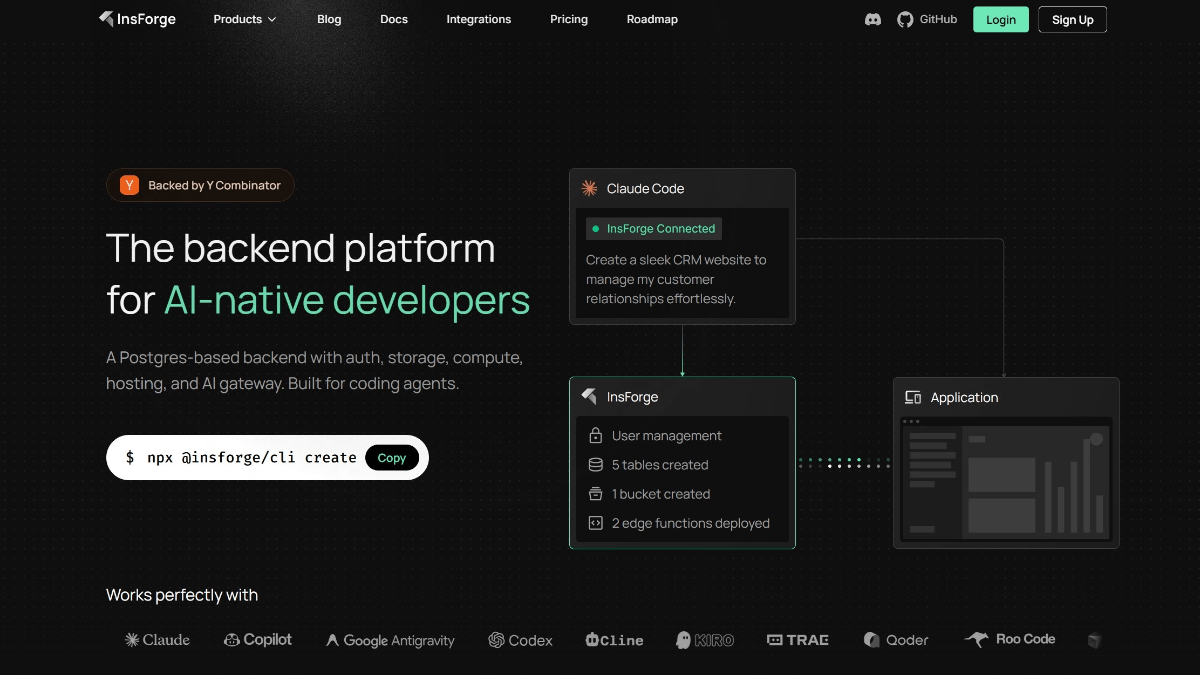
InsForge - 专为 AI 编程代理设计的开源后端平台
InsForge是专为AI编程代理设计的开源后端平台,由PostgreSQL和PostgREST构建,提供身份验证、存储、边缘函数等全栈服务。通过"语义层"将后端操作封装为AI可理解的标准化指令,支持...
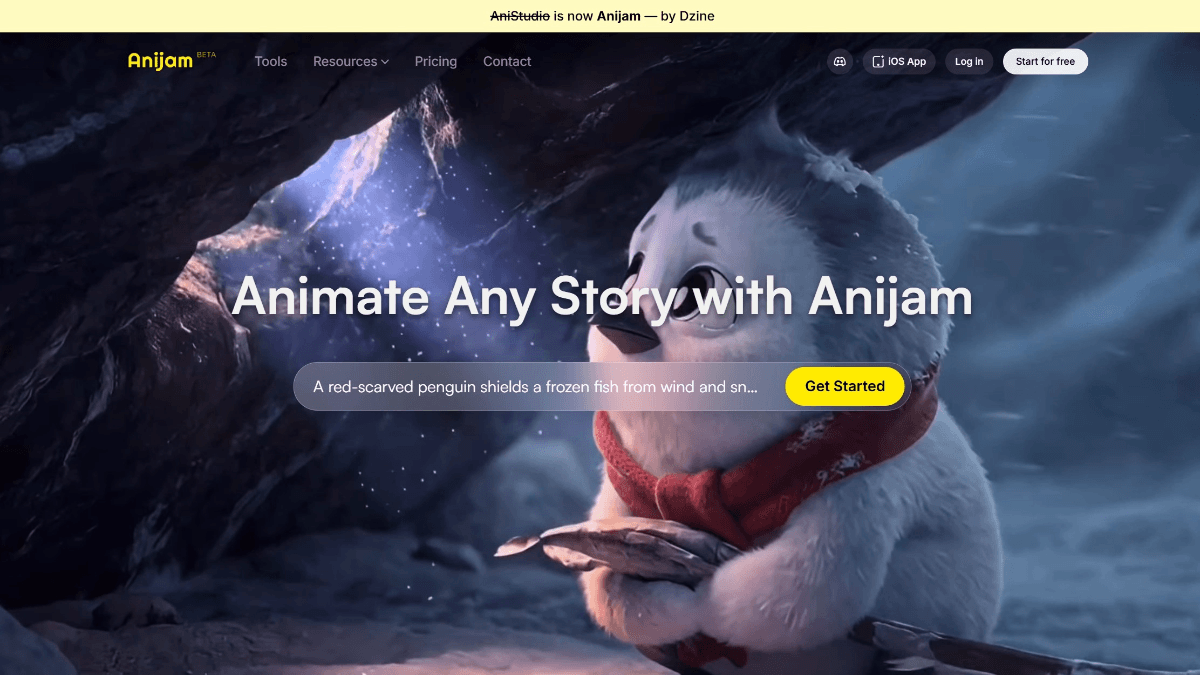
Anijam - Dzine 推出的端到端一体化 AI 动画创作平台
Anijam 是 Dzine 推出的 AI 驱动动画创作平台,用 AI Agent 为任何故事制作动画。并非简单的单片段视频生成工具,是一个端到端的一体化动画工作室。
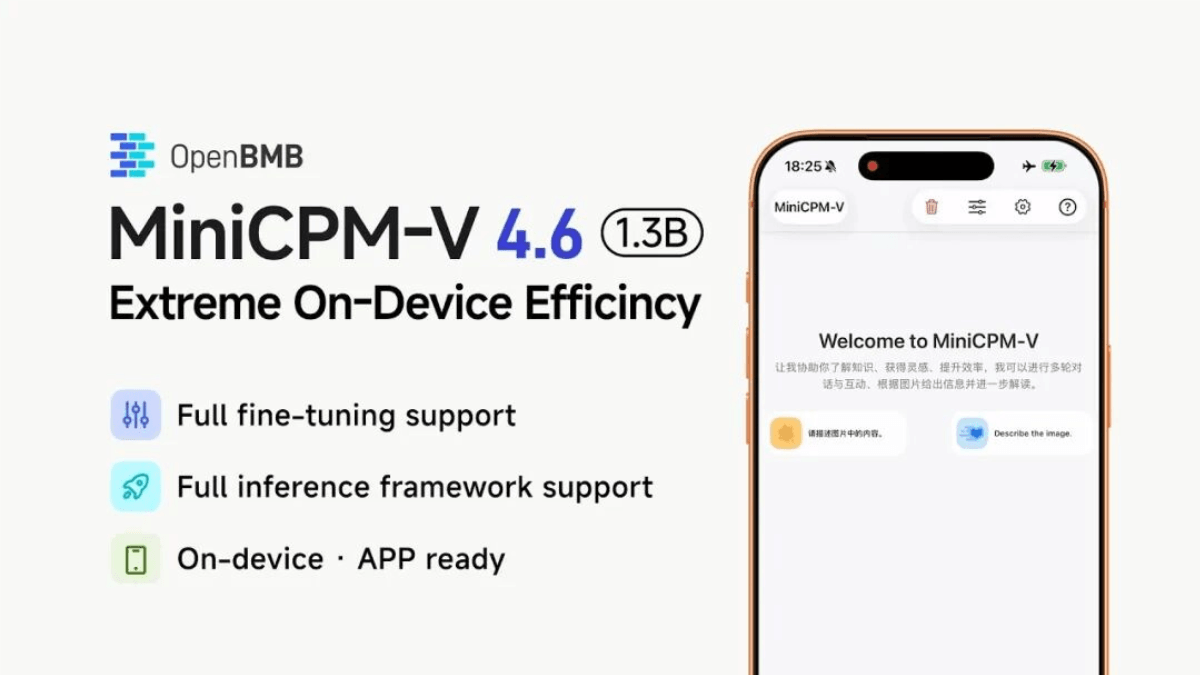
MiniCPM-V 4.6 - 面壁智能联合清华开源的端侧多模态大模型
MiniCPM-V 4.6 是面壁智能(OpenBMB)联合清华大学发布并开源的端侧多模态大模型。模型总参数量仅 1.3B,是 MiniCPM-V 系列有史以来最小的模型,在多模态综合能力上超越了阿里...
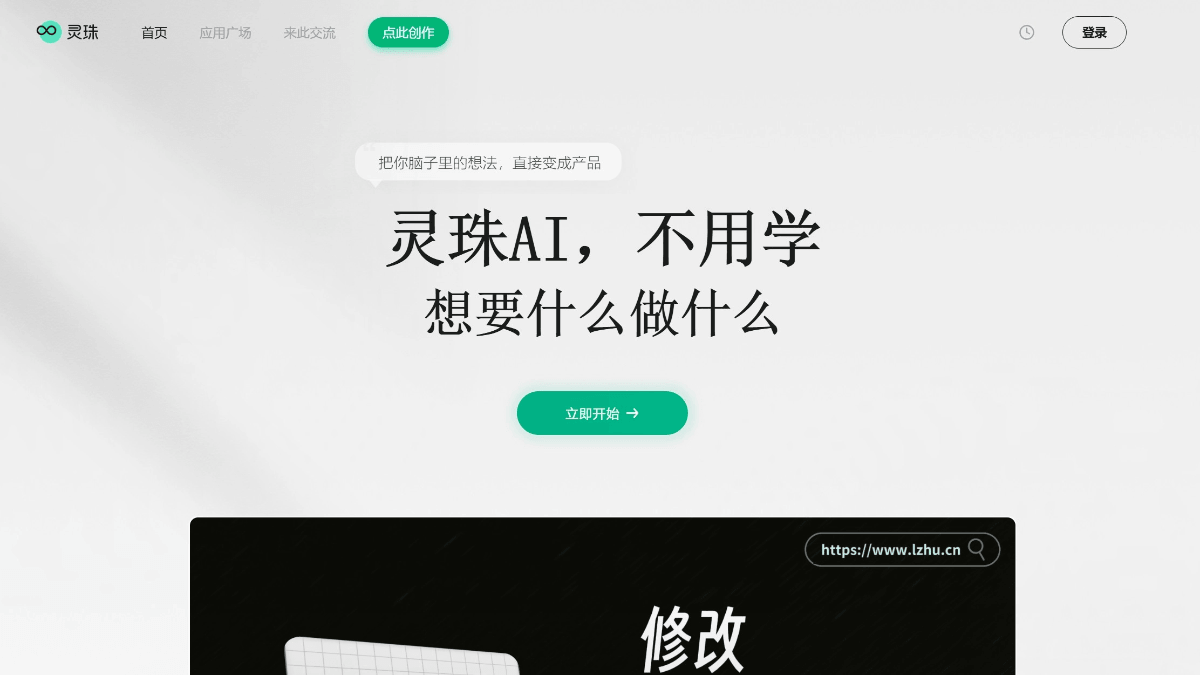
灵珠 - 零门槛 AI 应用创作平台,精准解析需求
灵珠是上海灵感菇智能科技有限公司打造的零门槛AI应用创作平台,由语生科学AI孵化平台推出。用户无需编写任何代码,只需在网页中输入创意想法,系统即可自动生成可实际运行的产品
MoMA - 中国移动发布的一站式AI模型服务平台
MoMA(Mobile Model Access) 是中国移动发布的一站式AI模型服务平台。平台接入超300款业界主流AI模型,包括自研"九天"基座大模型及DeepSeek、通义千问、豆包、Kimi...
GPT-Realtime-2 - OpenAI 发布的商用旗舰级实时语音模型
GPT-Realtime-2 是 OpenAI 发布商用的旗舰级实时语音模型,也是首款具备 GPT-5 级推理能力的端到端语音代理模型,上下文窗口扩展至 128K,支持图像输入、五级可调推理强度与并行...

JJT - 360推出的全链路AI演示文稿创作工具
JJT(超级J的AI PPT)是360推出的全链路AI演示文稿创作工具,让用户以极简操作产出设计师级别的PPT。用户只需输入主题或粘贴数据,AI即可自动生成结构完整、视觉专业的演示文稿
觅游 - 美团推出的 AI 原生共生社区
觅游(Meyo) 是美团基础研发 AI 创新产品团队推出的 AI 原生共生社区,目前已进入公测阶段。产品以"养虾"为核心隐喻,将 AI Agent 升级为拥有身份、MBTI 人格、社交关系与成长属性的...
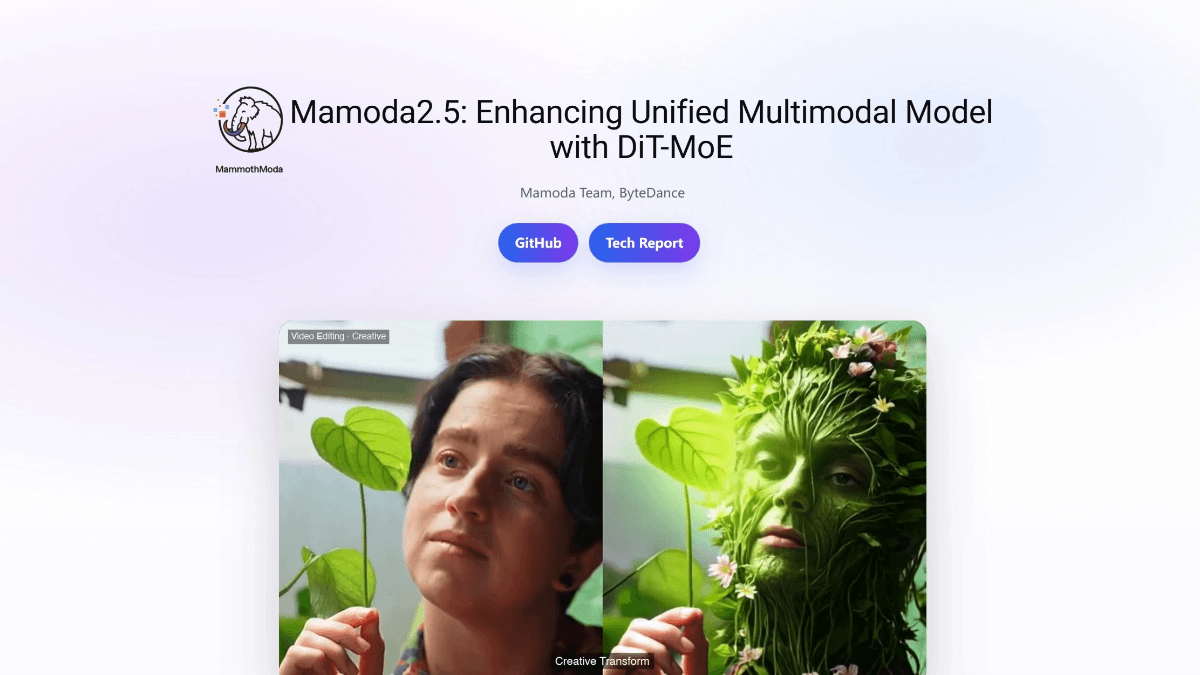
Mamoda2.5 - 字节跳动 Mamoda Team 推出的统一多模态生成模型
Mamoda2.5 是字节跳动 Mamoda Team 研发的全球首个 25B 级统一多模态生成模型,模型基于自回归-扩散(AR-Diffusion)框架,采用 Qwen3-VL-8B 理解模块与 D...
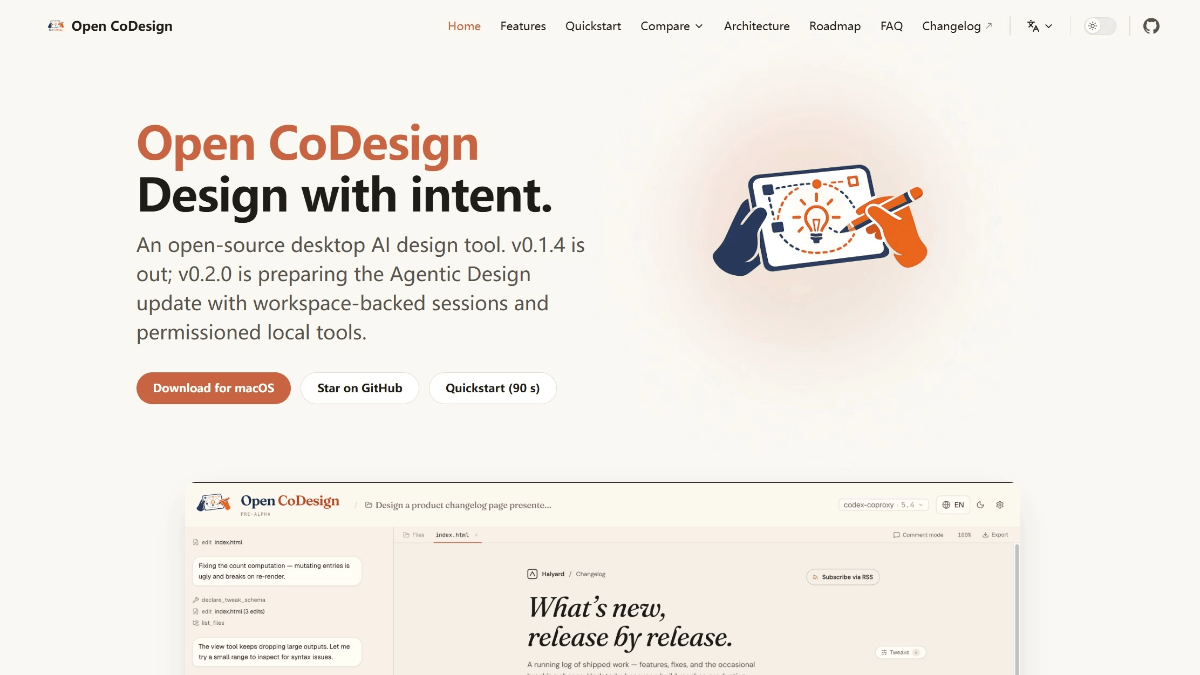
Open CoDesign - 开源桌面端 AI 设计工具,Claude Design 平替
Open CoDesign是 OpenCoworkAI 团队开发的开源桌面端 AI 设计工具,采用 MIT 协议,定位为 Claude Design 的开源替代品,同时覆盖 v0 by Vercel...