
TalkCody - Asistente de escritorio de programación de IA gratuito y de código abierto con soporte para tareas complejas
TalkCody es una aplicación de escritorio de asistente de programación de AI gratuita y de código abierto , construida sobre Rust + Tauri 2 , soporte para Windows, macOS y Linux tres plataformas , con rendimiento nativo , inicio rápido y ventajas de bajo uso de recursos . Soporte para más de 50 A...
MemMachine - Sistema de memoria de IA de código abierto de MemVerge
MemMachine es un sistema de memoria de IA de código abierto desarrollado por MemVerge, diseñado para modelos e inteligencias de IA, que puede almacenar y recuperar datos de interacción como el cerebro humano, resolviendo el problema de la "pérdida de memoria sin estado" de la IA. Adopta una arquitectura en capas (memoria a corto plazo, memoria a largo plazo, imagen de usuario...

PartCrafter - NU United Bytes modelo de generación 3D de una sola figura de código abierto
PartCrafter es un modelo generativo 3D avanzado, propuesto conjuntamente por la Universidad de Pekín, ByteDance y la Universidad Carnegie Mellon. Puede generar a la vez múltiples partes de malla 3D semánticamente explícitas y geométricamente diversas a partir de una sola imagen RGB. El modelo se modela mediante un espacio potencial combinatorio y...

GigaWorld-0 - Marco de modelado del mundo de código abierto de GigaVision
GigaWorld-0 es el marco del modelo mundial de código abierto de la startup nacional de Inteligencia Corporal GigaAI, utilizado principalmente para resolver el problema del cuello de botella de datos en el campo de la Inteligencia Corporal (IA Corporal). Genera de forma eficiente datos de entrenamiento de alta calidad, diversos y físicamente realistas,...
Mistral 3 - Mistral AI lanza la nueva serie de grandes modelos multimodales de código abierto
Mistral 3 es la última serie de grandes modelos multimodales lanzada como código abierto por Mistral AI, que incluye el modelo insignia Mistral Large 3 (675B de parámetros totales) y una versión más ligera de la serie Ministral (3B/8B/14B), ambos compatibles con la comprensión de imágenes...

Vidi2 - Comprensión multimodal de vídeo y generación de grandes modelos de código abierto de ByteHop
Vidi2 es un gran modelo de generación y comprensión de vídeo multimodal de segunda generación de código abierto de ByteDance, centrado en la comprensión, el análisis y la creación de contenidos de vídeo. Admite la entrada conjunta de modalidades de texto, vídeo y audio, y puede comprender simultáneamente contenido de imagen, información de sonido y comandos de lenguaje natural para lograr una interacción intermodal y empujar...
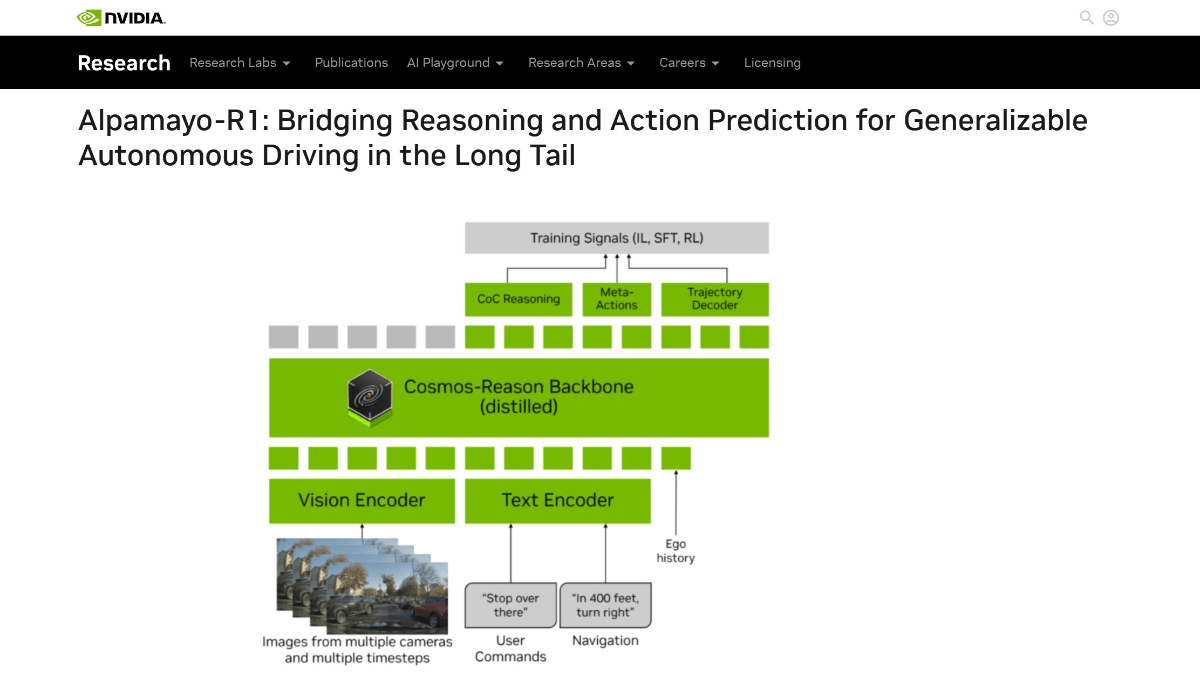
Alpamayo-R1 - Modelo de visión-lenguaje-acción de código abierto de NVIDIA con capacidad de razonamiento
Alpamayo-R1 es un modelo Visión-Lenguaje-Acción (VLA) desarrollado por NVIDIA con capacidad de razonamiento, diseñado para mejorar la capacidad de toma de decisiones de la conducción autónoma en escenarios complejos. Mediante la introducción de un mecanismo de razonamiento de cadena causal, el vehículo es capaz de analizar la causalidad del escenario (por ejemplo, "debido a...

Ovis-Image - Modelo gráfico aventurado de código abierto por el equipo Ali AIDC-AI
Ovis-Image es un modelo de gráfico generado por texto de 7.000 millones de parámetros de código abierto del equipo AIDC-AI de Alibaba International Digital Commerce Group, centrado en la representación de texto de alta calidad. Basado en la arquitectura Ovis-U1, hereda el decodificador visual avanzado y el refinador bidireccional Token ...

Wujie-Emu3.5 - Wisdom Source Research Institute gran modelo multimodal del mundo de código abierto
Wujie-Emu3.5 es un macromodelo de mundo multimodal de código abierto del Instituto de Investigación de Inteligencia Artificial Zhiyuan de Pekín, con 34.000 millones de referencias y capacidad de modelado de mundo nativo. Entrenado con 10 billones de Token multimodales (incluidos 790 años de datos de vídeo), puede simular las leyes de la física y lograr la generación de gráficos, la guía visual...
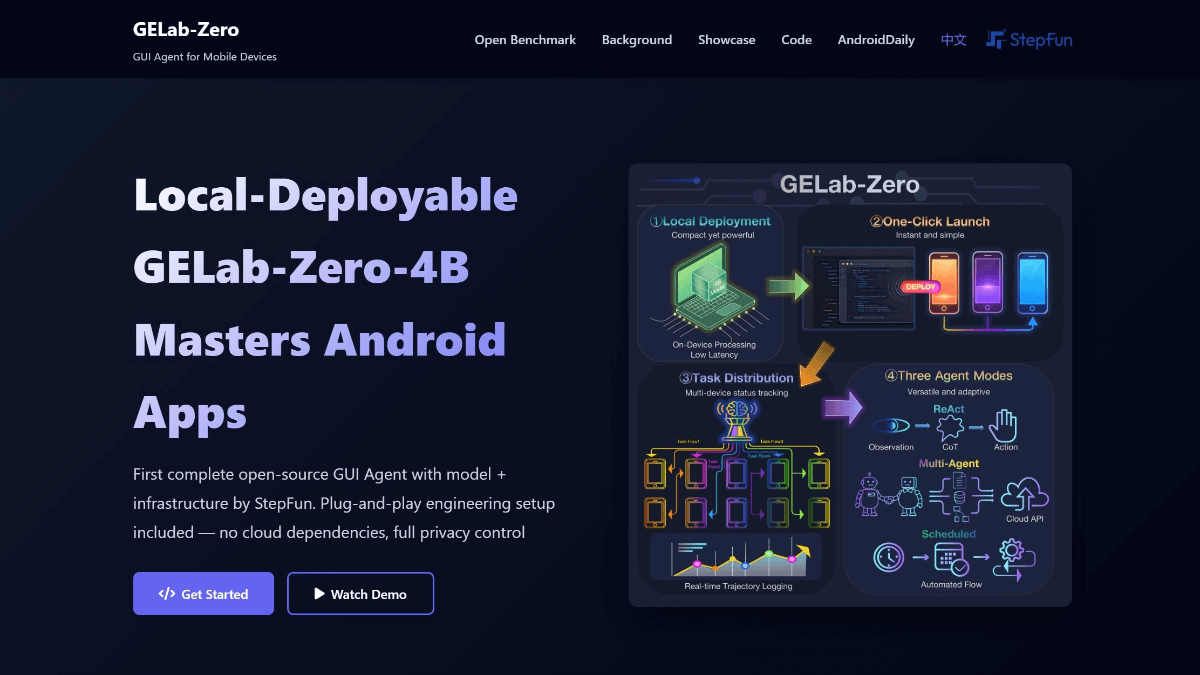
GELab-Zero - Modelo de agente GUI multimodal de código abierto por el equipo Steps
GELab-Zero es un modelo de agente GUI multimodal de código abierto creado por el equipo Step Leap, basado en el modelo Qwen3-VL-4B-Instruct con parámetros 4B. Puede reconocer elementos de interfaz de usuario y realizar operaciones como hacer clic, deslizar, etc., y admite tareas entre aplicaciones...