X-Dyna: Static Portrait Reference Video Pose Generation Video to Make Missy's Photos Dance

General Introduction
X-Dyna is an open source project developed by ByteDance to generate dynamic portrait animations through zero-sample diffusion techniques. The project utilizes facial expressions and body movements in the driving video to animate individual portrait images, generating realistic and context-aware dynamics. x-Dyna enhances the vividness and detail of portrait video animations by introducing a dynamic adapter module that seamlessly integrates the appearance context of the reference image into the spatial attention of the diffusion backbone network.
Related Recommendations:StableAnimator: generates high quality video animation that maintains the character's features. ,DisPose: generating videos with precise control of human posture, creating dancing ladies ,MOFA Video: Motion Field Adaptation Technology Converts Still Images to Video

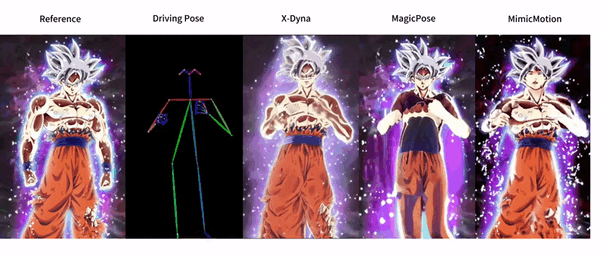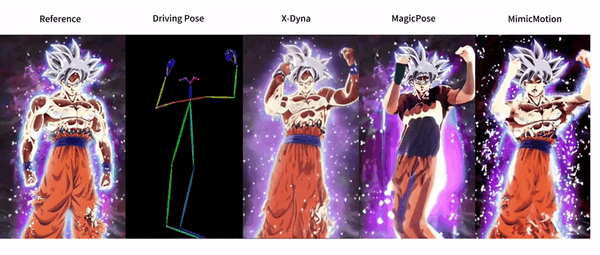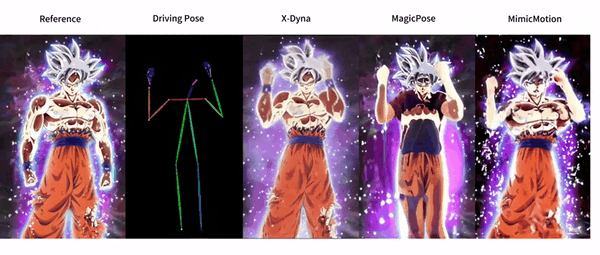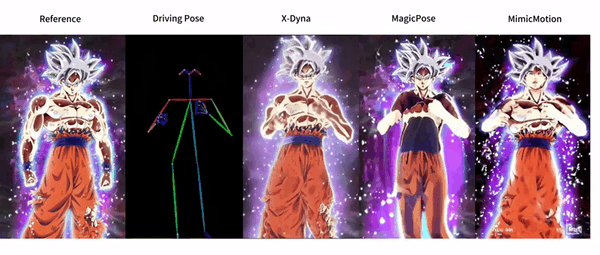
Function List
- Dynamic Portrait Animation Generation: Generate realistic dynamic portrait animations using facial expressions and body movements in the drive video.
- Zero-sample diffusion technique: generate high-quality animations without pre-training data.
- Dynamic Adapter Module: Integrates reference image context to enhance the detail and vividness of animations.
- Facial Expression Transfer: Capture facial expressions through the local control module for precise expression transfer.
- Evaluation Codes: Provide a variety of evaluation metrics (e.g., DTFVD, Face-Cos, Face-Det, FID, etc.) for assessing animation quality.
- Open source code and models: complete inference code and pre-trained models are provided for ease of use and secondary development.
Using Help
Installation process
- Cloning Project Warehouse:
git clone https://github.com/bytedance/X-Dyna.git
cd X-Dyna
- Install the dependencies:
pip install -r requirements.txt
- Install the PyTorch 2.0 environment:
bash env_torch2_install.sh
Usage
- Prepare the input image and drive video:
- Input image: A single portrait image.
- Drive Video: A video containing the target's facial expressions and body movements.
- Run the inference code to generate the animation:
python inference_xdyna.py --input_image path_to_image --driving_video path_to_video
- Evaluate the quality of the generated animation:
- The quality of the generated animations was assessed using the provided evaluation code and dataset.
python evaluate.py --generated_video path_to_generated_video --metrics DTFVD,Face-Cos,Face-Det,FID
Detailed function operation flow
- Dynamic Portrait Animation Generation::
- Select a static portrait image as input.
- Select a drive video that contains the target's movements and expressions.
- Run inference code to generate dynamic portrait animations.
- transfer of facial expression::
- Capture facial expressions in drive videos using the local control module.
- Transfer the captured expression to the input image for precise expression animation.
- Dynamic Adapter Module::
- The dynamic adapter module seamlessly integrates the appearance context of the reference image into the spatial attention of the diffusion backbone network.
- In this way, the generated animation retains more detail and vividness.
- Evaluation Code::
- A variety of evaluation metrics (e.g., DTFVD, Face-Cos, Face-Det, FID, etc.) are provided for assessing the quality of the generated animations.
- Users can fully evaluate the generated animations based on these metrics.
- Open source code and models::
- The project provides complete inference code and pre-trained models, which can be easily used by users for secondary development and customized applications.
Frequently Asked Questions.
- Animation is not smooth: Try to increase
num_mixor adjustmentsddim_stepsThe - mismatch in facial expression: Ensure that the choice of
best_framecorresponds to the frame in the drive video that is most similar in expression to the source image.
Advanced Use.
- optimize performance: The speed of generation can be improved by reducing the number of inference steps using the LCM LoRA model.
- Custom Models: If you have specific needs, you can modify or extend the model according to the guidance in the README.
With these steps, users can easily get started with X-Dyna to generate high-quality dynamic portrait animations, and fully evaluate and optimize the generated animations.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...