AI Engineering Academy: 2.4 Técnicas de agrupación de datos para sistemas de generación aumentada de recuperación (RAG)
Base de conocimientos de IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 37K 00

breve
La fragmentación de datos es un paso clave en los sistemas de Generación Aumentada de Recuperación (RAG). Descompone grandes documentos en partes más pequeñas y manejables para una indexación, recuperación y procesamiento eficientes. Este LÉEME contiene RAG Visión general de los distintos métodos de fragmentación disponibles en la cadena de producción.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/01_Data_Ingestion
Importancia de la fragmentación en el GAR
La fragmentación eficaz es fundamental para el sistema GAR porque puede:
- Mejorar la precisión de la recuperación creando unidades de información coherentes y autónomas.
- Mejora de la eficacia de la generación de incrustaciones y la búsqueda de similitudes.
- Permite una selección más precisa del contexto al generar las respuestas.
- Ayudar a gestionar los modelos lingüísticos y los sistemas integrados de Ficha Limitaciones.
Método de fragmentación
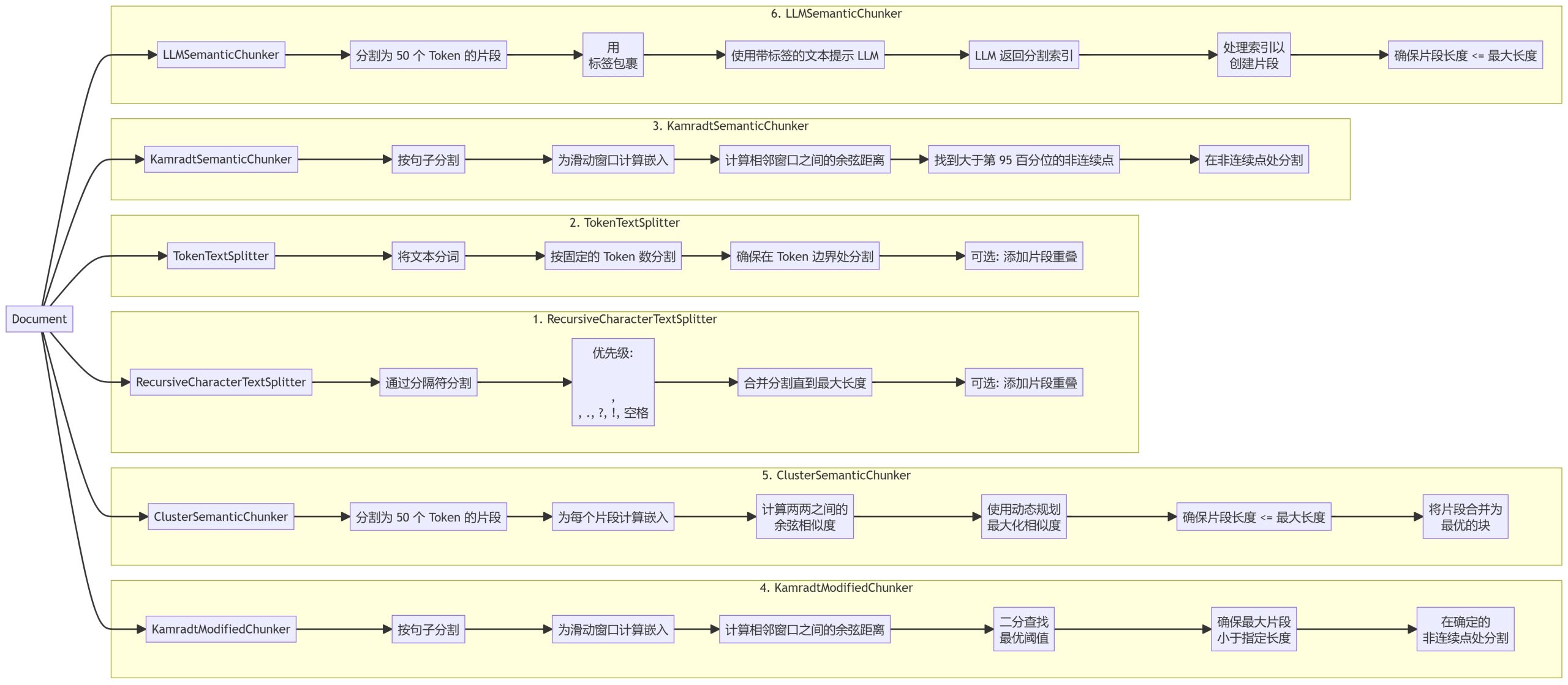
Hemos puesto en práctica seis métodos de fragmentación diferentes, cada uno con distintas ventajas y escenarios de uso:
- RecursiveCharacterTextSplitter
- TokenTextSplitter
- KamradtSemanticChunker
- KamradtModifiedChunker
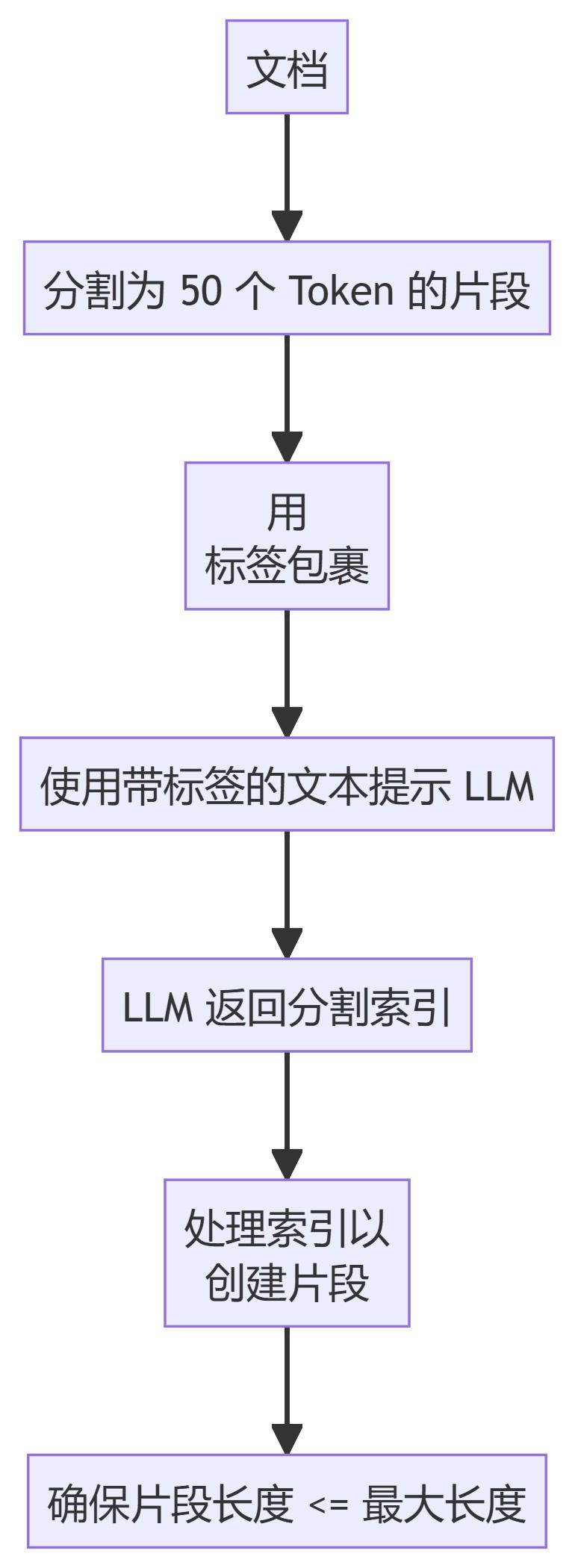
- ClusterSemanticChunker
- LLMSemanticChunker
fragmentación
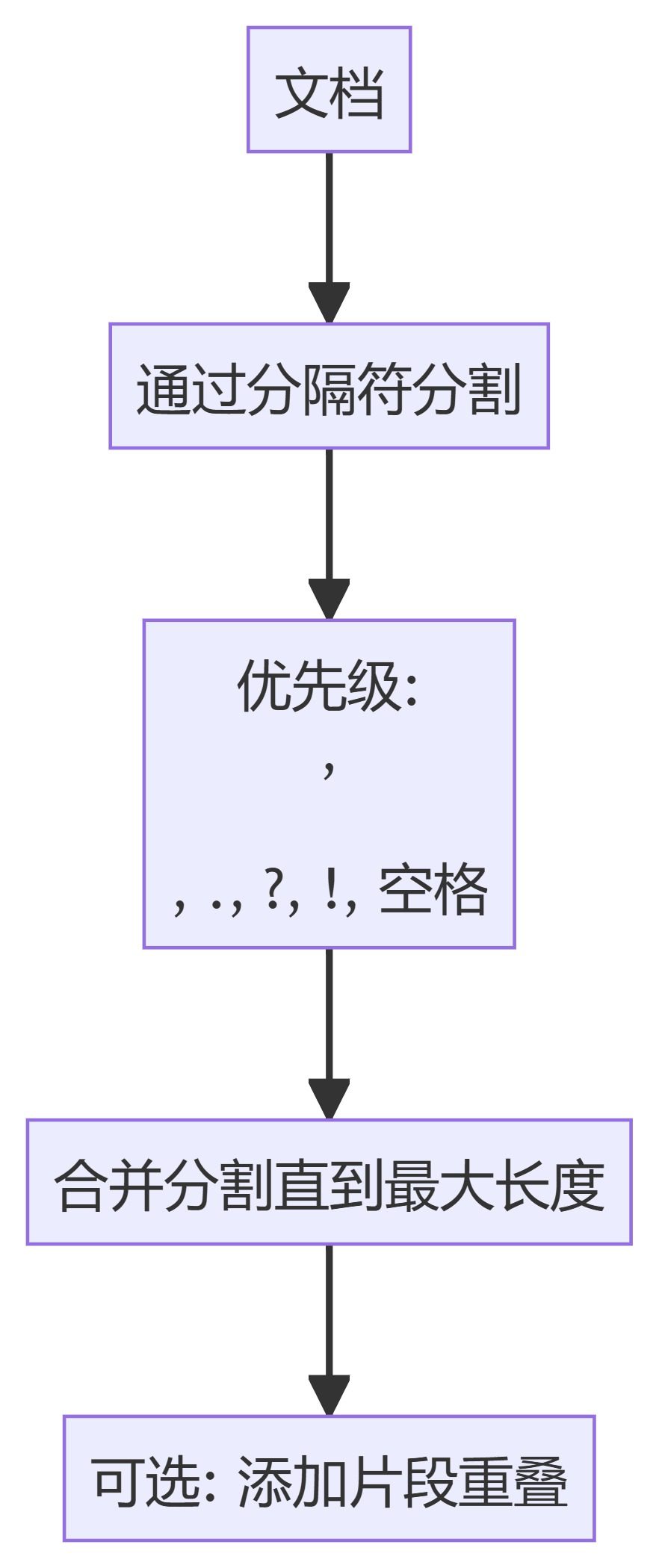
1. SeparadorTextoCaracteresRecursivo
2. Divisor de TokenText

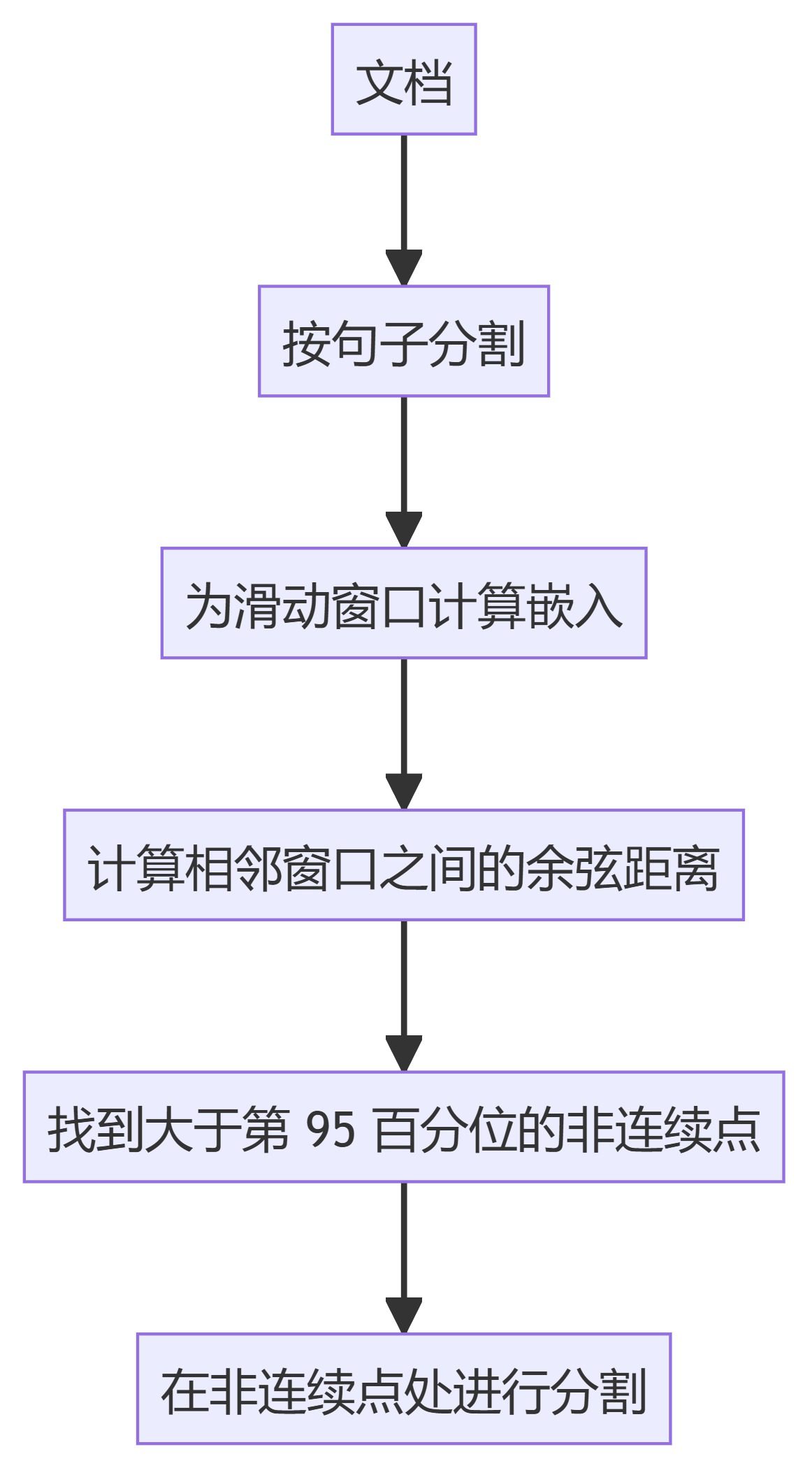
3. KamradtSemanticChunker
4. KamradtModifiedChunker
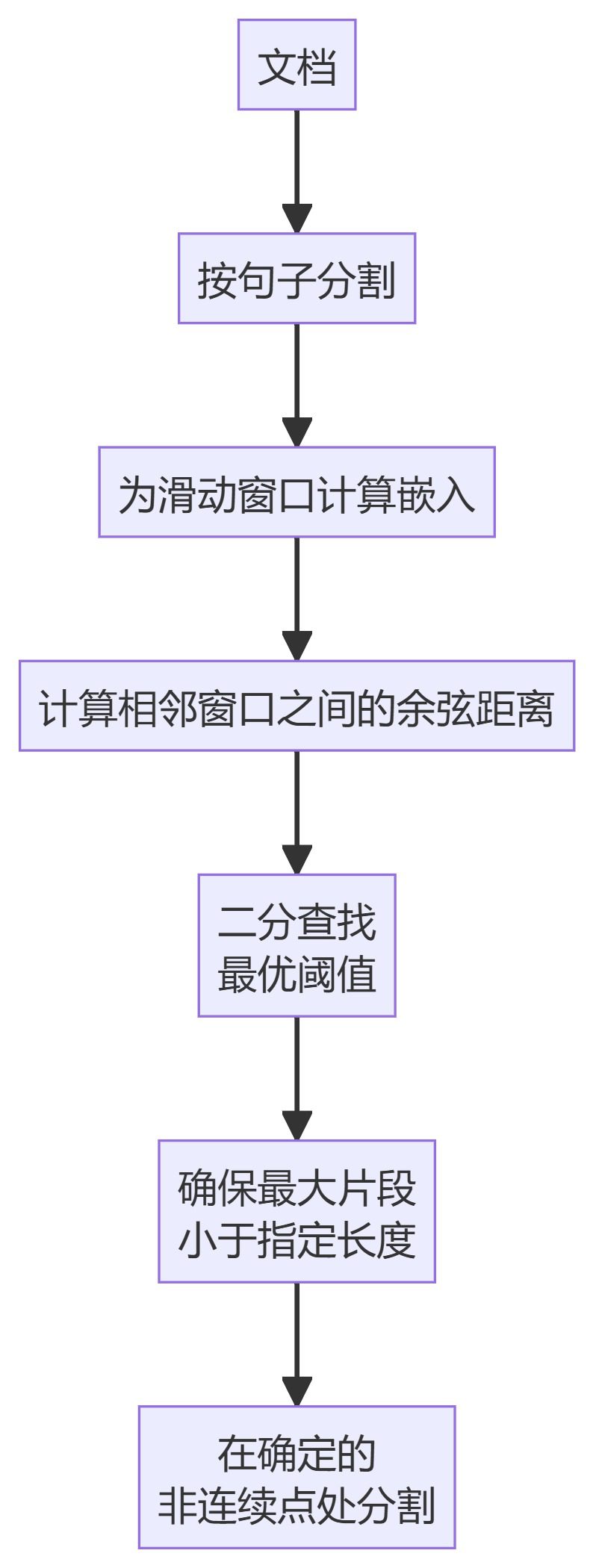
5. ClusterSemanticChunker
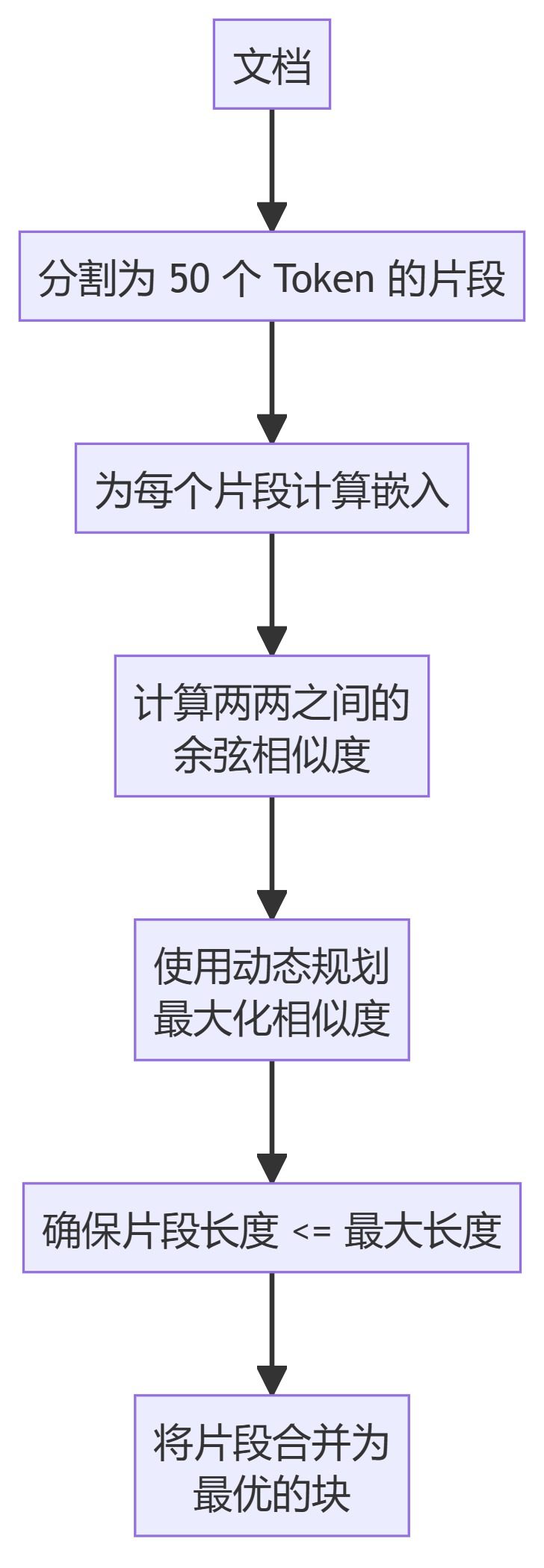
6. LLMSemanticChunker
Descripción del método
- RecursiveCharacterTextSplitter: Divide el texto basándose en una jerarquía de delimitadores, dando prioridad a los puntos de ruptura naturales del documento.
- TokenTextSplitterDivide el texto en bloques de un número fijo de tokens, asegurándose de que la división se produce en los límites de los tokens.
- KamradtSemanticChunkerUtiliza incrustaciones de ventana deslizante para identificar discontinuidades semánticas y segmentar el texto en consecuencia.
- KamradtModifiedChunker: Una versión mejorada de KamradtSemanticChunker que utiliza la búsqueda por bisección para encontrar el umbral óptimo para la segmentación.
- ClusterSemanticChunkerDividir el texto en fragmentos, calcular las incrustaciones y utilizar programación dinámica para crear fragmentos óptimos basados en la similitud semántica.
- LLMSemanticChunker: Utiliza la modelización del lenguaje para identificar puntos de segmentación adecuados en el texto.
Utilización
Para utilizar estos métodos de fragmentación en su proceso GAR:
- a través de (un hueco)
chunkerspara importar los troceadores necesarios. - Inicializar el chunker con los parámetros adecuados (por ejemplo, tamaño máximo del chunk, solapamiento).
- Pasa tu documento al chunker para obtener los resultados del chunking.
Ejemplo:
from chunkers import RecursiveCharacterTextSplitter
chunker = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=200)
chunks = chunker.split_text(your_document)
Cómo elegir un método de fragmentación
La elección del método de fragmentación depende de su caso de uso específico:
- Para la división simple de texto, puede utilizar RecursiveCharacterTextSplitter o TokenTextSplitter.
- Si necesita una segmentación semántica, considere KamradtSemanticChunker o KamradtModifiedChunker.
- Para un chunking semántico más avanzado, utilice ClusterSemanticChunker o LLMSemanticChunker.
Factores a tener en cuenta al seleccionar un método:
- Estructura del documento y tipos de contenido
- Tamaño de trozo y solapamiento requeridos
- Recursos informáticos disponibles
- Requisitos específicos del sistema de recuperación (por ejemplo, basado en vectores o en palabras clave).
Es posible probar distintos métodos y encontrar el que mejor se adapte a sus necesidades de documentación y recuperación.
Integración con los sistemas GAR
Una vez realizada la fragmentación, se suelen seguir los siguientes pasos:
- Generar incrustaciones para cada trozo (para sistemas de recuperación basados en vectores).
- Indexar estos trozos en el sistema de recuperación seleccionado (por ejemplo, base de datos vectorial, índice invertido).
- Cuando se responde a una consulta, se utilizan los trozos del índice en el paso de recuperación.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados


Sin comentarios...