
Despliegue Local de Modelos Grandes QwQ-32B: Una Guía Fácil para PCs
Tutoriales prácticos sobre IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 56.6K 00

El campo de la modelización de la Inteligencia Artificial (IA) siempre está lleno de sorpresas, y cada avance tecnológico puede poner los nervios de punta al sector. Recientemente, el equipo QwQ de Alibaba dio a conocer su último modelo de inferencia, QwQ-32B, a altas horas de la madrugada, lo que volvió a llamar mucho la atención.

Según el comunicado oficialQwQ-32B es un modelo de inferencia con una escala de parámetros de sólo 32.000 millones.Y, sin embargo, afirman poder rivalizar con DeepSeek-R1 y otros modelos punteros del sector. El anuncio fue un bombazo que incendió al instante la comunidad tecnológica, con enlaces al blog oficial, la biblioteca de modelos Hugging Face, descargas de modelos, demostraciones en línea y un sitio web para que los usuarios conozcan y experimenten el producto.
Aunque la información de lanzamiento es breve y concisa, la fuerza técnica que hay detrás dista mucho de ser simple. La frase "32.000 millones de parámetros comparables a DeepSeek-R1" ya impresiona, sabiendo que, en general, cuanto mayor es el número de parámetros de un modelo, mayor suele ser el rendimiento, pero también implica una mayor demanda de recursos informáticos. QwQ-32B Conseguir un rendimiento similar al del megamodelo con un número reducido de parámetros es sin duda un gran avance, que naturalmente ha despertado un gran interés entre los entusiastas y profesionales de la tecnología.
Para demostrar el rendimiento de QwQ-32B de forma más intuitiva, se ha hecho pública simultáneamente una tabla oficial de pruebas comparativas. La evaluación comparativa es un medio importante de evaluar las capacidades de un modelo de IA, que mide el rendimiento del modelo en diferentes tareas probándolo en una serie de conjuntos de datos preestablecidos y estandarizados, lo que proporciona a los usuarios una referencia objetiva de rendimiento.

A partir de este gráfico de evaluación comparativa, podemos captar rápidamente los siguientes puntos clave de información:
- Velocidad de propagación fenomenal: La información sobre el lanzamiento del modelo достига́ть ha sido leída por más de 1,69 millones de personas en sólo 12 horas, lo que refleja plenamente la urgente demanda del mercado de modelos de IA de alto rendimiento y la gran expectación que despierta QwQ-32B.
- Excelente rendimiento: Con sólo 32.000 millones de parámetros, QwQ-32B es capaz de competir en la prueba de referencia con la versión de parámetros completos de DeepSeek-R1, que cuenta con 671.000 millones de parámetros, lo que demuestra una asombrosa relación eficiencia-energía. Este fenómeno de que un modelo pequeño supere a uno grande rompe definitivamente la percepción tradicional de la relación entre el rendimiento del modelo y el tamaño de los parámetros.
- Supera a los modelos de destilación de su clase: QwQ-32B supera significativamente a la versión de destilación 32B de DeepSeek-R1. La destilación es una técnica de compresión de modelos que pretende imitar el comportamiento de un modelo más grande entrenando un modelo más pequeño, reduciendo así el coste computacional y manteniendo el rendimiento. El hecho de que QwQ-32B supere al modelo de destilación 32B demuestra la sofisticación de su arquitectura y metodología de entrenamiento.
- Liderazgo de rendimiento multidimensional: QwQ-32B supera al modelo de código cerrado de OpenAI, o1-mini, en varias dimensiones de evaluación comparativa, lo que demuestra que QwQ-32B es capaz de competir con los mejores modelos de código cerrado en términos de capacidades de propósito general.
Especialmente interesante es el hecho de que QwQ-32B, con solo 32.000 millones de parámetros, es capaz de superar a modelos gigantes con más de 20 veces el número de parámetros, lo que representa otro salto adelante en la tecnología de IA. Y lo que es aún más emocionante, ahora los usuarios pueden ejecutar fácilmente la versión cuantificada de QwQ-32B de forma local con una tarjeta gráfica de consumo de clase RTX3090 o RTX4090. La implementación local no solo reduce la barrera de uso, sino que también abre más posibilidades para la seguridad de los datos y las aplicaciones personalizadas. Los usuarios con un rendimiento inferior de la tarjeta gráfica pueden probar a empezar con la solución de despliegue en la nube recomendada:Implantación en línea del modelo de código abierto DeepSeek-R1 con potencia de GPU gratuitao solicite directamente el uso de la API gratuita.Alibaba (volcán) proporciona 1 millón de fichas al día (durante 180 días), y el Akash La API es de uso directo y gratuito, sin necesidad de registrarse.
DeepSeek ya no es un pony de un solo truco, así que ¿cómo se mantiene OpenAI en la cima?
Con el QwQ-32B mostrando una competitividad tan fuerte, los productos existentes de OpenAI, tanto la versión Pro de 200 dólares como la versión Plus de 20 dólares, se enfrentan a un serio desafío en términos de precio/rendimiento. El QwQ-32B ha dado que pensar al mercado, sobre todo a la luz de las fluctuaciones de rendimiento que a veces muestran los modelos de OpenAI, que han sido criticadas por los usuarios como "atontamiento". No obstante, OpenAI sigue contando con un profundo historial y un amplio ecosistema en el campo de la IA, por lo que aún puede tener ventaja a la hora de afinar modelos y optimizar aplicaciones en áreas específicas. Sin embargo, el lanzamiento de QwQ-32B rompe sin duda el patrón original del mercado, obligando a todos los actores a reexaminar sus propias ventajas técnicas y estrategias de mercado.
Para evaluar mejor las capacidades reales del QwQ-32B, es necesario instalarlo localmente y probarlo en detalle, especialmente para examinar su rendimiento de razonamiento y su nivel de "IQ" en un entorno operativo local.
Afortunadamente, gracias a la Ollama Con la llegada de herramientas como Ollama, desplegar y ejecutar localmente grandes modelos lingüísticos en ordenadores personales se ha convertido en algo muy sencillo. Ollama, un marco ligero de código abierto para la ejecución de modelos, simplifica enormemente el proceso de despliegue y gestión de grandes modelos locales.
Ollama es famosa por su eficacia y facilidad de uso. Poco después del lanzamiento del QwQ-32B, Ollama anunció rápidamente la compatibilidad con el modelo, reduciendo aún más la barrera para que los usuarios experimenten la última tecnología de IA y facilitando que todo el mundo pueda empezar a utilizar la potencia del QwQ-32B.
1. Instalación y funcionamiento de Ollama
En primer lugar, visite el sitio web oficial de Ollama en ollama.com y haga clic en el botón Descargar para descargar el paquete de instalación adecuado para su sistema operativo.
Ollama ofrece compatibilidad total con los principales sistemas operativos, incluidos macOS (Intel y Apple Silicon), Windows y Linux, lo que garantiza que el modelo QwQ-32B pueda utilizarse fácilmente en todas las plataformas.
Una vez finalizada la descarga, haga doble clic en el instalador y siga las instrucciones del asistente para completar el proceso de instalación. Tras la instalación, verá un simpático icono de una alpaca en la bandeja de la barra de tareas de Windows o en la barra de menús de macOS, lo que indica que Ollama se ha ejecutado correctamente y está funcionando en segundo plano, lista para servirle.
2. Descarga del modelo QwQ-32B
Debe leerlo:Unsloth resuelve el problema de la inferencia duplicada en la versión cuantificada de QwQ-32B
Después de instalar y ejecutar correctamente Ollama, ya puede empezar a descargar el modelo QwQ-32B.

Abrir el cliente Ollama en el Modelos En la página Modelos verás que el modelo QwQ-32B se ha colocado rápidamente en los primeros puestos de la lista Hot Models, lo que da fe de su popularidad. Busca la entrada del modelo "qwq" y haz clic en ella para ir a la página de detalles del modelo. En la página de detalles, copia los comandos resaltados en el borde rojo.
Abra un terminal local (macOS/Linux) o un símbolo del sistema (Windows).
En un terminal o símbolo del sistema, pegue y ejecute el siguiente comando:ollama run qwq
ollama run qwq
Ollama iniciará automáticamente la descarga de los archivos del modelo QwQ-32B desde la nube e iniciará automáticamente el entorno de ejecución del modelo cuando se complete la descarga.
Cabe señalar queEl proceso de descarga del modelo no parece requerir una configuración de red adicional por parte del usuario. Sin duda, se trata de una función muy cómoda para los usuarios domésticos. Al fin y al cabo, un archivo modelo de casi 20 GB reducirá mucho la experiencia del usuario si la velocidad de descarga es demasiado lenta o requiere un entorno de red especial.
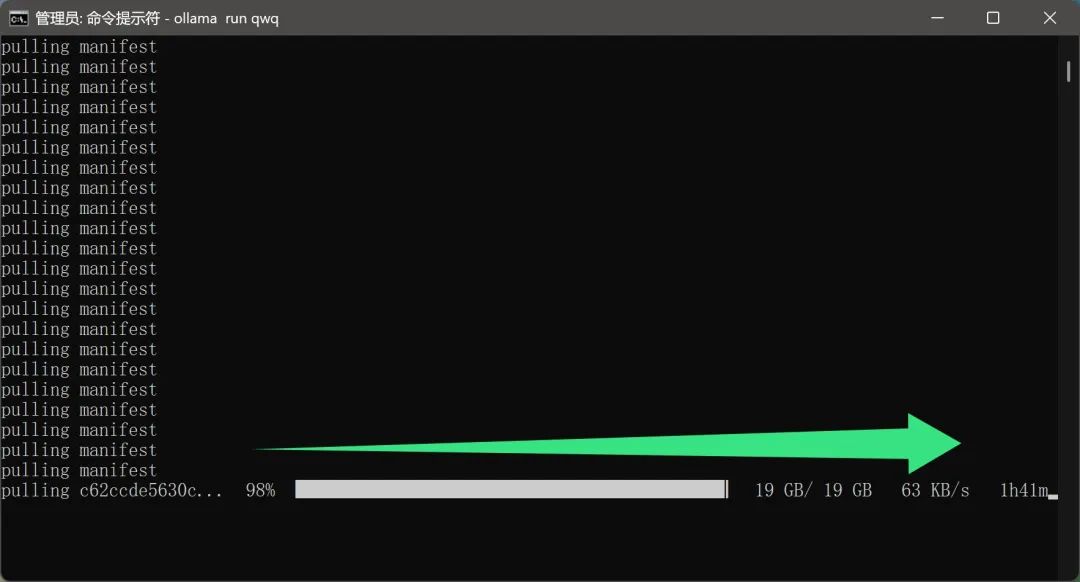
Sin embargo, debido al hecho de que el modelo QwQ-32B es actualmente muy popular y hay muchos usuarios descargándolo, la velocidad de descarga real puede verse afectada en cierta medida, dando lugar a un tiempo de descarga más largo, lo que requiere que los usuarios sean pacientes.
Tras un rato de espera, por fin se descargó el modelo. Ejecuté el modelo QwQ-32B en un ordenador equipado con una tarjeta gráfica de sobremesa RTX3060 con 12 GB de memoria de vídeo para probarlo, y quedé gratamente sorprendido: el modelo no solo se cargó correctamente, sino que también fue capaz de dar respuestas fluidas en función de las entradas del usuario y, lo que es más importante, no hubo problemas de desbordamiento de la memoria de vídeo durante todo el proceso. Y, lo que es más importante, no hubo ningún problema de desbordamiento de memoria durante todo el proceso. Esto significa que incluso las tarjetas gráficas corrientes pueden cumplir los requisitos del modelo cuantitativo QwQ-32B.

En términos de rendimiento de inferencia real, la capacidad de QwQ-32B ya ha superado a algunos modelos de OpenAI a los que los usuarios se refieren en broma como "subrayado IQ". Esto también confirma la superioridad de QwQ-32B en términos de rendimiento.
A través del Administrador de tareas de Windows, podemos supervisar el uso de recursos del modelo en tiempo real. Los resultados muestran que la CPU, la memoria y la memoria gráfica están sometidas a una gran carga durante el proceso de inferencia del modelo, lo que también refleja los elevados requisitos de recursos de hardware para ejecutar grandes modelos localmente.
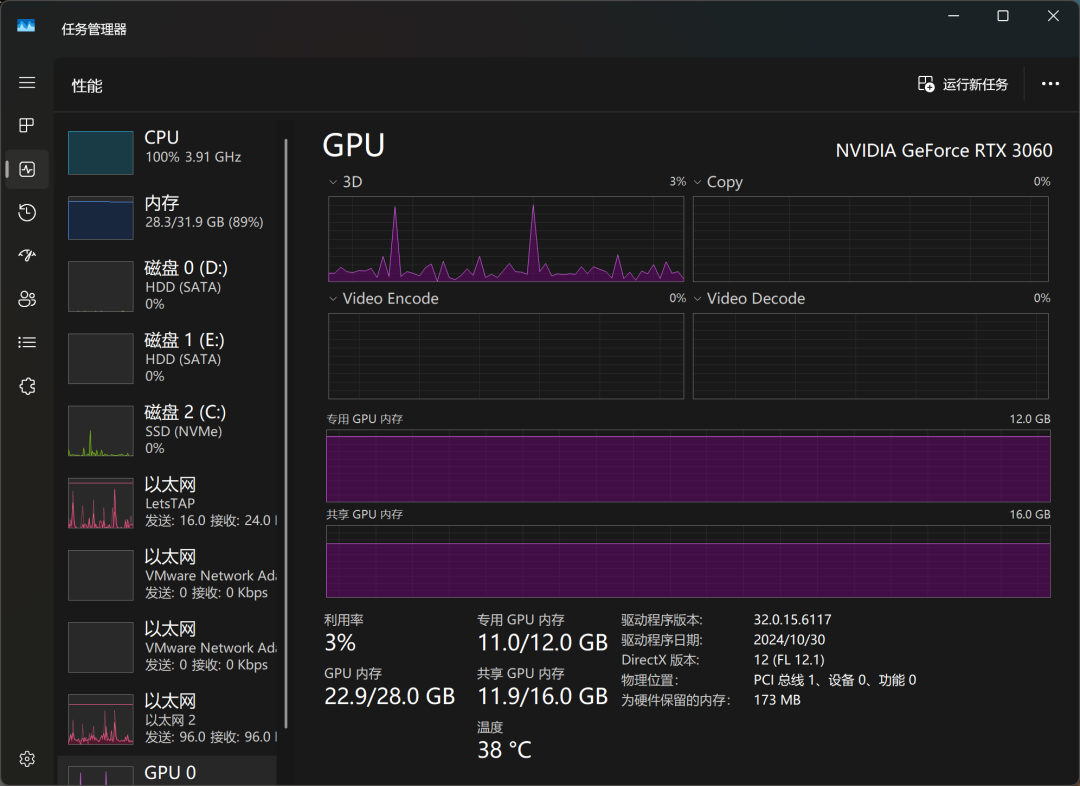
Con la tarjeta gráfica RTX3060, QwQ-32B responde a un tempo aproximado de "da, da, da, da...", que puede satisfacer las necesidades básicas de uso, pero aún hay margen de mejora en términos de capacidad de respuesta y suavidad. Si buscas una experiencia de ejecución de modelos locales más extrema, es posible que necesites una configuración de hardware de mayor nivel.
Con el fin de mejorar aún más la velocidad de ejecución del modelo, descargué y volví a ejecutar el modelo QwQ-32B en un dispositivo equipado con una tarjeta gráfica RTX3090 de gama alta. Los resultados experimentales muestran que, tras sustituir la tarjeta gráfica de gama alta, la velocidad de ejecución del modelo ha mejorado notablemente, y no es exagerado describirla como "tan rápida como volar". Esto también reafirma la importancia de la configuración del hardware para la experiencia de ejecución local de grandes modelos.
3. Integración del QwQ-32B en los clientes
Aunque hablar con el modelo directamente desde la interfaz de línea de comandos es una forma sencilla y directa, para quienes necesiten utilizarlo con frecuencia o busquen una mejor experiencia de interacción, utilizar un cliente gráfico es sin duda una opción más cómoda. En el mercado existen muchos programas de cliente de modelos de IA excelentes, y ya hemos presentado muchos de ellos, como ChatWise. La razón principal para elegir ChatWise es su diseño de interfaz sencillo e intuitivo, su lógica de funcionamiento clara y fácil de entender, y su capacidad para ofrecer a los usuarios una buena experiencia.
A continuación se describen los pasos para configurar un modelo QwQ-32B en el cliente ChatWise.
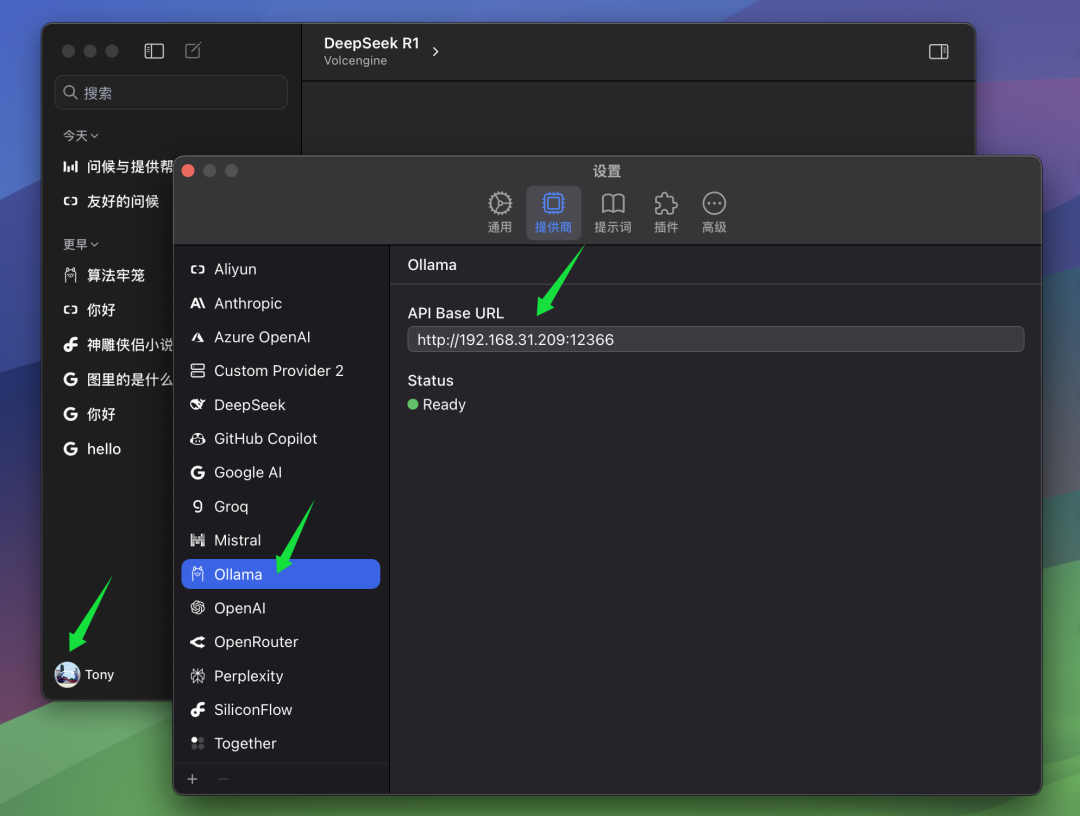
Si su cliente ChatWise y el servicio Ollama se ejecutan en el mismo ordenador, normalmente podrá abrir el cliente ChatWise y utilizar directamente el modelo QwQ-32B sin ninguna configuración adicional. Este es el caso de la mayoría de los usuarios, es decir, tanto el servicio Ollama como la aplicación cliente están instalados en el mismo dispositivo.
Sin embargo, si usted, como el autor, ha instalado el servicio Ollama en otro ordenador (por ejemplo, un servidor) y el cliente ChatWise se está ejecutando en su ordenador local, tendrá que modificar manualmente los parámetros de ChatWise BaseURL para que los clientes puedan conectarse al servicio remoto de Ollama. En el BaseURL En la configuración, debe introducir la dirección IP del ordenador que ejecuta el servicio Ollama y el número de puerto que ha configurado en el servidor Ollama. El puerto por defecto de Ollama es 13434, así que si no lo has configurado específicamente, puedes utilizar el puerto por defecto.
cumplir BaseURL Una vez configurado, puede seleccionar el modelo que desea utilizar en el cliente ChatWise.
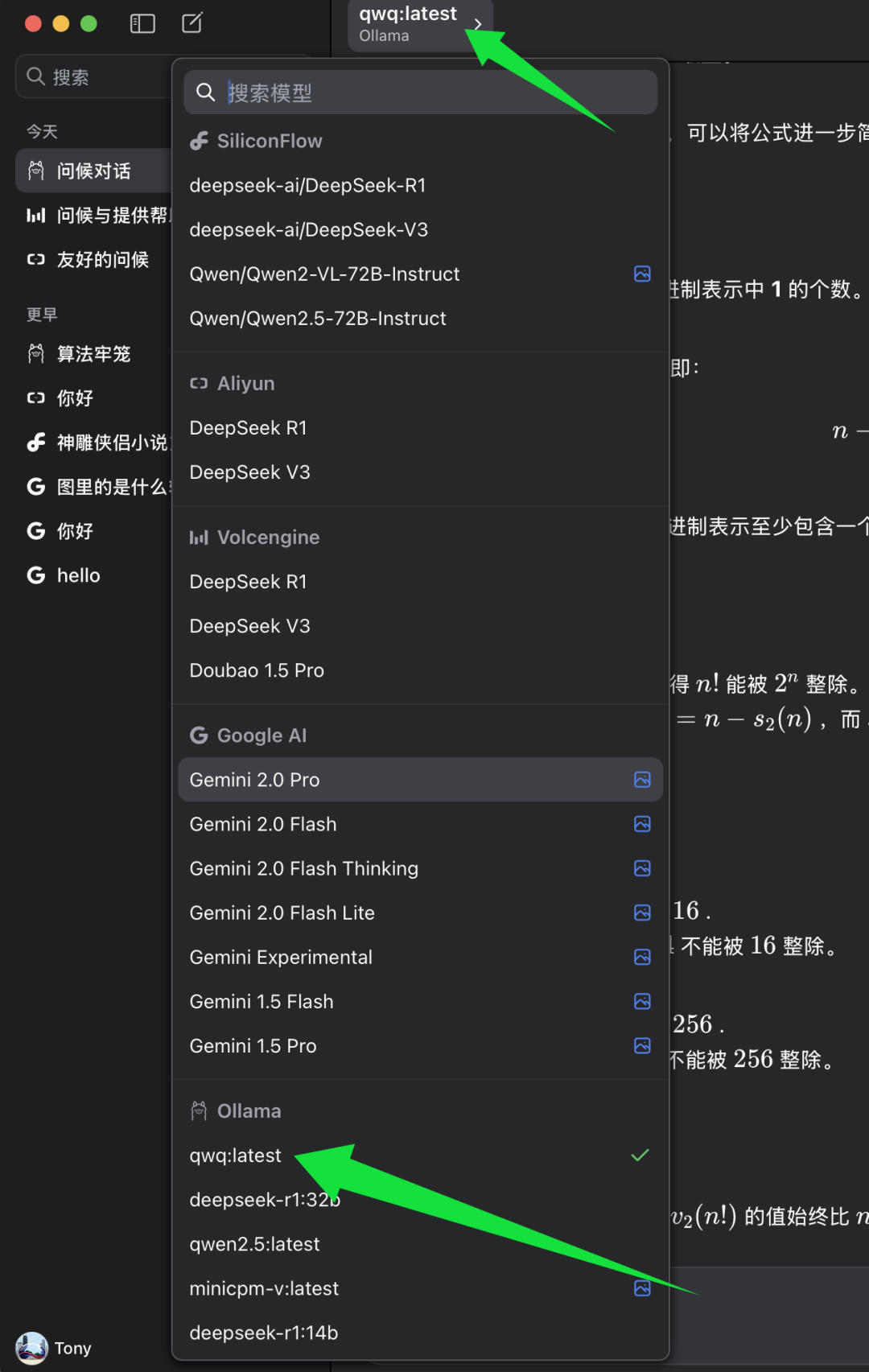
En la lista de selección de modelos de ChatWise, busque la categoría de modelos de Ollama y, debajo de ella, seleccione qwq:último. qwq:último Representa la última versión del modelo QwQ-32B, normalmente también la versión cuantificada de 4 bits. Seleccione qwq:último Después de eso, podrá empezar a experimentar la potencia del modelo QwQ-32B en el cliente ChatWise.
4. Prueba de nivel de inteligencia modelo QwQ-32B
Para evaluar el nivel de inteligencia del modelo QwQ-32B de forma más objetiva, utilizamos un conjunto de preguntas clásicas desarrolladas previamente para probar el problema de "inteligencia reducida" del modelo OpenAI. Este conjunto consta de cuatro preguntas cuidadosamente seleccionadas que han demostrado empíricamente ser útiles si el ChatGPT (sobre todo en el caso de los modelos GPT-3 o GPT-4), suele ser difícil responder correctamente a estas preguntas cuando hay comentarios de "inteligencia reducida" por parte de los usuarios. Por lo tanto, este conjunto de preguntas puede utilizarse hasta cierto punto como referencia para comprobar el nivel de inteligencia de los modelos más grandes.
A continuación, probaremos el modelo QwQ-32B ejecutado localmente uno por uno para ver si puede responder con éxito a todas las preguntas.
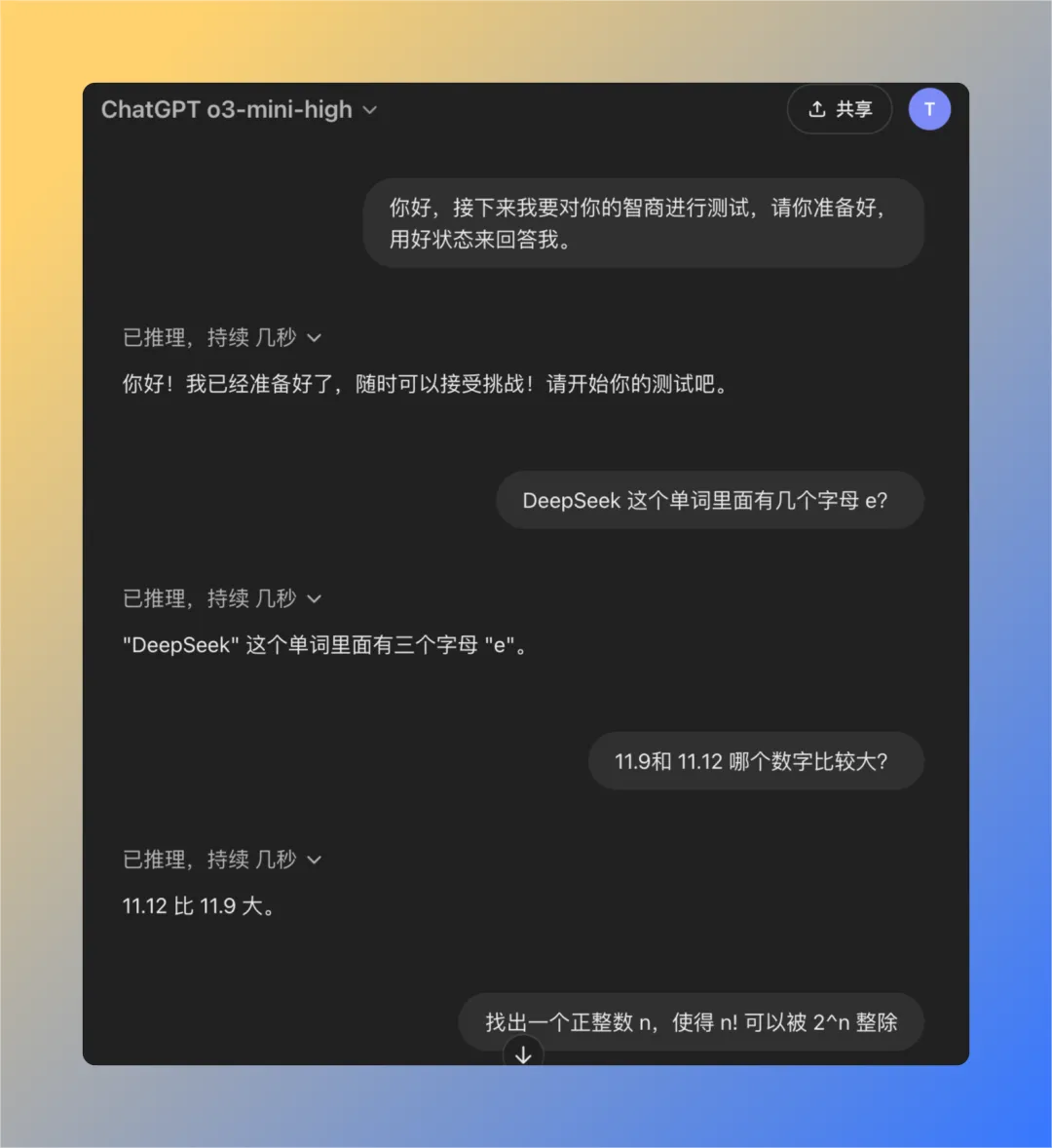
Pregunta 1: ¿Cuántas letras de la letra e hay en la palabra deepseek?
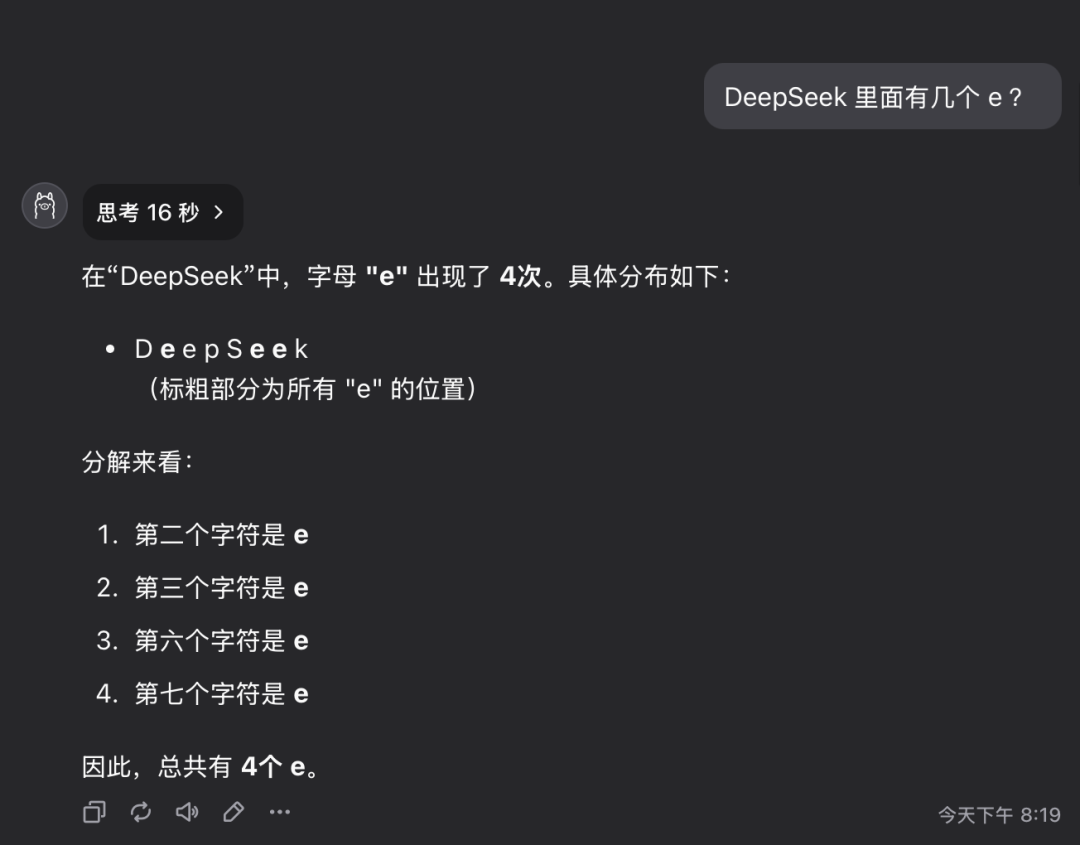
El modelo QwQ-32B dio la respuesta correcta en 16 segundos: 3. La respuesta es correcta..
Esta pregunta puede parecer sencilla, pero en realidad examina la capacidad del modelo para comprender con precisión y extraer información detallada. Sorprendentemente, todavía hay un número significativo de grandes modelos que no pueden responder con precisión a este tipo de preguntas.
Pregunta 2: ¿Qué valor es mayor, 11,9 u 11,12?

El modelo QwQ-32B dio la respuesta correcta en 47 segundos: 11,12 es mayor. La respuesta es correcta..
De nuevo, se trata de un problema aparentemente básico pero clásico. Muchos grandes modelos se confunden o juzgan mal simples comparaciones numéricas, lo que refleja posibles deficiencias en el razonamiento lógico subyacente del modelo.
Problema 3: Encuentre un número entero positivo n tal que el factorial de n (¡n!) sea divisible por la enésima potencia de 2 (2^n).

El modelo QwQ-32B da la respuesta correcta en 121 segundos: no existe tal número entero positivo n. La respuesta es correcta..
El objetivo de esta pregunta no es encontrar una respuesta numérica específica, sino examinar si el modelo tiene la capacidad de pensar de forma abstracta y razonar lógicamente, comprender la naturaleza del problema y, en última instancia, llegar a la conclusión de que "no existe". QwQ-32B fue capaz de responder correctamente a esta pregunta, demostrando cierta capacidad de razonamiento lógico.
Pregunta 4: Razonamiento lógico clásico - Puzzle del color del sombrero
"Hay 5 personas en fila y cada una de ellas lleva un sombrero en la cabeza, que puede ser de color rojo o azul. Cada persona sólo puede ver el color del sombrero de la persona que tiene delante en la fila, pero no el color del sombrero de su propia cabeza. El animador dice al grupo de antemano: "De estas 5 personas, hay al menos un sombrero rojo". Ahora, empezando por la persona del final de la fila y avanzando por turnos, se pregunta a cada persona: "¿Sabes de qué color es tu sombrero?". Cada persona sólo puede responder "sí" o "no". Suponiendo que la 5ª persona responde "No" y la 4ª responde "Sí", ¿cuál es la distribución de todos los posibles colores de sombrero?"
En comparación con las tres primeras preguntas, esta pregunta de razonamiento lógico era bastante más difícil y exigía al modelo más capacidad de análisis y razonamiento lógicos.
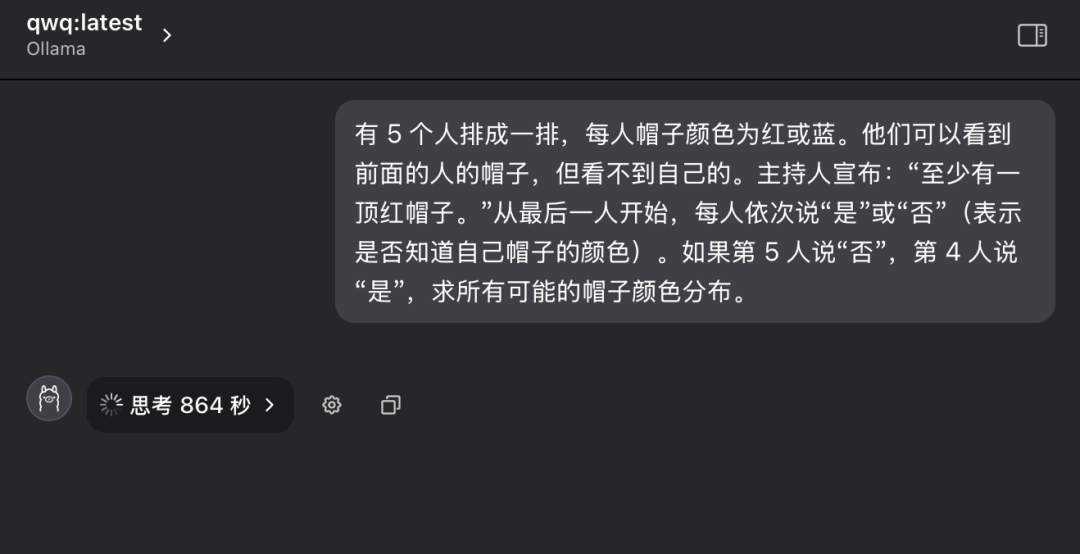
Durante el primer interrogatorio, el modelo QwQ-32B entró en un estado de pensamiento prolongado, con las palabras "Pensando..." parpadeando en la pantalla, como si el "cerebro" funcionara a gran velocidad, e incluso hizo que la gente se preocupara por si el hardware podía soportar una carga computacional tan intensa. Incluso hace que la gente se preocupe de si el hardware puede soportar una carga computacional tan intensa. Teniendo en cuenta el tiempo y las condiciones de funcionamiento del hardware, después de más de diez minutos de espera, interrumpí manualmente el proceso de pensamiento del modelo.
A continuación, el autor volvió a abrir una nueva sesión de diálogo y formuló de nuevo las mismas preguntas al modelo QwQ-32B.

Esta vez, el modelo QwQ-32B dio finalmente una respuesta completamente correcta después de 196 segundos y explicó el razonamiento en detalle. La respuesta es correcta..
Al observar el registro del proceso de razonamiento del modelo, podemos sentir que, a pesar del tamaño relativamente pequeño de los parámetros de QwQ-32B, sigue mostrando un proceso de pensamiento y análisis muy "duro" cuando se enfrenta a un problema de razonamiento lógico complejo. El modelo realiza muchos cálculos lógicos y deducción de probabilidades en segundo plano antes de llegar finalmente a la conclusión correcta.
Después de esta serie de pruebas de CI rigurosas y detalladas, podemos concluir de forma preliminar que la versión cuantificada del modelo QwQ-32B de 4 bits ha demostrado un rendimiento general impresionante, especialmente en razonamiento lógico y cuestionario, y ha superado a otros modelos de su clase. Es razonable creer que el rendimiento de la versión no cuantificada de QwQ-32B será aún mejor. Informe de evaluación del rendimiento del modelo 32B Full Blood Edition QwQ-32B proporciona datos y análisis de rendimiento más completos. Por lo tanto, básicamente podemos juzgar que la promoción de rendimiento realizada por el equipo de Alibaba QwQ en el lanzamiento del modelo QwQ-32B no es exagerada, y QwQ-32B es de hecho un excelente nuevo modelo de inferencia, que alcanza la fuerza de competir con el modelo DeepSeek-R1 de 671 mil millones de parámetros con una escala de parámetros de 32 mil millones de parámetros.
El rápido auge de los grandes modelos nacionales de código abierto demuestra plenamente la vigorosa innovación y el enorme potencial de desarrollo de China en el campo de la tecnología de IA.
Lo que es aún mejor es que la versión QwQ-32B 32B del modelo sólo requiere una tarjeta gráfica con 24 GB de RAM para ejecutarlo sin problemas y a velocidades impresionantes. Mientras que hace unos años, ejecutar un modelo a gran escala de tan alto rendimiento habría requerido millones de dólares en equipos especializados, ahora, gracias a avances tecnológicos como QwQ-32B y Ollama, los usuarios pueden desplegarlo y experimentarlo localmente en un PC de 10.000 dólares. El lanzamiento del modelo QwQ-32B indica que los modelos de IA de alto rendimiento se están popularizando cada vez más, que la era de la "IA para todos" se está acelerando y que la tecnología de IA de alto rendimiento tendrá una perspectiva de aplicación más amplia en los dispositivos terminales personales y en diversas industrias.
Ahora es el mejor momento para pasar a la acción, explorar y aprovechar al máximo la potencia del QwQ-32B. ¡Abracemos juntos el brillante futuro de la tecnología de IA!
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados

Sin comentarios...