
An article to take you to understand RAG (Retrieval Augmented Generation), the concept of theoretical introduction + code practice

First, LLMs already have strong capabilities, why do we need RAG (Retrieval Augmentation Generation)?
While LLM has demonstrated significant capabilities, several challenges remain of concern:
- The Illusion Problem: LLM uses a statistically based probabilistic approach to generate text on a word-by-word basis, a mechanism that inherently leads to the possibility of output that appears to be logically rigorous but is in fact unsubstantiated, the so-called "grandiose fictional statements";
- (a) Timeliness issues: As the LLM scales up, the cost and cycle time of training increases. As a result, data containing up-to-date information is difficult to incorporate into the model training process, making the LLM less able to cope with time-sensitive issues such as "please suggest the current popular movie";
- Data security issues: generic LLM does not have internal enterprise data and user data, so enterprises want to use LLM under the premise of ensuring security, the best way is to put all the data locally, and all the business calculations of enterprise data are done locally. The online big model only completes a summarization function;
II. Introducing RAG?
RAG (Retrieval Augmented Generation) is a technological framework, the core of which is that when the LLM is faced with the task of answering a question or creating a text, the LLM first searches and filters the large-scale document library to find materials that are closely related to the task, and then accurately guides the subsequent process of generating the answer or constructing the text based on these materials, with the aim of improving the accuracy and reliability of the model output. The aim is to improve the accuracy and reliability of the model output in this way.
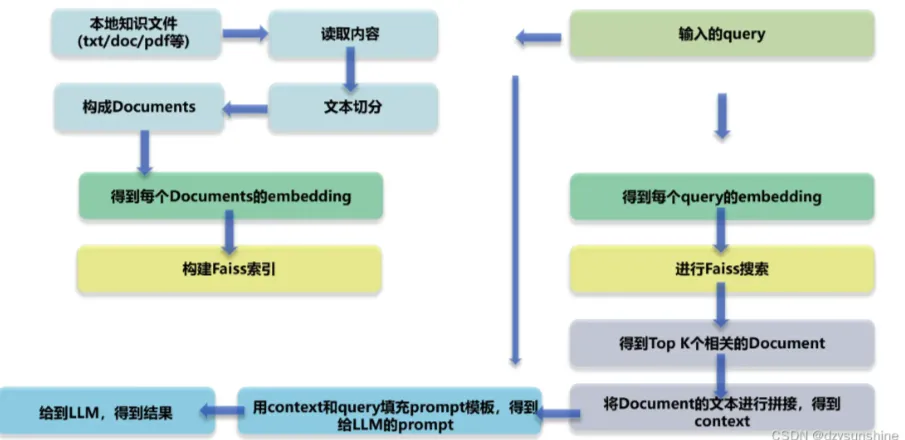
RAG Technical Architecture Diagram
III. What are the main modules of the RAG?
- Module 1: Layout Analysis
- Local knowledge file reading (pdf, txt, html, doc, excel, png, jpg, voice, etc.)
- Recovery of knowledge documents
- Module II: Building the knowledge base
- Knowledge Text Segmentation and Construct Doc Text
- Doc text embedding
- Doc Text Build Index
- Module 3: Fine-tuning the Big Model
- Module IV: RAG-based knowledge quiz
- User query embedding
- query Recall
- query sort
- The top K relevant Docs were spliced together to construct the context
- Building Prompts Based on Query and Context
- Feed the prompt to the big model to generate the answer
What are the advantages of RAG over using LLMs directly for quizzing?
The RAG (Retrieval Augmented Generation) approach empowers developers with the ability to significantly improve the accuracy of their answers without having to re-train large models for each specific task, simply by connecting to an external knowledge base that can be injected with additional information resources. This approach is particularly suitable for tasks that are highly dependent on specialized knowledge. Below are the key benefits of the RAG model:
- Scalability: Reduce model size and training overhead, while simplifying the process of expanding and updating the knowledge base.
- Accuracy: By citing sources, users are able to verify the credibility of the answers, which in turn enhances their trust in the model's output results.
- Controllability: Supports flexible updating and personalized configuration of knowledge content.
- Interpretability: show the search entries on which the model predictions depend to improve understanding and transparency.
- Versatility: RAG is able to adapt to the fine-tuning and customization of a wide range of application scenarios, covering areas such as Q&A, text summarization, and dialog systems.
- Timeliness: The use of retrieval techniques to capture the latest information developments ensures that responses are both immediate and accurate, a clear advantage over language models that rely only on intrinsic training data.
- Domain customization: RAG is able to provide targeted expertise support by mapping text datasets to specific industries or domains.
- Security: By implementing role partitioning and security control at the database level, RAG effectively strengthens the management of data usage, demonstrating higher security than the potential ambiguity of fine-tuning models for data rights management.
V. Compare and contrast RAG and SFT and tell us what the differences are?
In fact, SFT is one of the most common and basic solutions to the above problems of LLM, and it is also the basic step in realizing the application of LLM. Then it is necessary to compare the two approaches in several dimensions:
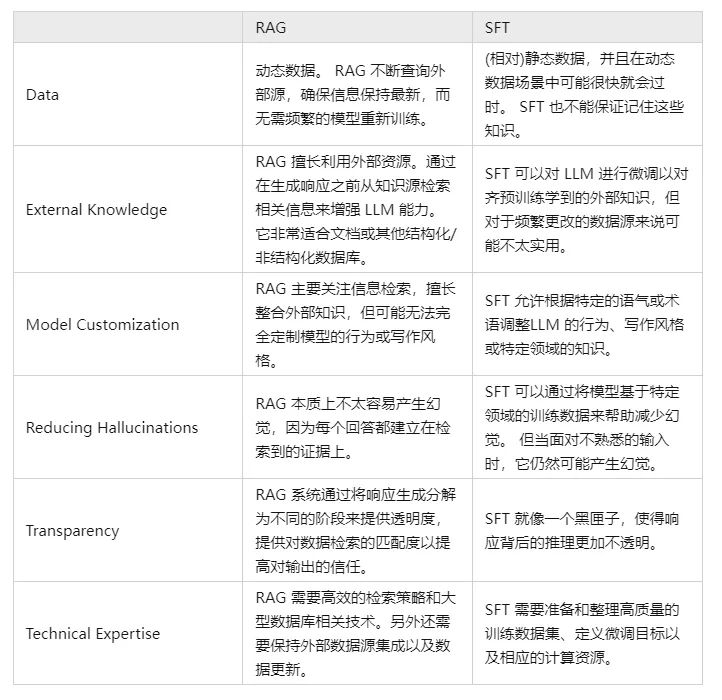
Of course, these two methods are not either/or, and it is reasonable and necessary to combine business needs with the advantages of both methods and use them in a rational manner.
Module 1: Layout Analysis
Why do I need a layout analysis?
Although the core value of RAG (Retrieval Augmented Generation) technology lies in its combination of retrieval and generation to improve the accuracy and coherence of textual content, its functional boundaries may be expanded to include layout analysis in specific application domains, such as document parsing, intelligent writing, and dialog system construction, especially when faced with the need to process structured or semi-structured information.
This is due to the fact that this type of information is often embedded in a specific layout structure and requires a deep understanding of page elements and their interrelationships.
In addition, when the RAG model is confronted with data sources that contain rich multimedia or multimodal components, such as web pages, PDF files, rich text records, Word documents, image data, voice clips, tabular data, and other complex content, it becomes crucial to have a basic layout analysis capability in order to be able to efficiently ingest and utilize these non-textual information. This ability helps the model to accurately parse the various information units and successfully integrate them into a meaningful overall interpretation.
step 1: local knowledge document acquisition
q1: How to do Local Knowledge Document Acquisition?
Local knowledge file access involves the process of extracting information from multiple data sources (e.g., .txt, .pdf, .html, .doc, .xlsx, .png, .jpg, audio files, etc.). For different types of files, specific access and parsing strategies are needed to effectively obtain the knowledge contained in them. In the following, we will introduce the ways and difficulties of accessing data from different data sources.
q2: How to get the content of rich text txt?
- Introduction: Rich text is mainly stored in the txt file, because the layout is relatively neat, so the way to get relatively simple
- Practical skills:
- [Layout analysis - rich text txt reading]
q3: How to get the content of the PDF document?
- Introduction: PDF documents in the data is more complex, contains text, pictures, tables and other different styles of data, so the parsing process will be more complex!
- Practical skills:
- [Layout analysis--PDF parsing magic pdfplumber
- Layout Analysis--PDF Parser PyMuPDF
q4: How to get the content of an HTML document?
- Introduction: PDF documents in the data is more complex, contains text, pictures, tables and other different styles of data, so the parsing process will be more complex!
- Practical skills:
- Layout Analysis--Webpage HTML Parsing BeautifulSoup]
q5: How to get the content of Doc document?
- Introduction: Doc document data is more complex, contains text, pictures, tables and other different styles of data, so the parsing process will be more complicated
- Practical skills:
- Layout analysis--Docx parsing artifact python-docx]
q6: How to use OCR to get the content of an image?
- Introduction: Optical Character Recognition (OCR). Character Recognition, OCR) is the process of analyzing and recognizing image files of textual information to obtain textual and layout information. It also means that the text in the image is recognized and returned in the form of text.
- Thoughts:
- Text Recognition: Recognition of well-localized text areas, the main problem is to solve what each text is, the text area in the image into the conversion of character information.
- Text detection: the problem solved is where there is text and how much text ranges;
- Current open source OCR project
- Tesseract
- PaddleOCR
- EasyOCR
- chineseocr
- chineseocr_lite
- TrWebOCR
- cnocr
- hn_ocr
- Theoretical learning:
- Layout Analysis--Picture Parser OCR
- Practical skills:
- [Layout analysis--OCR artifact tesseract]
- [Layout Analysis--OCR Artifacts PaddleOCR]
- [Layout Analysis - OCR Artifacts hn_ocr]
q7: How to use ASR to get speech content?
- Alias: Automatic Speech Recognition AutomaTlc Speech RecogniTlon, (ASR)
- Introduction: Converting a speech signal into corresponding text information is like a "machine's auditory system", which allows the machine to recognize and understand the speech signal into corresponding text or commands.
- Goal: Convert the lexical content of human speech into computer-readable input (eg: keystrokes, binary codes, or character sequences)
- Thoughts:
- Acoustic signal preprocessing: in order to extract features more effectively often also need to filter the acquired sound signal, frame division and other preprocessing work, the signal to be analyzed from the original signal extraction;
- Feature extraction: converting the sound signal from the time domain to the frequency domain to provide suitable feature vectors for the acoustic model; the
- Acoustic modeling: calculating the score of each feature vector on acoustic features based on the acoustic properties; the
- Language modeling: calculating the probability that the sound signal corresponds to a sequence of possible phrases, based on linguistically relevant theories; and
- Dictionary and decoding: based on the existing dictionary, the sequence of phrases is decoded to get the final possible text representation
- Theory Tutorial:
- "Speech Recognition for Layout Analysis
- Practical skills:
- [Speech-to-Text Layout Analysis]
- Layout Analysis: WeTextProcessing
- [Layout Analysis--ASR Tool Wenet]
- Layout analysis ASR training
step 2: knowledge document recovery
q1: Why is knowledge document recovery needed?
Local knowledge document acquisition contains after reading of multi-sourced data (txt, pdf, html, doc, excel, png, jpg, voice, etc.), it is easy to split a multi-line paragraph into multiple paragraphs, which leads to the paragraph encounters to be split, so it is necessary to re-organize the paragraph according to the content logic.
q2: How can I recover knowledge documents?
- Methodology I: Rule-based recovery of knowledge documents
- Method 2: Context Splice Based on Bert NSP
Step 3: Layout Analysis---Optimization Strategies
- Theoretical learning:
- [Layout Analysis---Optimization Strategies]
step 4: Homework
- Task description: Use the above methods to analyze the layout of the [SMP 2023 ChatGLM Financial Grand Modeling Challenge] of the [ChatGLM Evaluation Challenge - Financial Track Dataset].
- Effectiveness of the task: analysis of the effectiveness and performance of the various methods
Module II: Building the knowledge base
Why do you need knowledge base building?
Building a knowledge base in RAG (Retrieval-Augmented Generation) is critical for several reasons including, but not limited to, the following:
- Extending model capabilities: While large-scale language models such as the GPT family have strong language generation and comprehension capabilities, they are limited by the coverage of the training dataset, and they may not be able to accurately answer some questions based on specific facts or detailed background information. By building a knowledge base, RAG can complement the model's own knowledge limitations, allowing the model to retrieve the most up-to-date and accurate information to generate answers.
- Real-time information update: The knowledge base can be updated and expanded in real-time to ensure that the model has access to the most up-to-date knowledge content, which is especially critical for dealing with time-sensitive information, such as news events, scientific and technological advances, and so on.
- Improved accuracy: The RAG combines both retrieval and generation processes to improve accuracy when answering questions by retrieving relevant documents before generating answers. In this way, the answers generated by the model are based not only on its internal parameterized knowledge, but also on an external knowledge base of reliable sources.
- Reducing overfitting and hallucination: Large models can sometimes suffer from hallucination due to over-reliance on intrinsic patterns, i.e., generating answers that appear to be reasonable but are not. RAG can reduce the likelihood of such errors by referring to the exact evidence in the knowledge base.
- Enhanced Interpretability: The RAG not only provides the answer, but also points out the source of the answer, enhancing the transparency and credibility of the results generated by the model.
- Support for personalization and privatization needs: For enterprises or individual users, they can build exclusive knowledge bases to meet the needs of specific areas or private customization, so that the big model can better serve specific scenarios and businesses.
In summary, constructing a knowledge base is one of the core mechanisms for RAG models to achieve efficient and accurate retrieval and generation of answers, which greatly improves the performance and reliability of the model in practical applications.
step 1: knowledge text chunking
- Why do I need to chunk text?
- Risk of missing information: attempting to extract the embedding vectors for the entire document at once, while capturing the overall context, may also miss out on a lot of important information that is topic-specific, which may result in less accurate or missing information being generated.
- Chunk Size Limit: Chunk size is a key limiting factor when using models such as OpenAI. For example, the GPT-4 model has a window size limit of 32K. While this limitation is not an issue in most cases, it is important to consider chunk size from the beginning.
- There are two main factors to consider:
- Tokens restriction case for embedding models;
- The effect of semantic integrity on overall retrieval effectiveness;
- Practical skills:
- [Knowledge base construction - knowledge text chunking]
- [Knowledge Base Construction - Document Slicing and Dicing Optimization Strategies]
step 2: Docs vectorization (embdeeing)
q1: What is Docs vectorization (embdeeing)?
Embedding is also an information-intensive representation of the semantic meaning of a text, where each embedding is a vector of floating-point numbers such that the distance between two embeddings in the vector space correlates with the semantic similarity between the two inputs in the original format. For example, if two texts are similar, their vector representations should also be similar, and this set of array representations in vector space describes the subtle feature differences between the texts. Simply put, Embedding helps computers understand the "meaning" of human information. Embedding can be used to obtain the "relevance" of features in text, images, videos, or other information, which is often used at the application level in search, recommendation, classification, and other applications. This kind of correlation is commonly used in search, recommendation, classification and clustering.
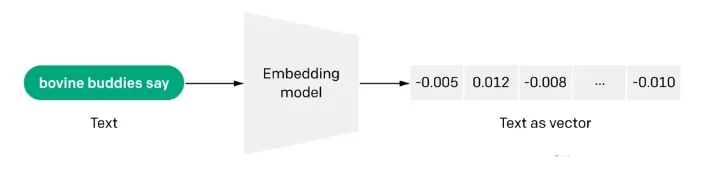
q2: How does Embedding work?
For example, here are three sentences:
- "The cat chases the mouse."
- "The kitten hunts rodents".
- "I like ham sandwiches." I like ham sandwiches.
If human beings were to categorize these three sentences, sentence 1 and sentence 2 would have almost the same meaning, while sentence 3 would be completely different. But we see that in the original English sentences, only "The" is the same in sentence 1 and sentence 2, and there are no other words that are the same. How can a computer understand the relevance of the first two sentences? Embedding compresses discrete information (words and symbols) into distributed continuous-valued data (vectors). If we plotted the previous phrase on a graph, it might look something like this:
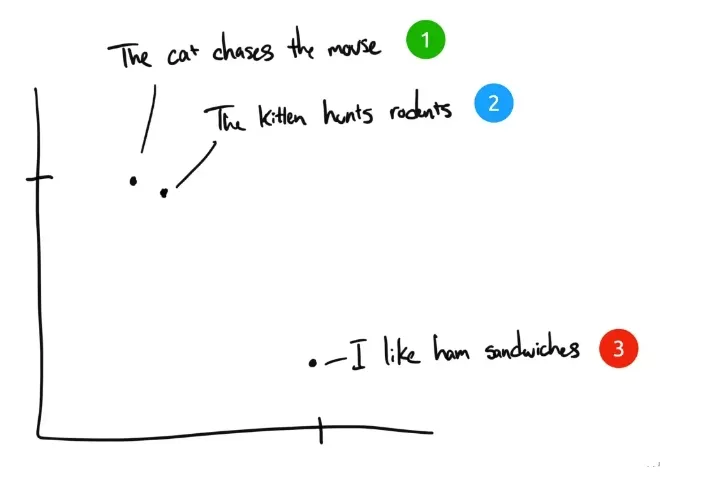
After the text has been Embedding-compressed into a computer-understandable multidimensional vectorized space, sentences 1 and 2 are plotted near each other because they have similar meanings. Sentence 3 is farther away because it is not related to them. If we had a fourth phrase, "Sally ate Swiss cheese," it would probably exist somewhere between sentence 3 (cheese can be put on sandwiches) and sentence 1 (mice like Swiss cheese).
q3: Advantages of Embedding's semantic retrieval approach over keyword retrieval?
- Semantic Understanding: Embedding-based retrieval methods represent text by word vectors, which allows the model to capture semantic associations between words, in contrast to keyword-based retrieval which tends to focus on literal matching and may ignore semantic connections between words.
- Error Tolerance: Since Embedding-based methods are able to understand the relationship between words, they are more advantageous in dealing with cases such as spelling errors, synonyms, and near-synonyms. The keyword-based retrieval methods are relatively weak in handling these situations.
- Multi-language support: Many Embedding methods can support multiple languages, which helps to realize cross-language text retrieval. For example, you can use Chinese input to query English text content, while keyword-based retrieval methods are difficult to do this.
- Contextual understanding: Embedding-based methods are more advantageous in dealing with the case of multiple meanings of a word because they can assign different vector representations to words based on the context. Whereas keyword-based retrieval methods may not be able to distinguish the meaning of the same word in different contexts well.
q4: What are the limitations of Embedding search?
- Input word count constraints: even if the text fragments that best match the query are selected with the help of Embedding technology for the reference of the large-scale model, the constraint of vocabulary counts still exists. When the retrieval covers a wide range of text, in order to control the amount of contextual vocabulary injected into the model, a TopK threshold K is usually set for the retrieval results, but this inevitably triggers the problem of information omission.
- Text data only: GPT-3.5 and many large-scale language models at this stage do not yet have image recognition capabilities, however, in the knowledge retrieval process, much of the key information often relies on the combination of graphics and text to fully understand. For example, it is difficult to accurately grasp the meaning of schematic diagrams in academic papers and data charts in financial reports based on text alone.
- Large model fabrication: When the relevant literature retrieved is not sufficient to support a large model to answer the question accurately, the model may appear a certain degree of "improvisation" in order to complete the response to the best of its ability, i.e., to make speculations and additions on the basis of the limited information.
- Theoretical learning:
- [Knowledge Base Construction - Doc Vectorization]
- Practical skills:
- [Docs Vectorization - Tencent Word Vector]
- [Docs vectorization - sbt]
- [Docs vectorization - SimCSE]
- [Docs vectorization - text2vec]
- [Docs vectorization - SGPT]
- Docs vectorization -- BGE -- Wisdom source open source the strongest semantic vector model]
- [Docs vectorization - M3E: a large-scale hybrid embedding]
step 3: Docs build index
- present (sb for a job etc)
- Practical skills:
- [Docs building index - Faiss]
- [Docs build index - milvus]
- [Docs Building Indexes - Elasticsearch]
Module 3: Fine-tuning the Big Model
Why do we need to fine-tune the big models?
Typically, there are a number of reasons to fine-tune a large model:
- The first reason is that because the number of parameters for a large model is very large, the cost of training it is very high, and it is very cost-effective for each company to go and train a large model of their own from scratch, which is a very cost-effective thing to do;
- The second reason is that the Prompt Engineering approach is a relatively easy way to get started with big models, but it has obvious drawbacks. Because usually the implementation principle of the big model has a limitation on the length of the input sequence, the Prompt Engineering approach will make the Prompt very long.
The longer the Prompt, the higher the inference cost of the big model, because the inference cost is positively correlated with the square of the Prompt length. In addition, Prompt is too long will be truncated because it exceeds the limit, which in turn leads to the output quality of the big model to be discounted. For individual users, if they are solving some problems in their daily life and work, it is usually not a big problem to use Prompt Engineering directly. However, for enterprises providing services to the outside world, to access the ability of big models in their own services, reasoning cost is a factor that has to be considered, and fine-tuning is relatively a better program.
- The third reason is that the effect of Prompt Engineering is not up to the requirement, and the enterprise has better own data, which can be used to better enhance the capability of the big model in the specific domain. This is when fine-tuning is very applicable.
- The fourth reason is to use the power of big models in personalized services, when training a lightweight fine-tuned model for each user's data is a good solution.
- The fifth reason is that of data security. If the data is not to be passed to a third-party big model service, it is very necessary to build your own big model. Usually, these open source big models need to be fine-tuned with their own data in order to meet the needs of the business.
How do you fine-tune a large model?
q1: The problem of fine-tuning technical routes for large models
The fine-tuning of the large model from a parameter scale perspective is split into two technical routes:
- Technical route 1: For the full amount of parameters, the full amount of training, this path is called full fine tuning FFT (Full Fine Tuning).
- Technical route II: Only some of the parameters are trained, this path is called PEFT (Parameter-Efficient Fine Tuning).
q2: What are the problems with the full-volume fine-tuning FFT technique for large models
FFT can also cause some problems, the more impactful ones, the two main ones being the following:
- Problem 1: The cost of training will be higher, because the number of parameters for fine-tuning is the same number as for pre-training;
- Problem 2: Catastrophic Forgetting (Catastrophic Forgetting), where fine-tuning with specific training data may make performance in that domain better, but may also make ability in other domains that were performing well worse.
q3: What problems are solved by PEFT (Parameter-Efficient Fine Tuning) for large models?
The main problem that PEFT wants to solve is the above two problems that exist in FFT, and PEFT is also the more mainstream fine-tuning program at present. From the perspective of the source of training data, as well as the training method, there are several technical routes for fine-tuning of large models as follows:
- Technical route 1: Supervised Fine Tuning SFT (Supervised Fine Tuning), this scheme focuses on fine-tuning large models with manually labeled data using the traditional supervised learning approach in machine learning;
- Technical route II: Reinforcement Learning with Human Feedback (RLHF), the main feature of this scheme is to introduce human feedback, by way of reinforcement learning, into the fine-tuning of the big model, so that the results generated by the big model can be more in line with some of the human expectations;
- Technology Route 3: Reinforcement Learning with AI Feedback (RLAIF), this principle is roughly similar to RLHF, but the source of feedback is AI. here is trying to solve the efficiency problem of the feedback system, because collecting human feedback, relatively speaking, the cost will be higher and less efficient.
Different categorization perspectives just have different emphases, and fine-tuning of the same big model is not limited to a particular scenario, but can be multiple scenarios together. The ultimate goal of fine-tuning is to be able to enhance the capability of the big model in a specific domain as much as possible under the premise of controllable cost.
What are large model LLMs learning when they perform SFT operations?
- Pre-training -> pre-train on large amounts of unsupervised data to get a base model -> use the pre-trained model as a starting point for SFT and RLHF.
- SFT --> Perform SFT training on supervised datasets and further optimize the model using supervised signals such as contextual information --> Use the SFT-trained model as a starting point for RLHF.
- RLHF --> Reinforcement learning using human feedback to optimize the model to better fit human intentions and preferences --> Evaluate and validate the RLHF-trained model and make necessary adjustments.
step 1: large model fine-tuning training data construction
- Introduction: How to build Training data?
- Practical skills:
- [Large-scale models (LLMs) LLM methodology for generating SFT data]
step 2: fine-tuning the big model instructions
- Introduction: How to build Training data?
- Practical skills:
- [Continued pre-training of large-scale models (LLMs)]
- [Fine-tuning of LLMs instructions]
- [Large model (LLMs) incentive model training chapter]
- Reinforcement Learning for Large Models (LLMs) - PPO Training Chapter
- Reinforcement Learning for Large Models (LLMs) - DPO Training Chapter
Module 4: Document Retrieval
Why do you need Document Retrieval?
Document Retrieval As the core RAG work, its effectiveness is crucial for downstream work. Although it is possible to recall document fragments related to the user's question from the document repository by means of vector recall, and input them into LLM at the same time to enhance the model answer quality. The commonly used way is to directly use the user's question for document recall. However, very often, the user's question is very colloquial and vaguely described, which affects the quality of vector recall and thus the model response. This chapter mainly introduces some problems and corresponding solutions in the process of document retrieval.
step 1: document retrieval negative sample sample mining
- INTRODUCTION: In all kinds of retrieval tasks, in order to train a good quality retrieval model, it is often necessary to sample high-quality negative examples from a large set of candidate samples, together with positive examples.
- Practical skills:
- [Document Retrieval--Negative Sample Sample Mining Chapter]
step 2: document retrieval optimization strategy
- Introduction: document retrieval optimization strategies
- Practical skills:
- [Document Retrieval--Document Retrieval Optimization Strategies]
Module V: Reranker
Why do you need Reranker?
The basic RAG application consists of four key technical components:
- Embedding models: used to convert external documents and user queries into Embedding vectors
- vector database: Used to store Embedding vectors and perform vector similarity searches (retrieve the most relevant Top-K pieces of information).
- Prompt engineering: inputs for combining user questions and retrieved contexts into larger models
- Large Language Model (LLM): for generating responses
The basic RAG architecture described above effectively addresses the problem of LLMs creating "illusions" and generating unreliable content. However, some enterprise users require more sophisticated architectures for contextual relevance and Q&A accuracy. A proven and popular approach is to integrate Reranker into RAG applications.
What is Reranker?
Reranker is an important part of the Information Retrieval (IR) ecosystem for evaluating search results and reordering them to improve query relevance. In RAG applications, Reranker is mainly used after getting the results of a vector query (ANN), which enables more effective determination of semantic relevance between documents and queries, more fine-grained re-ranking of the results, and ultimately improves the quality of the search.
step 1: Part Reranker
- Theoretical learning:
- RAG Documentation Search - Reranker Section
- Practical skills:
- [Reranker - bge-reranker chapter]
Module 6: RAG Evaluation Surfaces
Why do I need to review the RAG?
In the process of exploring and optimizing RAGs (Retrieval Augmentation Generators), how to effectively evaluate their performance has become a key issue.
step 1: RAG Review
- Theoretical learning:
- [RAG Review]
Module 7: RAG Open Source Project Recommended Learning
Why do I need RAG Open Source Project Recommended Learning?
Having taken you through the various processes of RAG, here are some recommended RAG open source projects to help the big boys digest and learn.
RAG Open Source Project Recommendations - RAGFlow Article
- Introduction: RAGFlow is an open source RAG (Retrieval-Augmented Generation) engine built on deep document understanding. RAGFlow provides a streamlined RAG workflow for organizations and individuals of all sizes, combined with a Large Language Model (LLM) to provide reliable RAGFlow provides a streamlined RAG workflow for organizations and individuals of all sizes, combined with a Large Language Model (LLM) to provide reliable questions, answers, and justifiable citations for a wide range of complex data formats.
- Project Learning:
- RAG Project Recommendations - RagFlow Part 1 - RagFlow docker deployment
- RAG Project Recommendation - RagFlow Part (II) - RagFlow Knowledge Base Construction].
- RAG Project Recommendation - RagFlow Part (3) - RagFlow Model Vendor Selection].
- RAG Project Recommendation - RagFlow Part (IV) - RagFlow Dialog]
- RAG Project Recommendation - RagFlow Part (V) - RAGFlow Api Access (to) ollama (for example)]
- RAG Project Recommendations - RagFlow Part (VI) - RAGFlow Source Code Study].
RAG Open Source Project Recommendations -- QAnything
- Introduction: QAnything (Question and Answer based on Anything) is a local knowledge base question and answer system designed to support a wide range of file formats and databases, allowing offline installation and use. With QAnything, you can simply delete locally stored files in any format and get accurate, fast and reliable answers.QAnything currently supports knowledge base file formats including: PDF(pdf) , Word(docx) , PPT(pptx) , XLS(xlsx) , Markdown(md) , Email (eml) , TXT (txt), Image (jpg, jpeg, png), CSV (csv), web links (html) and so on.
- Project Learning:
- RAG open source project recommendations -- QAnything [Piece of writing]
RAG Open Source Project Recommendations -- ElasticSearch-Langchain Article
- INTRODUCTION: Inspired by the langchain-ChatGLM project, since Elasticsearch can realize mixed query in both text and vector and is more widely used in business scenarios, this project uses Elasticsearch instead of Faiss as a knowledge repository, and utilizes Langchain+Chatglm2 to realize an intelligent quiz based on the Intelligent Q&A based on own knowledge base using Langchain+Chatglm2.
- Project Learning:
- [LLMs Getting Started] Efficient 🤖ElasticSearch-Langchain-Chatglm2 Based on Local Knowledge Base]
RAG Open Source Project Recommendations - Langchain-Chatchat Article
- Introduction: Langchain-Chatchat (formerly Langchain-ChatGLM) Local Knowledge Base QA based on Langchain and ChatGLM language models | Langchain-Chatchat (formerly langchain-chatGLM), local knowledge based LLM (like ChatGLM) QA app with langchain
- Project Learning:
- [LLMs Getting Started] Efficient 🤖Langchain-Chatchat Based on Local Knowledge Base]
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...