
Academia de Ingeniería de IA: 2.1 Implantación del GAR desde cero
Base de conocimientos de IAActualizado hace 1 año Círculo de intercambio de inteligencia artificial 37.6K 00

esbozado
Esta guía le guiará a través de la creación de una sencilla generación de mejoras de búsqueda utilizando Python puro (RAG). Utilizaremos un modelo de incrustación y un gran modelo lingüístico (LLM) para recuperar documentos relevantes y generar respuestas basadas en las consultas de los usuarios.
https://github.com/adithya-s-k/AI-Engineering.academy/tree/main/RAG/00_RAG_from_Scratch
Pasos a seguir
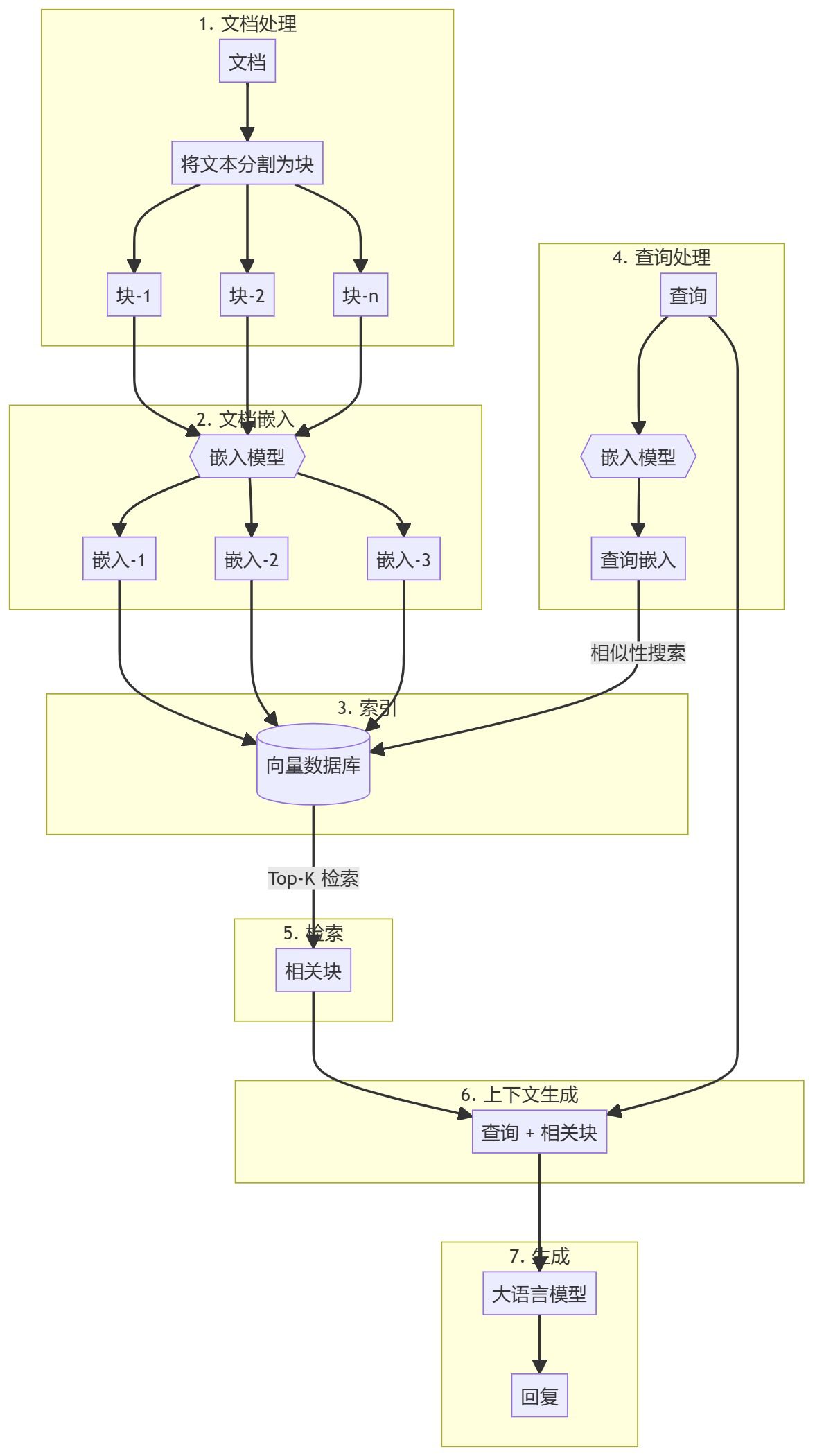
Todo el proceso puede dividirse en dos etapas principales:
- Creación de bases de conocimientos
- parte generada
Creación de bases de conocimientos
En primer lugar, hay que preparar una base de conocimientos (documentos, PDF, páginas wiki). Estos son los datos de base para el Modelo Lingüístico (LLM). El proceso específico incluye:
- trozo: Divida el texto en pequeños trozos de subdocumento para simplificar el procesamiento.
- incrustaciónCompute incrustaciones numéricas para cada bloque de subdocumentos con el fin de comprender la similitud semántica de la consulta.
- almacenarAlmacenar estas incrustaciones de forma que permitan una rápida recuperación. Aunque es habitual utilizar almacenes/bases de datos vectoriales, este tutorial muestra que no es necesario.
parte generada
Cuando se introduce una consulta de usuario, se calcula una incrustación para la consulta y se recuperan de la base de conocimientos los bloques de subdocumentos más relevantes. Estos fragmentos relevantes se añaden a la consulta del usuario para formar un contexto y se introducen en el LLM para generar una respuesta.
1. Ajustes medioambientales
Hay algunos paquetes que deben instalarse antes de empezar.
sentence-transformers: Se utiliza para generar incrustaciones para documentos y consultas.numpy: para comparaciones de similitud.scipypara cálculos avanzados de similitud.wikipedia-api: Se utiliza para cargar páginas de Wikipedia como bases de conocimiento.textwrapPermite formatear el texto de salida.
!pip install -q sentence-transformers
!pip install -q wikipedia-api
!pip install -q numpy
!pip install -q scipy
2. Carga del modelo de incrustación
Vamos a cargar un modelo incrustado. Este tutorial utiliza el gte-base-en-v1.5.
from sentence_transformers import SentenceTransformer
model = SentenceTransformer("Alibaba-NLP/gte-base-en-v1.5", trust_remote_code=True)
Sobre el modelo
gte-base-en-v1.5 Model es un modelo de inglés de código abierto proporcionado por el equipo de PNL de Alibaba. Forma parte de la familia GTE (Generic Text Embedding), diseñada para generar incrustaciones de alta calidad para diversas tareas de procesamiento del lenguaje natural. El modelo está optimizado para captar el significado semántico del texto en inglés y puede utilizarse en tareas como la similitud de frases, la búsqueda semántica y la agrupación.trust_remote_code=True Los parámetros permiten utilizar código personalizado asociado al modelo para garantizar que funciona como se espera.
3. Obtener contenido textual de Wikipedia y prepararlo
- Un artículo de Wikipedia se carga primero como una base de conocimientos. El texto se dividirá en trozos manejables (subdocumentos), normalmente por párrafos.
from wikipediaapi import Wikipedia wiki = Wikipedia('RAGBot/0.0', 'en') doc = wiki.page('Hayao_Miyazaki').text paragraphs = doc.split('\n\n') # 分块 - Aunque hay muchas estrategias de fragmentación disponibles, muchas de ellas pueden no ser aplicables. Lo mejor es consultar la base de conocimientos (KB) para determinar la estrategia más adecuada. En este ejemplo, fragmentamos por párrafos.
- Si desea ver el aspecto de estos bloques, puede importar el archivo
textwrapbiblioteca e imprimirlo párrafo por párrafo.import textwrap for i, p in enumerate(paragraphs): wrapped_text = textwrap.fill(p, width=100) print("-----------------------------------------------------------------") print(wrapped_text) print("-----------------------------------------------------------------") - Si el documento contiene imágenes y tablas, se recomienda extraerlas por separado e incrustarlas utilizando un modelo visual.
4. Incrustación de documentos
- A continuación, se crea el modelo de la maqueta llamando a la función
encodeque toma datos de texto (por ejemploparagraphs) codificado como incrustado.docs_embed = model.encode(paragraphs, normalize_embeddings=True) - Estas incrustaciones son representaciones vectoriales densas del texto, que captan el significado semántico y permiten al modelo comprender y procesar el texto de forma matemática.
- Aquí normalizamos la incrustación.
- ¿Qué es la normalización? La normalización es un proceso de ajuste de los valores de incrustación para que tengan un paradigma unitario (es decir, una longitud de vector de 1).
- ¿Por qué normalizar? La incrustación normalizada garantiza que las distancias entre vectores reflejen principalmente diferencias de dirección y no de tamaño. Esto mejora el rendimiento del modelo en tareas de búsqueda de similitud en las que se compara la "proximidad" o "semejanza" entre textos.
- al final
docs_embedes una colección de representaciones vectoriales de datos de texto, donde cada vector corresponde aparagraphsUn párrafo en la lista. - utilizar
shapepara ver el número de bloques y la dimensión de cada vector de incrustación (el tamaño del vector de incrustación depende del tipo de modelo de incrustación).docs_embed.shape - También puede ver el aspecto de la incrustación real, que es un conjunto de valores normalizados.
docs_embed[0]
5. Consultas de incrustación
Incruste la consulta de usuario de ejemplo de forma similar al documento incrustado.
query = "What was Studio Ghibli's first film?"
query_embed = model.encode(query, normalize_embeddings=True)
Puede consultar query_embed forma para confirmar la dimensión de la consulta incrustada.
query_embed.shape
6. Encontrar el párrafo más cercano a la consulta
Una de las formas más sencillas de recuperar los fragmentos de contenido más relevantes es calcular el producto punto de las incrustaciones de los documentos y las incrustaciones de las consultas.
a. Cálculo del producto punto
El producto punto es una operación matemática que multiplica y suma los elementos correspondientes de dos vectores (o matrices). Suele utilizarse para medir la similitud entre dos vectores.
(Obsérvese que el producto punto se calcula tomando el query_embed (transposición del vector).
import numpy as np
similarities = np.dot(docs_embed, query_embed.T)
b. Comprender los productos escalares y sus formas
Matrices NumPy de .shape devuelve una tupla que representa las dimensiones de la matriz.
similarities.shape
La forma esperada en este código es la siguiente:
- en caso de que
docs_embedtiene la forma de (n_docs, n_dim):- n_docs es el número de documentos.
- n_dim es la dimensión incluida en cada documento.
query_embed.Ttendrá la forma (n_dim, 1), ya que estamos comparando contra una única consulta.- punto-producto
similaritiesLa forma de la matriz será (n_docs,), lo que indica que se trata de una matriz unidimensional (vector) que contiene n_docs elementos. Cada elemento representa la puntuación de similitud entre la consulta y un documento concreto. - ¿Por qué comprobar la forma? Comprobar que la forma es la esperada (n_docs,) confirma que el producto punto se ha realizado correctamente y que las puntuaciones de similitud de cada documento se han calculado correctamente.
Puede imprimir similarities para comprobar las puntuaciones de similitud, donde cada valor corresponde a un resultado de producto punto:
print(similarities)
c. Interpretación del producto punto
El producto punto entre dos vectores (incrustaciones) mide su similitud: los valores más altos indican una mayor similitud entre la consulta y el documento. Si las incrustaciones están normalizadas, estos valores son directamente proporcionales a la similitud coseno entre los vectores. Si no están normalizados, siguen indicando la similitud, pero también reflejan el tamaño de la incrustación.
d. Identificar los 3 documentos más similares
Para encontrar los 3 documentos más similares en función de sus puntuaciones de similitud, puede utilizar el siguiente código:
top_3_idx = np.argsort(similarities, axis=0)[-3:][::-1].tolist()
- np.argsort(similitudes, eje=0). Esta función empareja el
similaritiesSe ordena el índice de la matriz. Por ejemplo, sisimilarities = [0.1, 0.7, 0.4](matemáticas) géneronp.argsortdevolverá[0, 2, 1]Los índices de los valores mínimo y máximo son 0 y 1, respectivamente. - [-3:]: Esta operación de corte selecciona los 3 índices con las puntuaciones de similitud más altas (los 3 últimos elementos tras la clasificación).
- [::-1]: Esta operación invierte el orden, por lo que el índice se ordena en orden descendente de similitud.
- tolist(). Convierte una matriz indexada en una lista Python. Resultado:
top_3_idxUn índice que contiene los 3 documentos más similares, en orden descendente de similitud.
e. Extracción de los documentos más similares
most_similar_documents = [paragraphs[idx] for idx in top_3_idx]
- Lista Derivada: Esta línea crea un archivo llamado
most_similar_documentsLa lista deparagraphsLa lista correspondiente altop_3_idxEl párrafo real del índice. - párrafos[idx]. con respecto a
top_3_idxEsta operación recupera el párrafo correspondiente para cada índice del
f. Formatear y mostrar los documentos más similares
CONTEXT La variable se inicializa inicialmente con una cadena vacía y luego se le añade el texto de la nueva línea del documento más similar en un bucle de enumeración.
CONTEXT = ""
for i, p in enumerate(most_similar_documents):
wrapped_text = textwrap.fill(p, width=100)
print("-----------------------------------------------------------------")
print(wrapped_text)
print("-----------------------------------------------------------------")
CONTEXT += wrapped_text + "\n\n"
7. Generar una respuesta
Ahora tenemos una consulta y bloques de contenido relacionados que se pasarán juntos al Modelo de Lenguaje Grande (LLM).
a. Declaración de búsqueda
query = "What was Studio Ghibli's first film?"
b. Crear un aviso
prompt = f"""
use the following CONTEXT to answer the QUESTION at the end.
If you don't know the answer, just say that you don't know, don't try to make up an answer.
CONTEXT: {CONTEXT}
QUESTION: {query}
"""
c. Configuración de OpenAI
- Instale OpenAI para acceder y utilizar el Large Language Model (LLM).
!pip install -q openai - Habilitar el acceso a las claves de la API de OpenAI (se puede establecer en secretos en Google Colab).
from google.colab import userdata userdata.get('openai') import openai - Crear un cliente OpenAI.
from openai import OpenAI client = OpenAI(api_key=userdata.get('openai'))
d. Llamar a la API para generar una respuesta
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "user", "content": prompt},
]
)
- client.chat.completions.create. Este método invoca un gran modelo lingüístico basado en el chat para crear una nueva respuesta (generar).
- cliente. Representa un objeto cliente API que se conecta a un servicio (en este caso, OpenAI).
- chat.completions.create. Especifique que solicita la creación de una generación basada en chat.
Para más información sobre los parámetros pasados al método
- model="gpt-4o". Especifica el modelo utilizado para generar la respuesta". gpt-4o" es una variante específica del modelo GPT-4. Los distintos modelos pueden tener comportamientos, métodos de ajuste o capacidades diferentes, por lo que especificar el modelo es importante para garantizar que se obtiene la salida deseada.
- mensajes. Este parámetro es una lista de objetos de mensaje para representar el historial del diálogo. Esto permite al modelo comprender el contexto del chat. En este ejemplo, proporcionamos sólo un mensaje en la lista:
{"role": "user", "content": prompt}. - papel. "usuario" denota el papel del emisor del mensaje, es decir, el usuario que interactúa con el modelo.
- contenido. Contiene el texto real del mensaje enviado por el usuario. La variable prompt contiene este texto, que el modelo utilizará como entrada para generar la respuesta.
e. Con respecto a las respuestas recibidas
Cuando realizas una solicitud a una API como el modelo GPT de OpenAI para generar una respuesta de chat, la respuesta suele devolverse en un formato estructurado, normalmente un diccionario.
Esta estructura suele incluir:
- opciones. Una lista (array) que contiene múltiples respuestas posibles generadas por el modelo. Cada elemento de esta lista representa una posible respuesta o finalización.
- mensaje. Un objeto o diccionario en cada selección que contiene el contenido real del mensaje generado por el modelo.
- contenido. El contenido textual del mensaje, es decir, la respuesta o cumplimentación real generada por el modelo.
f. Respuestas impresas
print(response.choices[0].message.content)
Elegimos choices El primer elemento de la lista, y luego acceder a uno de los message objeto. Por último, accedemos al message ha dado en el clavo content que contiene el texto generado por el modelo.
llegar a un veredicto
Esto completa nuestra explicación de cómo construir sistemas RAG desde cero. Es muy recomendable que primero construyas tu configuración RAG inicial en Python puro para entender mejor cómo funcionan estos sistemas.
© declaración de copyright
Derechos de autor del artículo Círculo de intercambio de inteligencia artificial Todos, por favor no reproducir sin permiso.
Artículos relacionados



Sin comentarios...