
Youtu-Embedding - Modelo de representación de texto genérico de código abierto de Tencent Youtu
Youtu-Embedding es un modelo de representación de texto universal de código abierto de Youtu Labs de Tencent, diseñado para aplicaciones de nivel empresarial. El texto se mapea en un espacio vectorial de alta dimensión mediante redes neuronales profundas, de modo que las frases semánticamente similares están más cerca unas de otras en ese espacio, logrando una recuperación semántica precisa.

SAIL-VL2 - Modelo de lenguaje visual multimodal de código abierto de ByteHop
SAIL-VL2 es un modelo de lenguaje visual multimodal de código abierto del equipo Byte Jump, centrado en el modelado conjunto de entradas multimodales como imágenes y texto. Utilizando la arquitectura de mezcla dispersa de expertos (MoE) y la estrategia de entrenamiento progresivo, logra un alto rendimiento en escalas de parámetros de 2B a 8B, especialmente en las áreas de comprensión gráfica, matemática...

MineContext - Socio de IA consciente del contexto activo y de código abierto de Bytes
MineContext es un socio activo de IA consciente del contexto, de código abierto por el equipo de ByteDance Viking, para ayudar a los usuarios a gestionar eficientemente cantidades masivas de información y mejorar la eficiencia del trabajo del conocimiento. Sobre la tecnología de captura de pantalla y comprensión de contenido, registra automáticamente las operaciones diarias del usuario (como navegar por la web, editar documentos, etc.), apoya...

nanochat - el proyecto de formación de modelos de bajo coste, gratuito y de código abierto de Karpathy
nanochat es un proyecto de código abierto lanzado por Andrej Karpathy, leyenda de la IA y antiguo Director de IA de Tesla, que permite a los particulares entrenar rápidamente un pequeño modelo de lenguaje similar a ChatGPT con un coste y una simplicidad muy bajos. Todo el proyecto utiliza sólo unos 800...
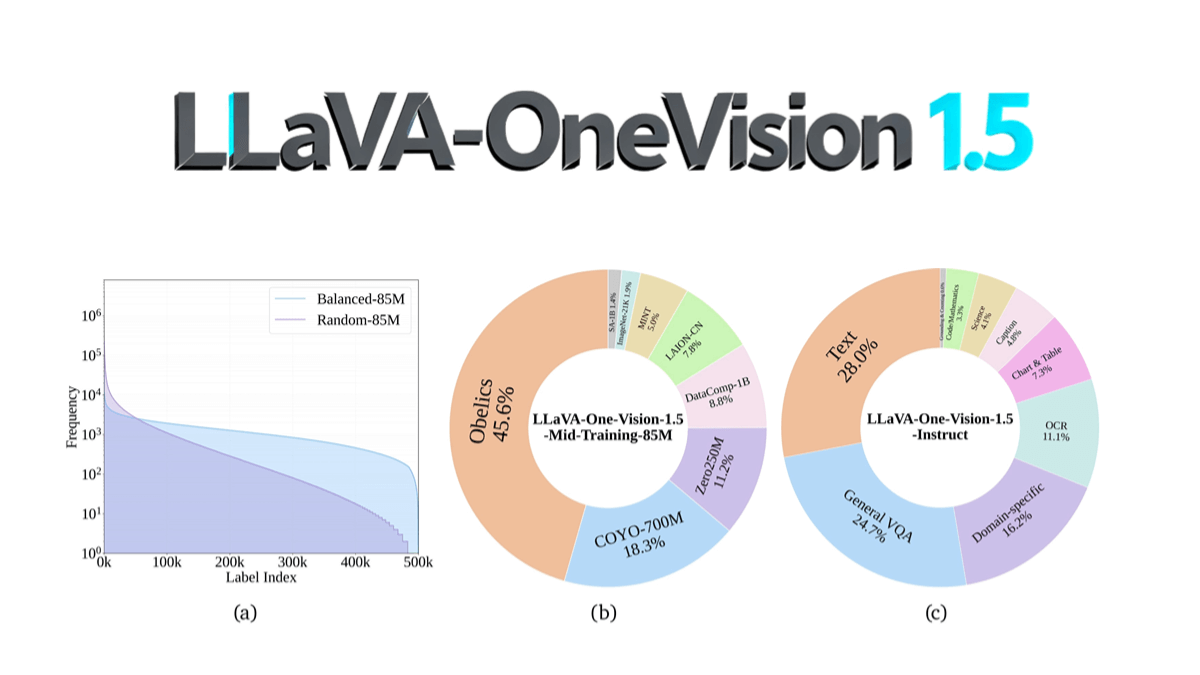
LLaVA-OneVision-1.5 - Modelo multimodal gratuito y de código abierto para una comprensión multimodal de alto rendimiento
LLaVA-OneVision-1.5 es un modelo multimodal de código abierto del equipo EvolvingLMMS-Lab, que utiliza la escala de parámetros 8B, mediante un proceso de entrenamiento compacto en tres etapas (alineación lenguaje-imagen, equilibrio conceptual e inyección de conocimientos, y ajuste fino de instrucciones) en 128 A800....
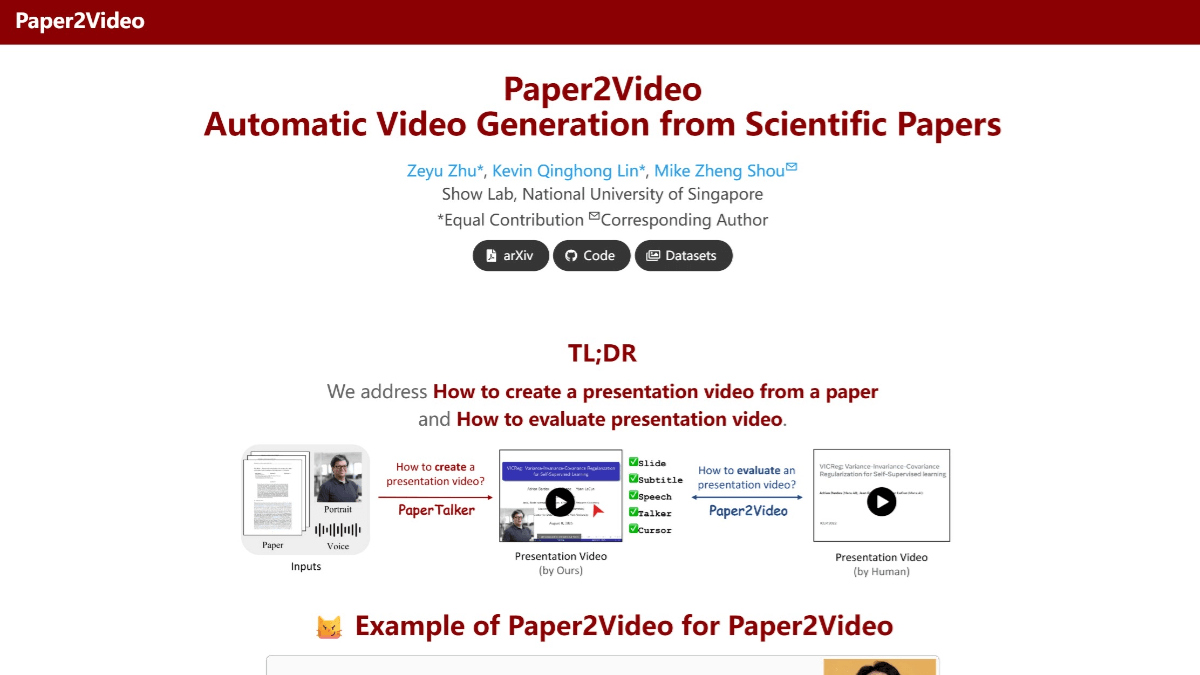
Paper2Video - Proyecto de código abierto de la NUS para generar automáticamente vídeos de demostración de trabajos académicos
Paper2Video es un proyecto de código abierto para la generación automática de vídeos de presentación de trabajos académicos en el Show Lab de la Universidad Nacional de Singapur. Utilizando el marco de inteligencia múltiple PaperTalker, los artículos se transforman en vídeos de presentación completos que contienen diapositivas, subtítulos, voz en off y avatar del orador....

NeuTTS Air - Modelos de síntesis de voz ligeros y gratuitos compatibles con la ejecución sin conexión a la CPU
NeuTTS Air es un modelo ligero de síntesis de voz de código abierto, desarrollado por el equipo Neuphonic, que puede ejecutarse en tiempo real en dispositivos locales (por ejemplo, teléfonos móviles, ordenadores portátiles, Raspberry Pi) sin depender de la nube. Utiliza la arquitectura Qwen de 0,5B parámetros y el códec NeuCodec de desarrollo propio....

KAT-Dev-72B-Exp - Racer de código abierto de programación libre de modelos específicos
KAT-Dev-72B-Exp es un modelo de gran lenguaje específico de programación de código abierto lanzado por el equipo Racer, optimizado sobre la base de técnicas de aprendizaje por refuerzo, que alcanzó una tasa de precisión de 74,6% en la prueba de referencia SWE-Bench Verified, actualmente el mejor rendimiento entre los modelos de código abierto. El modelo utiliza...

Jamba Reasoning 3B - Modelo de razonamiento ligero de código abierto de Israel AI21 Labs
Jamba Reasoning 3B es un modelo de inferencia ligero de código abierto de la startup israelí AI21 Labs, con un gran rendimiento y potencial para una amplia gama de aplicaciones. Utiliza una arquitectura híbrida SSM-Transformer que combina...
Un curso gratuito sobre las últimas inteligencias de Agentic AI por Ernst Woo
Agentic AI es el último curso sobre cuerpos inteligentes lanzado por Ernest Ng.El curso se centra en el diseño y construcción de cuerpos inteligentes, abarcando los cuatro patrones de diseño de reflexión, uso de herramientas, planificación y colaboración de cuerpos multi-inteligentes. Los alumnos dominarán cómo hacer que los cuerpos inteligentes comprueben las salidas, se sintonicen de forma autónoma a través de explicaciones teóricas y prácticas de código...