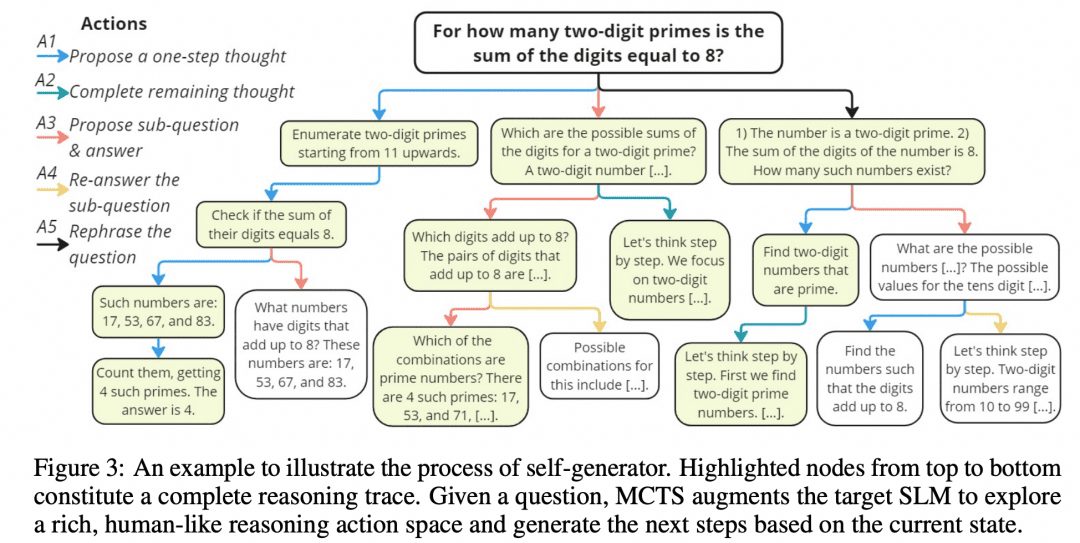
Como muestra la figura anterior, los investigadores dividieron los pasos intermedios de CoT en 5 tipos de nodos:
1. Generar los siguientes pasos en el razonamiento
2. Generar todos los razonamientos posteriores
3. Genere una subpregunta y una respuesta
4. Volver a responder a las subpreguntas
5. Problemas de reconfiguración
A continuación, se utiliza el MCTS para determinar el siguiente nodo de pensamiento. El camino enlazado por nodo tras nodo de pensamiento es el CoT. simplemente tomamos todos los resultados finales obtenidos y los votamos.
Por supuesto, los autores estudiaron más que eso, como se mencionó anteriormente, es necesario poder medir la corrección de los nodos y la corrección del razonamiento en cada paso, y los investigadores idearon el siguiente método:
-Filtrado discriminante: después de la ruta de inferencia original obtenida, Mask al azar una parte de ella, y luego usar otro modelo para la salida, si obtenemos el mismo resultado que el Generador original, entonces la ruta de inferencia original es fiable.
-Corrección de la respuesta: se recopilan todas las respuestas finales y la proporción de una respuesta concreta con respecto a todas las respuestas es la puntuación de la respuesta.
-Corrección del proceso: para cada nodo de razonamiento de la ruta, se genera en paralelo un número de nodos de tipo 2 para generar un número de resultados finales de un paso, y la proporción de estos resultados que son el resultado final de la ruta actual se considera la puntuación del proceso de ese nodo de razonamiento. La medida en tres partes conduce a un camino óptimo, y el resultado final del camino óptimo se considera el resultado del MCTS.
05 Generador + Verificador
Además del MCTS anterior, que permite organizar los procesos de pensamiento en árboles y explorarlos, hay otras formas de hacerlo. El aprendizaje por refuerzo, por ejemplo, y de nuevo nos fijamos en la introducción al aprendizaje por refuerzo: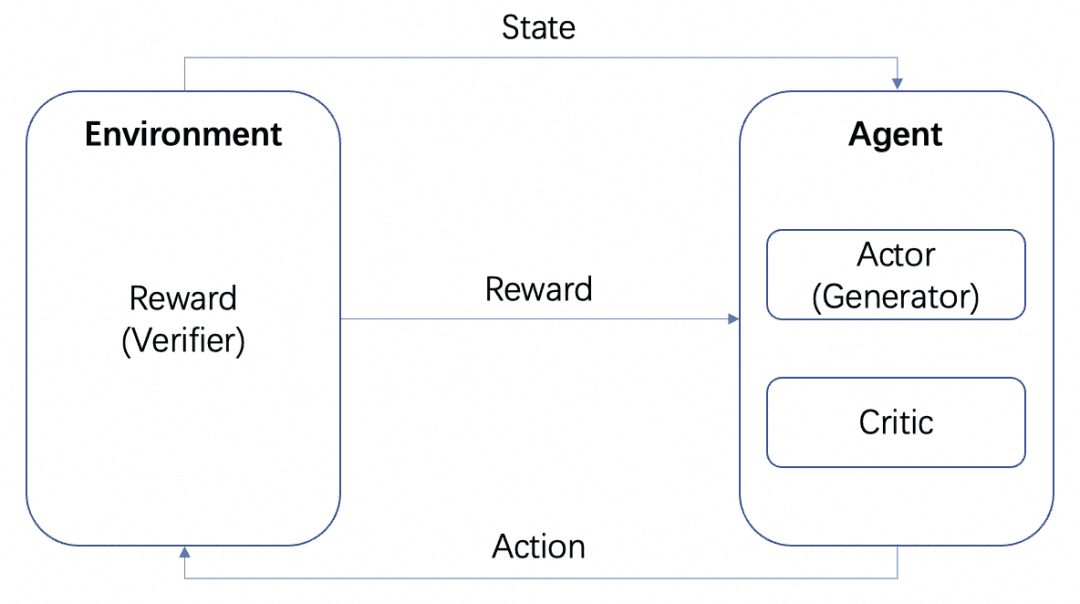
Si tomamos el LLM como el Actor, otro MR entrenado en el problema como el Entorno, y un Crítico implícito, un bucle de aprendizaje por refuerzo sería: el Actor produce un resultado para el problema, el MR verifica la corrección del resultado y lo devuelve al Agente, y el Actor y el Crítico se entrenan en función de la Recompensa. El Actor y el Crítico se entrenan en función de la Recompensa. Nos referimos al Agente como Generador, porque su tarea es generar el resultado, y al MR como Verificador, porque su tarea es verificar el resultado.
Si lo piensas, ¿no es la relación entre Actor y Crítico dentro de un Agente muy similar a la red de Política y Valor utilizada por AlphaZero? También es cierto que las redes de Política y Valor encajan en el marco de Actor y Crítico.
Ahora resumimos que en un proceso de aprendizaje por refuerzo intervienen tres redes: Actor, Crítico y MR. En el despliegue, se utilizan diferentes marcos dependiendo de la situación: en un juego de mesa, el ganador sólo puede conocerse al final del juego, y la recompensa dada por el MR es demasiado pequeña, por lo que optamos por mantener el marco Actor-Crítico en el despliegue, y luego llevar a cabo el MCTS para una mejor solución; mientras que en el despliegue LLM, nuestro MR entrenado puede proporcionar retroalimentación oportuna, por lo que podemos combinar naturalmente el Actor y el MR en un marco Generador-Verificador en el despliegue. En el despliegue LLM, nuestro MR entrenado puede proporcionar retroalimentación oportuna, por lo que podemos combinar de forma natural el Actor y el MR en el marco Generador-Verificador en el momento del despliegue.
OpenAI lleva trabajando en esta dirección desde los tiempos de GPT3 (ChatGPT se basa en el modelo GPT-3.5). La solución que dieron fue el documento Training Verifiers to Solve Math Word Problems. La imagen de abajo es de ese documento:
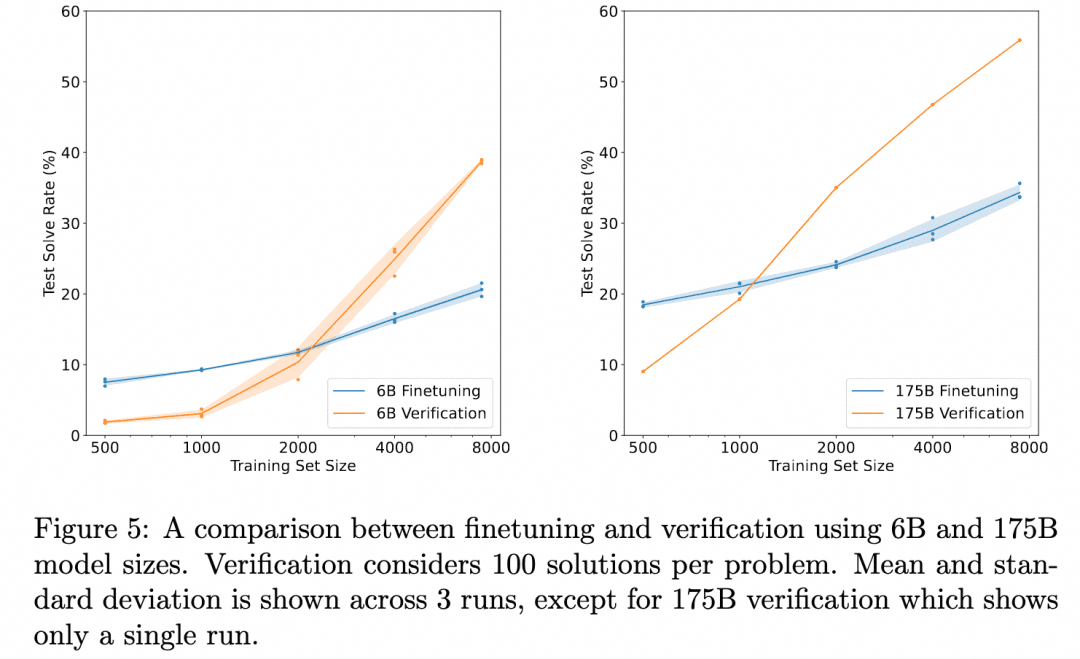
El gráfico anterior compara: "Corrección de los resultados obtenidos simplemente ajustando el Generador" con "Corrección de los resultados obtenidos ajustando un Verificador, evaluando múltiples resultados producidos por el Generador y seleccionando el resultado más valorado". Esto demuestra la eficacia del verificador.
Esto se debe a que la tarea aquí es: razonar sobre el problema para obtener el resultado. Así que el Generador utilizado no produce un proceso de razonamiento intermedio sino que produce el resultado directamente, y el Verificador es también el ORM (Modelo de Recompensa Basado en Resultados) que mencionamos en la sección sobre Aprendizaje por Refuerzo, que sirve para producir una puntuación basada en el resultado del Generador. Así que no hay un proceso de inferencia de múltiples pasos que queramos explorar, sólo el descubrimiento de que la validación ORM produce mejores resultados finales que un simple ajuste fino.
Así que el equipo de OpenAI fue un paso más allá: por un lado, hicieron que el Generador ya no emitiera resultados directamente, sino que produjera un razonamiento paso a paso; por otro lado, entrenaron a un PRM (Process-based Reward Model) para que actuara como Verificador, cuyo papel es producir una puntuación para cada paso en el proceso de razonamiento del Generador. Creemos que los resultados producidos buscando la corrección en el proceso de razonamiento del Generador de esta manera son los que tienen más probabilidades de ser correctos.
Este es el Verifiquemos paso a paso que mencionamos antes. En este trabajo, el equipo comparó los resultados de inferencia generados al buscar en el mismo Generador con PRM y ORM como Verificadores (en este punto, su Generador ya era GPT-4), y demostró que PRM como Verificador buscaba resultados más precisos. La figura siguiente procede del artículo:
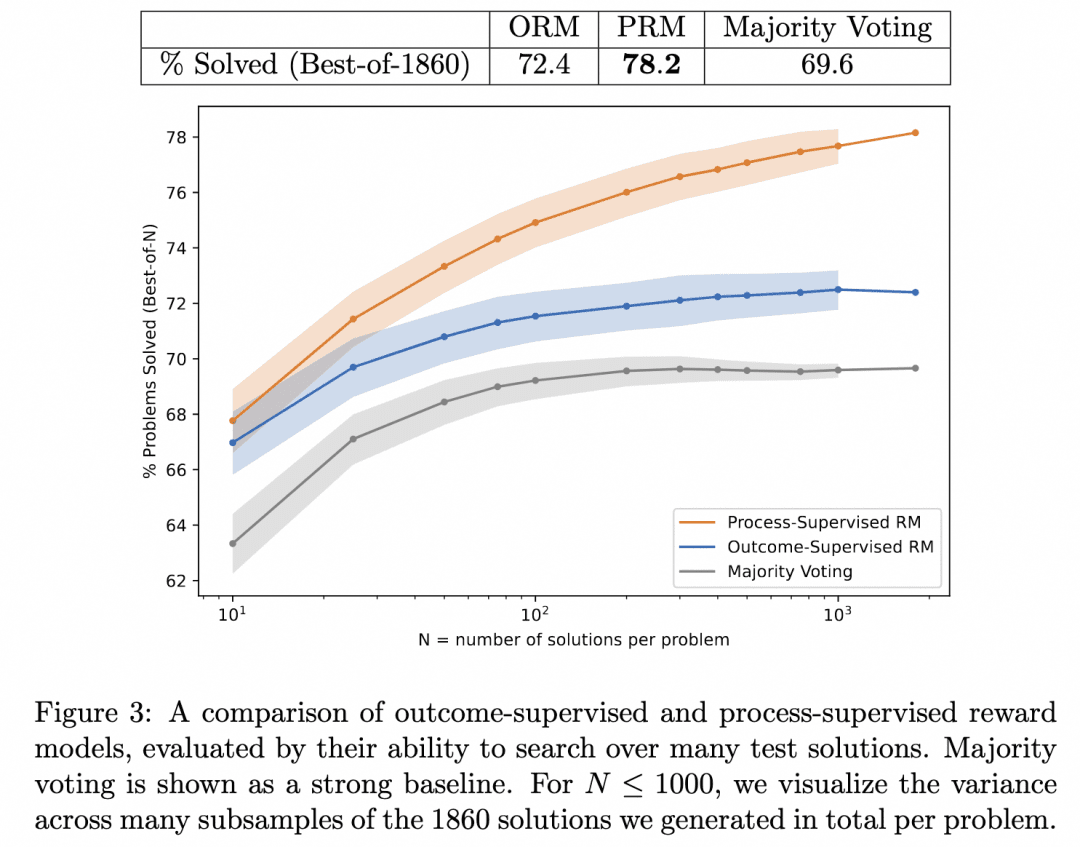
La figura anterior ilustra que el mismo Generador de inferencia por pasos produce resultados en los que es válido que utilicemos el ORM como Verificador para elegir la mejor respuesta para el resultado, ¡pero tenemos más probabilidades de acertar cuando utilizamos el PRM como Verificador para elegir la mejor respuesta para el proceso!
¿Es esta la tecnología detrás del o1 que estamos buscando? En este momento sólo podemos suponer que se trata de una de las tecnologías básicas que lo sustentan. Las razones son las siguientes:
1, este documento está relativamente lejos del lanzamiento de o1, y un año es tiempo suficiente para que los investigadores de OpenAI profundicen en esta dirección. Debido a la validez de la PMR, aunque un año también es tiempo suficiente para ajustarse a otras direcciones, seguimos pensando que están profundizando más que dando la vuelta.
2. El documento demuestra la eficacia de la PMR como verificador, y está claro que el siguiente paso podría ser mejorar el generador con un verificador potente para producir mejores resultados. Pero el documento no va allí, así que tenemos razones para creer que OpenAI debe haberlo intentado, y no está claro si el resultado fue o1.
Con estas conjeturas fuera del camino, pasemos a explorar otras formas de utilizar Verifier para la búsqueda. El artículo "Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters" de Google DeepMind del pasado agosto hace más investigación. Muchos consideran que este artículo muestra una línea técnica similar a los principios en los que se basa o1. La imagen de abajo es de ese documento:
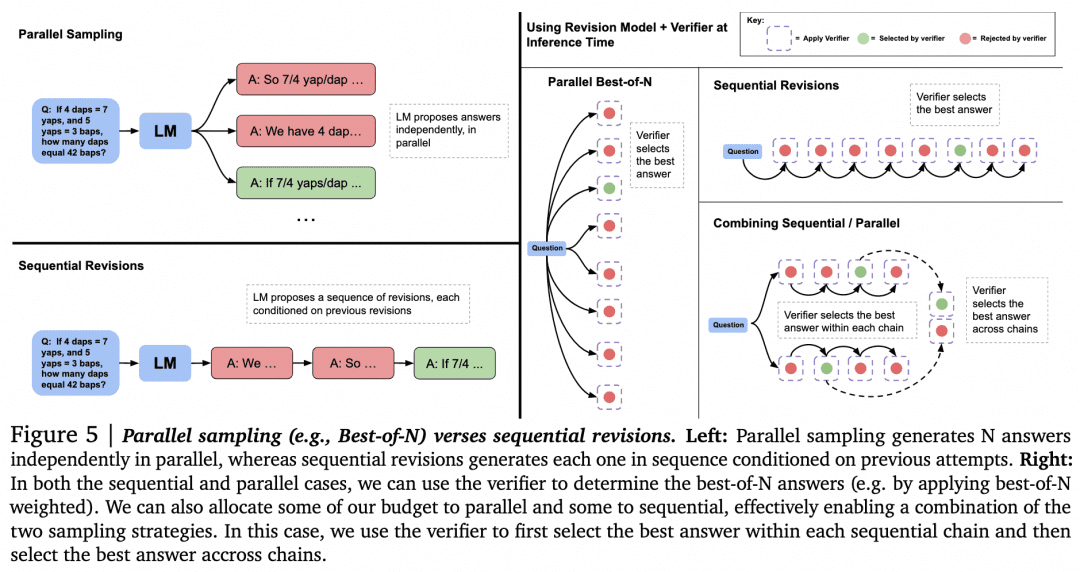
Ahora que tenemos un Generador y un Verificador, ¿cómo conseguimos que trabajen entre sí para obtener los mejores resultados? Una forma de hacerlo, como ya se ha mencionado, es que el Generador muestree en paralelo para obtener múltiples resultados, y que el Verificador los evalúe y elija la puntuación más alta. Este es el enfoque de Muestreo paralelo + Mejor de N que aparece a la izquierda en la figura anterior. Pero obviamente hay otros enfoques:
-Al generar múltiples resultados, además de muestrear múltiples resultados en paralelo, también es posible que el Generador genere un resultado y luego compruebe y corrija el propio resultado para obtener una secuencia de respuestas, donde ya no están en paralelo entre sí.
-Puede haber alternativas a Mejor-de-N cuando la selección la hace el Verificador. Como se muestra en la siguiente figura del documento:
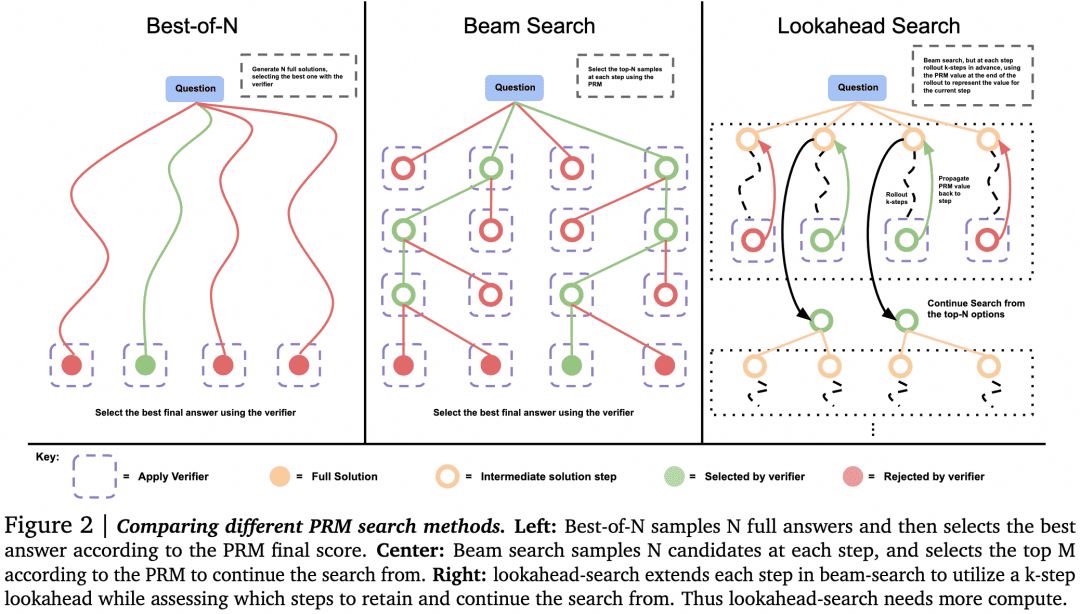
El documento concluyó que, para problemas sencillos, deberíamos utilizar Verifier para animar a Generator a autocomprobar y corregir, en lugar de buscar ciegamente en paralelo. Para problemas complejos, es mejor que Generator pruebe distintas soluciones en paralelo.
Un trabajo similar es A Comparative Study on Reasoning Patterns of OpenAI's o1 Model. El equipo del artículo publicó Open-o1, una réplica de o1, en GitHub, y este artículo es el resultado de algunas de sus investigaciones tras la publicación de o1. La imagen de abajo es del artículo:
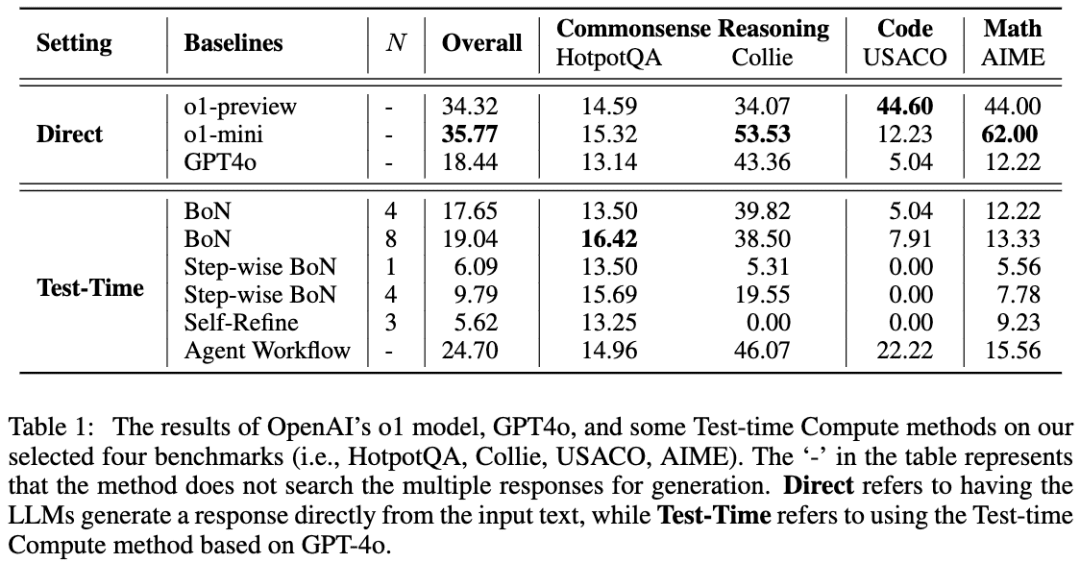
El equipo utilizó GPT-4o como modelo básico y comparó sus resultados utilizando cuatro enfoques comunes para conseguir que los LLM piensen antes de razonar. El equipo descubrió que, en la tarea HotpotQA, los enfoques Best-of-N y Step-wise BoN mejoraban significativamente el razonamiento de los LLM, y que BoN incluso hacía que GPT-4o superase al modelo o1.
06 OpenR
De los actuales proyectos de código abierto que intentan replicar o1, OpenR es uno de los que tiene un grado de realización relativamente alto.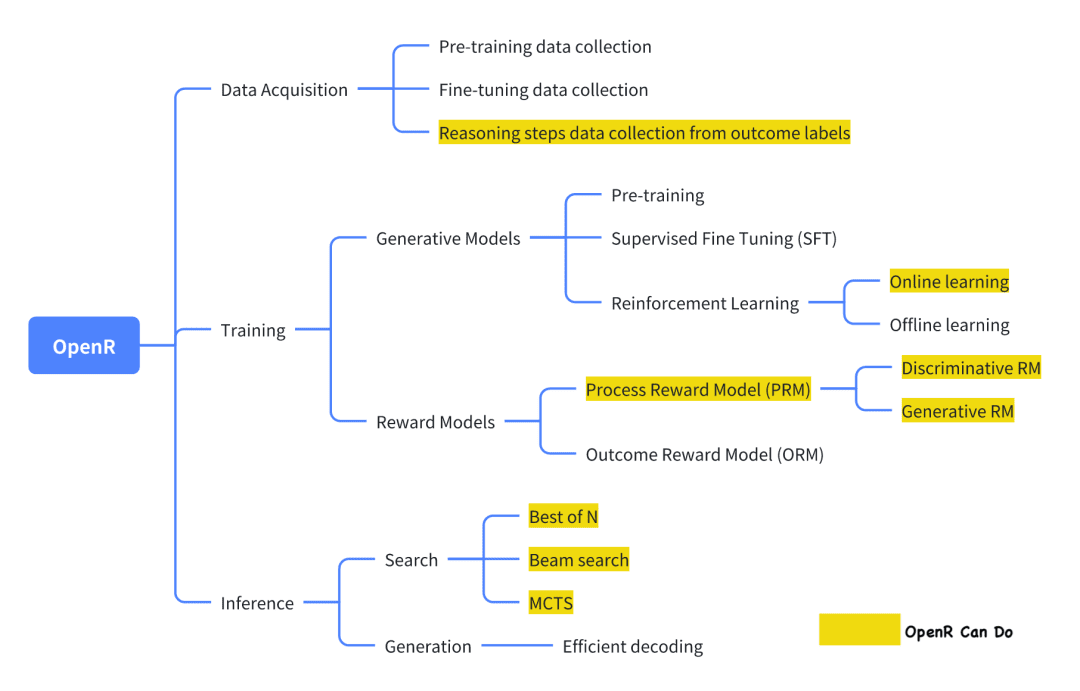
La imagen procede de su documentación oficial, que, en su versión actual, implementa la recogida de datos, así como la formación y el despliegue, de acuerdo con el marco Generator-Verifier.
Recogida de datos Según la introducción oficial, el método de recogida de datos procede del artículo: 'Improve Mathematical Reasoning in Language Models by Automated Process Supervision'. En resumen, se trata de utilizar MCTS para ampliar el conjunto de datos original problema-respuesta_final para generar pasos de inferencia CoT. Finalmente, se obtiene un conjunto de datos MATH-APS.
Los conjuntos de datos pertinentes se han alojado en ModelScope:
Conjunto de datos PRM800K-Stepwise:
https://modelscope.cn/datasets/AI-ModelScope/openai-prm800k-stepwise-critic/
Conjunto de datos MATH-APS:
https://modelscope.cn/datasets/AI-ModelScope/MATH-APS/
Conjunto de datos Math-Shepherd:
https://modelscope.cn/datasets/AI-ModelScope/Math-Shepherd
El equipo de entrenamiento del Generador utiliza una variante del algoritmo PPO del aprendizaje por refuerzo para entrenar al Generador. En resumen, el algoritmo PPO utiliza la información de Recompensa proporcionada por el Modelo de Recompensa para entrenar al Generador, y al mismo tiempo restringe al Actor para que no se desvíe demasiado del Actor original durante el proceso de aprendizaje, para evitar perder el conocimiento existente. Actualmente, OpenR admite tres variantes: APPO, GRPO y TPPO.
El equipo de formación de Virifier utilizó el aprendizaje supervisado SFT para entrenar a un PRM utilizando el conjunto de datos MATH-APS mencionado anteriormente, así como dos conjuntos de datos de código abierto, PRM800K y Math-Shepherd. Específicamente, en estos tres conjuntos de datos a nivel de pasos, el equipo etiquetó cada paso con una etiqueta "+" o "-", y luego hizo que el PRM aprendiera a predecir la etiqueta de cada paso y determinara si era correcta o incorrecta.
El modelo utiliza datos "escalonados" para el entrenamiento PPO, y los pesos resultantes del modelo se han alojado en ModelScope, que actualmente proporciona puntos de control para modelos SFT, PRM y RL, así como algunos formatos GGUF:
El modelo mistral-7b-sft:
https://modelscope.cn/models/AI-ModelScope/mistral-7b-sft
Modelo RL (versión GGUF):
https://modelscope.cn/models/QuantFactory/math-shepherd-mistral-7b-rl-GGUF
Modelización de PMR:
-Versión GGUF: https://modelscope.cn/models/QuantFactory/math-shepherd-mistral-7b-prm-GGUF
-Modelo PRM: https://modelscope.cn/models/AI-ModelScope/math-shepherd-mistral-7b-prm
Despliegue del razonamiento En el momento del despliegue, OpenR utiliza algoritmos de búsqueda a través del Generador y Verificador especificados para obtener el proceso de razonamiento y la respuesta final. Actualmente, se admiten MCTS, Beam Search y best_of_n.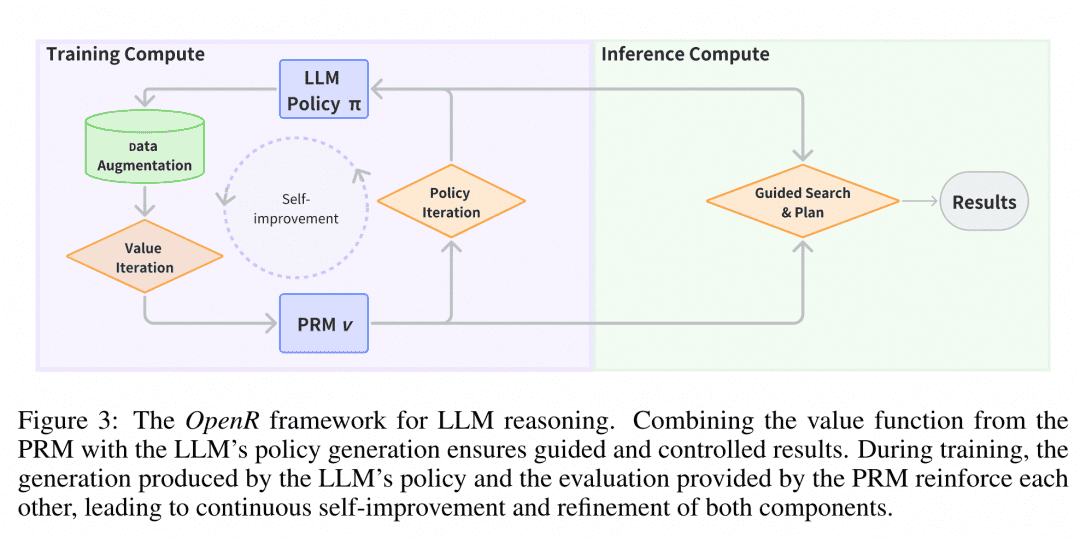
La imagen procede del artículo "OpenR: An Open Source Framework for Advanced Reasoning with Large Language Models". La estructura de OpenR se muestra en la figura, y hasta ahora, OpenR implementa una réplica de la cadena de O1, desde la recopilación de datos de entrenamiento hasta el entrenamiento de una PRM, pasando por el uso de la PRM para reforzar el aprendizaje y, finalmente, el despliegue del modelo. OpenR implementa actualmente una cadena que replica la de O1, desde la recopilación de datos de entrenamiento, pasando por el entrenamiento de una PRM, hasta el uso de la PRM para reforzar el aprendizaje y el despliegue del modelo para la búsqueda, y el equipo ha hecho que todo este trabajo sea de código abierto para que la comunidad aprenda de él y lo pruebe, de modo que podamos echar un vistazo.
Experiencia en el Espacio CreativoHemos desplegado el servicio de inferencia de OpenR en el Espacio Creativo de la Comunidad Magic Hitch, y los desarrolladores pueden experimentar los efectos de OpenR en línea visitando el siguiente enlace: https://www.modelscope.cn/studios/modelscope/OpenR_Inference.
07 Conclusión
Los artículos anteriores sobre razonamiento multipaso que hemos investigado demuestran que permitir a LLM razonar paso a paso en lugar de saltarse procesos intermedios puede mejorar significativamente su precisión en problemas relacionados con la lógica. Para permitir a LLM razonar paso a paso, podemos afinarlo utilizando algunos conjuntos de datos con procesos intermedios, además de guiarlo con una simple ingeniería de palabras clave. Más eficientemente, podemos entrenar un Verificador que pueda verificar paso a paso la precisión del Generador para buscar los resultados generados por el Generador.
Por las especulaciones y los documentos publicados hasta ahora, parece que la tecnología probable para avanzar hacia o1 se basa precisamente en la cooperación entre el potente Generador LLM y el Verificador LLM. Este tipo de pie izquierdo-pie derecho, auto iteración contra sí mismo no es la primera vez en el campo del aprendizaje profundo, pero OpenAI es el primero en introducir un modelo de este tipo en el campo LLM, que es muy caro solo para entrenar al Generador, que es realmente un gran generador de dinero.
Por lo tanto, creemos que si queremos replicar o1, lo primero que necesitamos es un Verificador que pueda proporcionar asistencia y guía al Generador, y con el fin de generar los datos necesarios para entrenar al Verificador, podemos referirnos a los capítulos anteriores CoT + Supervised Fine-Tune y Monte Carlo Tree Search para obtener datos de mayor calidad a un menor coste. Para generar los datos necesarios para entrenar al Verificador, podemos remitirnos a los capítulos anteriores CoT + Supervised Fine-Tune y Monte Carlo Tree Search para obtener datos de mayor calidad a un coste menor. Por eso hemos presentado también estas tareas.
Finalmente presentamos un proyecto de código abierto muy acabado, y basándonos en su trabajo pudimos organizar nuestros pensamientos e ideas.
08 Referencia
La cadena de pensamiento suscita el razonamiento en grandes modelos lingüísticos
Los grandes modelos lingüísticos son razonadores de disparo cero
STaR: Razonamiento de arranque con razonamiento
El razonamiento mutuo hace que los LLM más pequeños resuelvan mejor los problemas
Entrenamiento de verificadores para resolver problemas matemáticos
Verifiquemos paso a paso
Escalar óptimamente el cálculo del tiempo de prueba del LLM puede ser más eficaz que escalar los parámetros del modelo
Estudio comparativo de los patrones de razonamiento del modelo o1 de OpenAI
OpenR: un marco de código abierto para el razonamiento avanzado con grandes modelos lingüísticos
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados




Sin comentarios...