
AI Engineering Academy: 2.10 Recuperador de fusiones automatizado
Base de conocimientos de IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 37.4K 00

breve
El buscador automático de fusiones esMarco de Generación de Recuperación Mejorada (RAG)Una implementación de alto nivel del El objetivo de este enfoque es mejorar el conocimiento del contexto y la coherencia de las respuestas generadas por la IA mediante la fusión de contextos potencialmente fragmentados y más pequeños en contextos más amplios y completos.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/05_Auto_Merging_RAG
Motivación de fondo
Los sistemas tradicionales de generación de recuperaciones aumentadas suelen tener dificultades para mantener la coherencia en contextos más amplios o funcionan mal cuando se trata de información que abarca varios segmentos de texto. Los recuperadores autofusionados abordan esta limitación fusionando recursivamente conjuntos de nodos hijos que hacen referencia a un nodo padre que supera un umbral específico, proporcionando así un contexto más completo y coherente en el proceso de recuperación y generación.
Detalles metodológicos
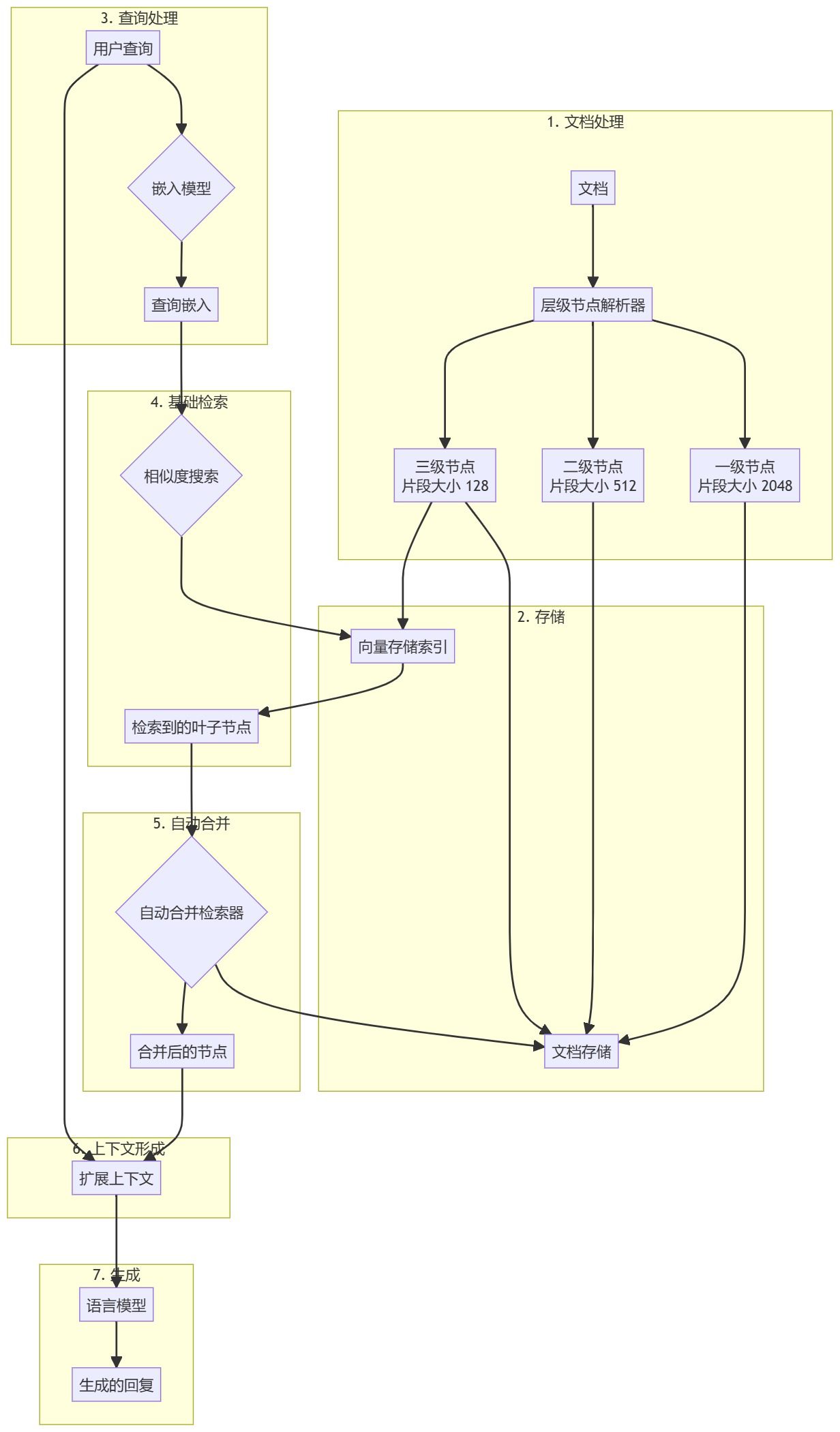
Preprocesamiento de documentos y creación de jerarquías
- Carga de documentosCarga y tratamiento de documentos de entrada (por ejemplo, archivos PDF).
- resolución jerárquica: Uso
HierarchicalNodeParserCrea una jerarquía de nodos a partir de un documento:- Nivel 1: tamaño de bloque 2048
- Nivel 2: tamaño de bloque 512
- Nivel 3: Tamaño de bloque 128
- Almacenamiento de nodosAlmacena todos los nodos en el almacén de documentos y los nodos hoja también se indexan en el almacén de vectores.
Flujo de trabajo de generación de búsquedas mejorado
- Preprocesamiento de consultasUtiliza el mismo modelo de incrustación que para los bloques de documentos para procesar las consultas de los usuarios.
- Búsqueda básicaEl buscador base realiza una búsqueda inicial de similitud para encontrar nodos hoja relevantes.
- Fusión automática::
AutoMergingRetrieverSe analiza el conjunto recuperado de nodos hoja y se "fusiona" recursivamente el subconjunto de nodos hoja que hacen referencia al nodo padre por encima de un umbral determinado. - ampliación del contexto (informática): Los nodos fusionados forman un contexto ampliado y se fusionan con la consulta original.
- Generar una respuestaGeneración de respuestas mediante la introducción de contextos de extensión y consultas en el modelo de gran lenguaje (LLM).
Principales características del buscador automatizado de fusiones
- Representación jerárquica de documentos: Mantenga una jerarquía multinivel de bloques de documentos.
- Búsqueda básica eficazRecuperación de información preliminar rápida y precisa mediante búsquedas de similitud vectorial.
- Extensión del contexto dinámico: Fusione automáticamente bloques de texto relacionados en contextos más amplios y coherentes.
- Realización flexible: Puede utilizarse para una amplia gama de tipos de documentos y modelos lingüísticos.
Ventajas de este método
- Aumentar la coherencia contextual: Proporciona un contexto más coherente y completo para el modelo lingüístico más amplio mediante la fusión de trozos de texto relacionados.
- Adaptabilidad de búsqueda flexibleEl proceso de fusión se ajusta automáticamente a la consulta y a los resultados de la búsqueda para proporcionar información contextualmente relevante.
- Estructura de almacenamiento eficiente: Una implementación rápida de la recuperación básica de nodos hoja manteniendo una estructura jerárquica.
- Posibilidad de mejorar la calidad de la respuestaSe espera que el contexto ampliado dé lugar a respuestas más precisas y detalladas del modelo lingüístico.
Resultados
Los resultados experimentales muestran que, comparando el buscador de fusión automática con el buscador base:
- Rendimiento similar en las métricas de corrección, relevancia, precisión y similitud semántica.
- En las comparaciones por pares, el 52,51 de los usuarios deTP3T prefirieron la respuesta del buscador de autofusión.
Estos resultados demuestran que el rendimiento del buscador de fusión automatizado es comparable, o incluso ligeramente superior, a los métodos de búsqueda tradicionales.
llegar a un veredicto
El buscador automatizado de fusiones proporciona un método avanzado para mejorar la RAG en el sistema. Al fusionar dinámicamente bloques de texto relevantes en contextos más amplios y coherentes, resuelve algunas de las limitaciones de los métodos tradicionales de recuperación basados en bloques de texto. Aunque los resultados iniciales muestran perspectivas positivas, se espera que nuevas investigaciones y optimizaciones mejoren significativamente la calidad y coherencia de las respuestas.
condiciones previas
Para implantar este sistema, necesitarás:
- Un gran modelo lingüístico capaz de generar texto (por ejemplo, GPT-3.5-turbo, GPT-4).
- Un modelo de incrustación para convertir bloques de texto y consultas en representaciones vectoriales.
- Bases de datos vectoriales para una búsqueda eficaz de similitudes (por ejemplo, FAISS).
- Un almacén de documentos para almacenar la jerarquía completa de nodos.
- oferta
LlamaIndexque contieneHierarchicalNodeParserresponder cantandoAutoMergingRetrieverRealización. - Recursos informáticos suficientes para procesar y almacenar grandes colecciones de documentos.
- Familiaridad con el lenguaje de programación Python para la implementación y las pruebas.
ejemplo de uso
from llama_index.core import StorageContext, VectorStoreIndex
from llama_index.core.node_parser import HierarchicalNodeParser
from llama_index.core.retrievers import AutoMergingRetriever
# 将文档解析为节点层级
node_parser = HierarchicalNodeParser.from_defaults()
nodes = node_parser.get_nodes_from_documents(docs)
# 设置存储上下文
storage_context = StorageContext.from_defaults()
storage_context.docstore.add_documents(nodes)
# 创建基础索引和检索器
leaf_nodes = get_leaf_nodes(nodes)
base_index = VectorStoreIndex(leaf_nodes, storage_context=storage_context)
base_retriever = base_index.as_retriever(similarity_top_k=6)
# 创建自动合并检索器
retriever = AutoMergingRetriever(base_retriever, storage_context, verbose=True)
# 在查询引擎中使用自动合并检索器
query_engine = RetrieverQueryEngine.from_args(retriever)
response = query_engine.query(query_str)© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...