Cognita: un marco de código abierto para construir aplicaciones modulares de GAR y probar rápidamente diversas estrategias de GAR.
Últimos recursos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 58.9K 00

Introducción general
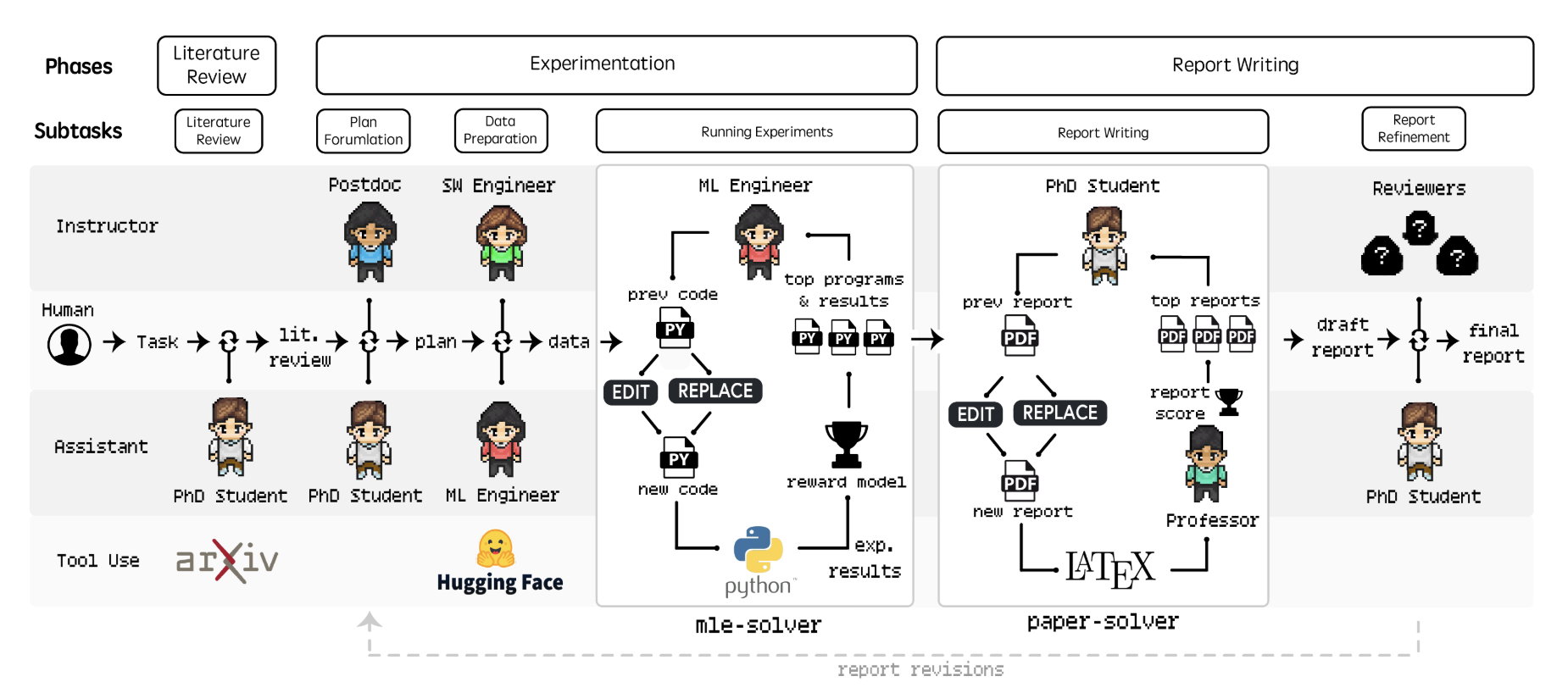
Cognita es un framework de código abierto desarrollado por TrueFoundry para simplificar el desarrollo de aplicaciones basadas en RAG (Retrieval-Augmented Generation). El marco proporciona una solución estructurada y modular que facilita la incorporación de la RAG Cognita admite múltiples fuentes de datos, analizadores sintácticos y modelos incrustados, y ofrece una interfaz de usuario fácil de usar que permite a los usuarios no técnicos experimentar con las configuraciones de la GAR. Se integra a la perfección con los sistemas existentes, admite la indexación incremental y múltiples bases de datos vectoriales, y ayuda a los desarrolladores a lograr una rápida iteración y despliegue en el desarrollo de aplicaciones de IA.
Referenciando diferentes estrategias RAG basadas en la modularidad de Langchain/LlamaIndex y proporcionando una interfaz fácil de usar para probar y liberar rápidamente aplicaciones de nivel de producción.



Lista de funciones
- Diseño modular: dividir la aplicación RAG en módulos independientes, como el cargador de datos, el analizador sintáctico, el incrustador y el recuperador, para mejorar la reutilización y el mantenimiento del código.
- Interfaz de usuario intuitiva: Ofrece una interfaz visual que permite a los usuarios cargar documentos y realizar operaciones de preguntas y respuestas fácilmente.
- Controlador API: Admite un controlador API completo, fácil de integrar con otros sistemas.
- Indexación incremental: sólo se vuelven a indexar los documentos modificados, lo que ahorra recursos informáticos.
- Compatibilidad con múltiples fuentes de datos: cargue datos desde múltiples fuentes de datos, como directorios locales, S3, bases de datos, etc.
- Compatibilidad multimodelo: incluye OpenAI, Cohere y otros modelos integrados, así como compatibilidad con modelos lingüísticos.
- Integración con bases de datos vectoriales: integración perfecta con bases de datos vectoriales como Qdrant, SingleStore y otras.
Utilizar la ayuda
Proceso de instalación
Dado que Cognita es un proyecto Python de código abierto, el proceso de instalación implica los siguientes pasos:
- almacén de clones::
git clone https://github.com/truefoundry/cognita.git cd cognita - Crear un entorno virtual(Práctica recomendada):
python -m venv .cognita_env source .cognita_env/bin/activate # Unix .cognita_env\Scripts\activate # Windows - Instalación de dependencias::
pip install -r requirements.txt - Configuración de variables de entorno::
- Copie .env.example en el archivo .env y configúrelo según sus necesidades, como la clave API, la conexión a la base de datos, etc.
Normas de uso
Carga de datos:
- Elija una fuente de datos: Cognita admite la carga de datos desde archivos locales, cubos de almacenamiento de S3, bases de datos o artefactos de TrueFoundry. Elige el tipo de fuente de datos que más te convenga.
- Cargue o configure los datos: si elige un archivo local, cargue el archivo directamente. Si es otra fuente de datos, configura los derechos de acceso y la ruta.
Análisis de datos:
- Seleccionar analizador sintáctico: Según el tipo de documento (por ejemplo, PDF, Markdown, archivo de texto), seleccione el analizador sintáctico adecuado.Cognita admite por defecto el análisis sintáctico de múltiples formatos de archivo.
- Realizar análisis sintáctico: Haga clic en el botón Análisis sintáctico y el sistema convertirá el documento a un formato uniforme.
Incrustación de datos:
- Seleccionar modelo incrustado: Seleccione el modelo incrustado (por ejemplo, el modelo de OpenAI u otros modelos de código abierto) según sus necesidades.
- Generar incrustación: realiza operaciones de incrustación para convertir el texto en una representación vectorial para su posterior recuperación.
Consulta y recuperación:
- Introduzca una consulta: Introduzca su consulta en la interfaz de usuario o a través de la API.
- Recuperar información relevante: el sistema recuperará los fragmentos de documentos más relevantes de la base de datos según su consulta.
- Generar respuestas: Utiliza el modelo lingüístico seleccionado para generar respuestas basadas en los segmentos recuperados.
Indexación incremental:
- Supervisar los cambios en los datos: Cognita ofrece la posibilidad de indexar sólo los documentos nuevos o actualizados, lo que aumenta la eficacia y ahorra recursos informáticos.
Funcionamiento de la interfaz de usuario:
- Gestionar colecciones: puede crear, eliminar o editar colecciones de documentos en la interfaz de usuario.
- Funcionamiento de preguntas y respuestas: los usuarios pueden experimentar los efectos del sistema GAR mediante preguntas y respuestas directamente desde la interfaz.
Función destacada Operación
- Soporte multilingüe: Si sus datos contienen varios idiomas, puede aprovechar el soporte multilingüe de Cognita para realizar preguntas y respuestas multilingües.
- Cambio dinámico de modelos: Cognita le permite cambiar entre diferentes modelos de incrustación o de lenguaje a petición, sin tener que volver a desplegar toda la aplicación.
Con los pasos y funciones descritos anteriormente, los usuarios pueden empezar rápidamente y aprovechar Cognita para crear y optimizar sus propias aplicaciones RAG con el fin de mejorar la recuperación y generación de información impulsada por IA.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Puestos relacionados



Sin comentarios...