
A 10,000-word article on RAG optimization in DB-GPT real-world scenarios.

preamble
Over the past two years, Retrieval-Augmented Generation (RAG, Retrieval-Augmented Generation) technology has gradually become a core component of enhanced intelligences. By combining the dual capabilities of retrieval and generation, RAG is able to introduce external knowledge, thus providing more possibilities for the application of large models in complex scenarios. However, in practical landing scenarios, there are often problems of low retrieval accuracy, much noise interference, recall completeness, and insufficient professionalism, leading to serious LLM illusions. In this paper, we will focus on the knowledge processing and retrieval details of RAG in actual landing scenarios, and how to go about optimizing the RAG Pineline link to ultimately improve the recall accuracy.
It's easy to quickly build a RAG smart Q&A app, but landing it in a real business scenario requires a lot of preparation.
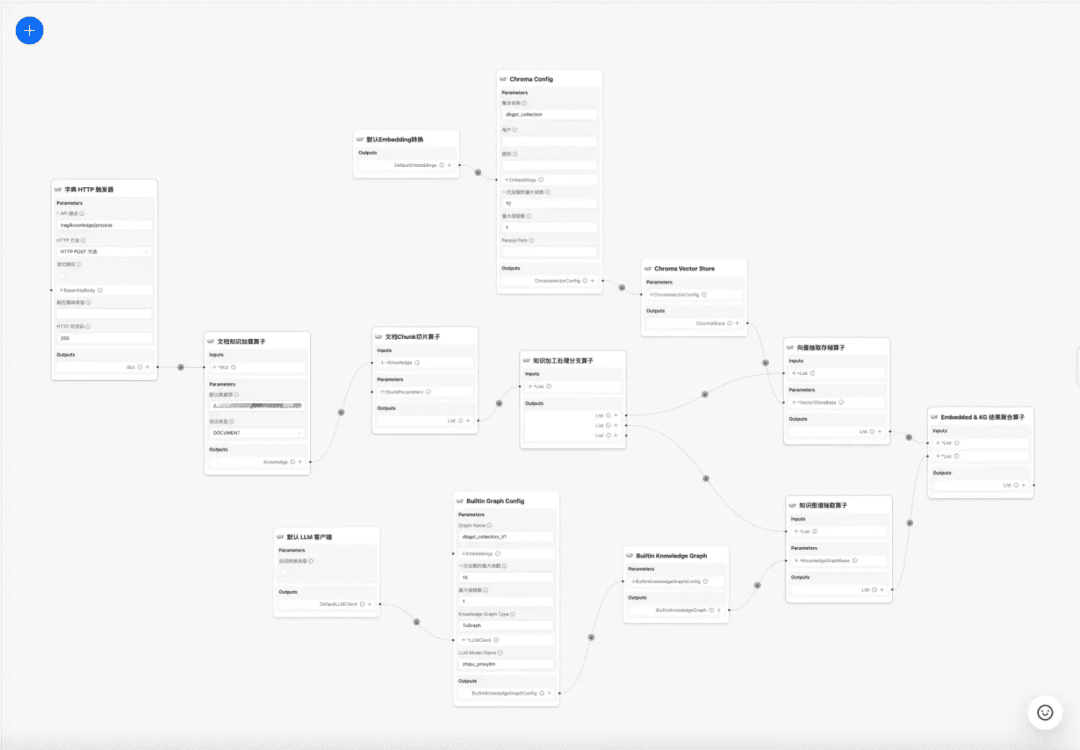
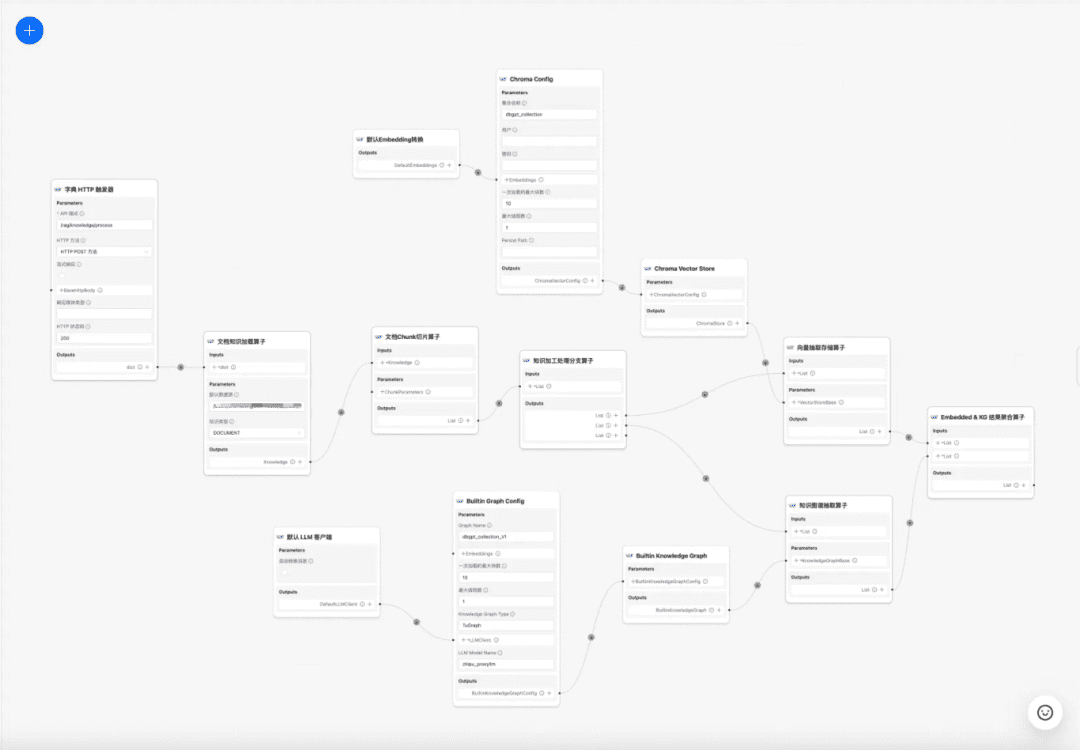
1.RAG key process source code interpretation
mainly divided intoknowledge processingcap (a poem)RAGSome of the key processes:
1. Knowledge processing
Knowledge loading -> Knowledge slicing -> Information extraction -> Knowledge processing (embedding/graph/keywords) -> Knowledge storage
- Knowledge loading
# 知识工厂进行实例化 KnowledgeFactory -> create() -> load() -> Document - knowledge - markdown - pdf - docx - txt - html - pptx - url - ...
How to expand:
from abc import ABC from typing import List, Any class Knowledge(ABC): def load(self) -> List[Document]: """Load knowledge from data loader.""" pass @classmethod def document_type(cls) -> Any: """Get document type.""" pass @classmethod def support_chunk_strategy(cls) -> List[ChunkStrategy]: """Return supported chunk strategy.""" return [ ChunkStrategy.CHUNK_BY_SIZE, ChunkStrategy.CHUNK_BY_PAGE, ChunkStrategy.CHUNK_BY_PARAGRAPH, ChunkStrategy.CHUNK_BY_MARKDOWN_HEADER, ChunkStrategy.CHUNK_BY_SEPARATOR, ] @classmethod def default_chunk_strategy(cls) -> ChunkStrategy: """ Return default chunk strategy. Returns: ChunkStrategy: default chunk strategy """ return ChunkStrategy.CHUNK_BY_SIZE
- knowledge slice
ChunkManager: Routes the loaded knowledge data to the corresponding chunk processor for allocation according to the user-specified chunking policy and chunking parameters.
class ChunkManager: """Manager for chunks.""" def __init__( self, knowledge: Knowledge, chunk_parameter: Optional[ChunkParameters] = None, extractor: Optional[Extractor] = None, ): """ Create a new ChunkManager with the given knowledge. Args: knowledge: (Knowledge) Knowledge datasource. chunk_parameter: (Optional[ChunkParameters]) Chunk parameter. extractor: (Optional[Extractor]) Extractor to use for summarization. """ self._knowledge = knowledge self._extractor = extractor self._chunk_parameters = chunk_parameter or ChunkParameters() self._chunk_strategy = ( chunk_parameter.chunk_strategy if chunk_parameter and chunk_parameter.chunk_strategy else self._knowledge.default_chunk_strategy().name ) self._text_splitter = self._chunk_parameters.text_splitter self._splitter_type = self._chunk_parameters.splitter_type
How to extend: if you want to customize a new sharding strategy in the interface
- New slicing strategy
- Add Splitter implementation logic
class ChunkStrategy(Enum):
"""Chunk Strategy Enum."""
CHUNK_BY_SIZE: _STRATEGY_ENUM_TYPE = (
RecursiveCharacterTextSplitter,
[
{
"param_name": "chunk_size",
"param_type": "int",
"default_value": 512,
"description": "The size of the data chunks used in processing.",
},
{
"param_name": "chunk_overlap",
"param_type": "int",
"default_value": 50,
"description": "The amount of overlap between adjacent data chunks.",
},
],
"chunk size",
"split document by chunk size",
)
CHUNK_BY_PAGE: _STRATEGY_ENUM_TYPE = (
PageTextSplitter,
[],
"page",
"split document by page",
)
CHUNK_BY_PARAGRAPH: _STRATEGY_ENUM_TYPE = (
ParagraphTextSplitter,
[
{
"param_name": "separator",
"param_type": "string",
"default_value": "\n",
"description": "paragraph separator",
}
],
"paragraph",
"split document by paragraph",
)
CHUNK_BY_SEPARATOR: _STRATEGY_ENUM_TYPE = (
SeparatorTextSplitter,
[
{
"param_name": "separator",
"param_type": "string",
"default_value": "\n",
"description": "chunk separator",
},
{
"param_name": "enable_merge",
"param_type": "boolean",
"default_value": False,
"description": (
"Whether to merge according to the chunk_size after "
"splitting by the separator."
),
},
],
"separator",
"split document by separator",
)
CHUNK_BY_MARKDOWN_HEADER: _STRATEGY_ENUM_TYPE = (
MarkdownHeaderTextSplitter,
[],
"markdown header",
"split document by markdown header",
)
- Knowledge extraction
- Vector extraction -> embedding, implementation
Embeddingsconnector
@abstractmethod def embed_documents(self, texts: List[str]) -> List[List[float]]: """Embed search docs.""" @abstractmethod def embed_query(self, text: str) -> List[float]: """Embed query text.""" async def aembed_documents(self, texts: List[str]) -> List[List[float]]: """Asynchronous Embed search docs.""" return await asyncio.get_running_loop().run_in_executor( None, self.embed_documents, texts ) async def aembed_query(self, text: str) -> List[float]: """Asynchronous Embed query text.""" return await asyncio.get_running_loop().run_in_executor( None, self.embed_query, text )
# EMBEDDING_MODEL=proxy_openai
# proxy_openai_proxy_server_url=https://api.openai.com/v1
# proxy_openai_proxy_api_key={your-openai-sk}
# proxy_openai_proxy_backend=text-embedding-ada-002
## qwen embedding model, See dbgpt/model/parameter.py
# EMBEDDING_MODEL=proxy_tongyi
# proxy_tongyi_proxy_backend=text-embedding-v1
# proxy_tongyi_proxy_api_key={your-api-key}
## qianfan embedding model, See dbgpt/model/parameter.py
# EMBEDDING_MODEL=proxy_qianfan
# proxy_qianfan_proxy_backend=bge-large-zh
# proxy_qianfan_proxy_api_key={your-api-key}
# proxy_qianfan_proxy_api_secret={your-secret-key}
- Knowledge graph extraction -> knowledge graph
class TripletExtractor(LLMExtractor):
"""TripletExtractor class."""
def __init__(self, llm_client: LLMClient, model_name: str):
"""Initialize the TripletExtractor."""
super().__init__(llm_client, model_name, TRIPLET_EXTRACT_PT)
TRIPLET_EXTRACT_PT = (
"Some text is provided below. Given the text, "
"extract up to knowledge triplets as more as possible "
"in the form of (subject, predicate, object).\n"
"Avoid stopwords. The subject, predicate, object can not be none.\n"
"---------------------\n"
"Example:\n"
"Text: Alice is Bob's mother.\n"
"Triplets:\n(Alice, is mother of, Bob)\n"
"Text: Alice has 2 apples.\n"
"Triplets:\n(Alice, has 2, apple)\n"
"Text: Alice was given 1 apple by Bob.\n"
"Triplets:(Bob, gives 1 apple, Alice)\n"
"Text: Alice was pushed by Bob.\n"
"Triplets:(Bob, pushes, Alice)\n"
"Text: Bob's mother Alice has 2 apples.\n"
"Triplets:\n(Alice, is mother of, Bob)\n(Alice, has 2, apple)\n"
"Text: A Big monkey climbed up the tall fruit tree and picked 3 peaches.\n"
"Triplets:\n(monkey, climbed up, fruit tree)\n(monkey, picked 3, peach)\n"
"Text: Alice has 2 apples, she gives 1 to Bob.\n"
"Triplets:\n"
"(Alice, has 2, apple)\n(Alice, gives 1 apple, Bob)\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Triplets:\n"
"(Philz, is, coffee shop)\n(Philz, founded in, Berkeley)\n"
"(Philz, founded in, 1982)\n"
"---------------------\n"
"Text: {text}\n"
"Triplets:\n"
)
- Reverse Index Extraction -> keywords segmentation
- You can use the es default lexicon, or you can customize the lexicon using the es plugin mode
- Reverse Index Extraction -> keywords segmentation
- Knowledge storage
The entire knowledge persistence uniformly implements theIndexStoreBaseinterface, currently provides three types of implementations: vector databases, graph databases, full-text indexing

- VectorStore, vector database main logic are in load_document(), including index schema creation, vector data batch write and so on.
# Base class hierarchy - VectorStoreBase - ChromaStore - MilvusStore - OceanbaseStore - ElasticsearchStore - PGVectorStore # Base class definition class VectorStoreBase(IndexStoreBase, ABC): """ Vector store base class. """ @abstractmethod def load_document(self, chunks: List[Chunk]) -> List[str]: """ Load document in index database. """ pass @abstractmethod async def aload_document(self, chunks: List[Chunk]) -> List[str]: """ Load document in index database asynchronously. """ pass @abstractmethod def similar_search_with_scores( self, text: str, topk: int, score_threshold: float, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Perform a similar search with scores in the index database. """ pass def similar_search( self, text: str, topk: int, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Perform a similar search in the index database. """ return self.similar_search_with_scores(text, topk, 1.0, filters)
- GraphStore , the specific graph store provides an implementation of ternary writing, which is generally done by calling the query language of the specific graph database. For example
TuGraphStoreA specific Cypher statement will be generated and executed based on the ternary.
- The graph storage interface GraphStoreBase provides a unified graph storage abstraction and currently has built-in
MemoryGraphStorecap (a poem)TuGraphStoreimplementation, we also provide Neo4j interface to developers for access.
- The graph storage interface GraphStoreBase provides a unified graph storage abstraction and currently has built-in
# GraphStoreBase -> TuGraphStore -> Neo4jStore
def insert_triplet(self, subj: str, rel: str, obj: str) -> None:
"""Add triplet."""
# Create queries to merge nodes and relationship
subj_query = f"MERGE (n1:{self._node_label} {{id:'{subj}'}})"
obj_query = f"MERGE (n2:{self._node_label} {{id:'{obj}'}})"
rel_query = (
f"MERGE (n1:{self._node_label} {{id:'{subj}'}})"
f"-[r:{self._edge_label} {{id:'{rel}'}}]->"
f"(n2:{self._node_label} {{id:'{obj}'}})"
)
# Execute queries
self.conn.run(query=subj_query)
self.conn.run(query=obj_query)
self.conn.run(query=rel_query)
- FullTextStore: by building es index, through es built-in word splitting algorithm for word splitting, and then by es to build keyword->doc_id inverted index.
{
"analysis": {
"analyzer": {
"default": {
"type": "standard"
}
}
},
"similarity": {
"custom_bm25": {
"type": "BM25",
"k1": self._k1,
"b": self._b
}
}
}
self._es_mappings = {
"properties": {
"content": {
"type": "text",
"similarity": "custom_bm25"
},
"metadata": {
"type": "keyword"
}
}
}
# FullTextStoreBase
# ElasticDocumentStore
# OpenSearchStore
2. Knowledge retrieval
question -> rewrite -> similarity_search -> rerank -> context_candidates
Next is knowledge retrieval, the current community retrieval logic is mainly divided into these steps, if you set the query rewriting parameters, currently will give you a round of question rewriting through the big model, and then it will be routed to the corresponding retriever according to your knowledge processing way, if you are processed through the vectors, it will be retrieved through the EmbeddingRetriever, if you build way is constructed through knowledge graph, it will be retrieved according to the knowledge graph way, if you set up the rerank model, it will give the candidate values after coarse screening a fine screening to make the candidate values more relevant to the user's question.
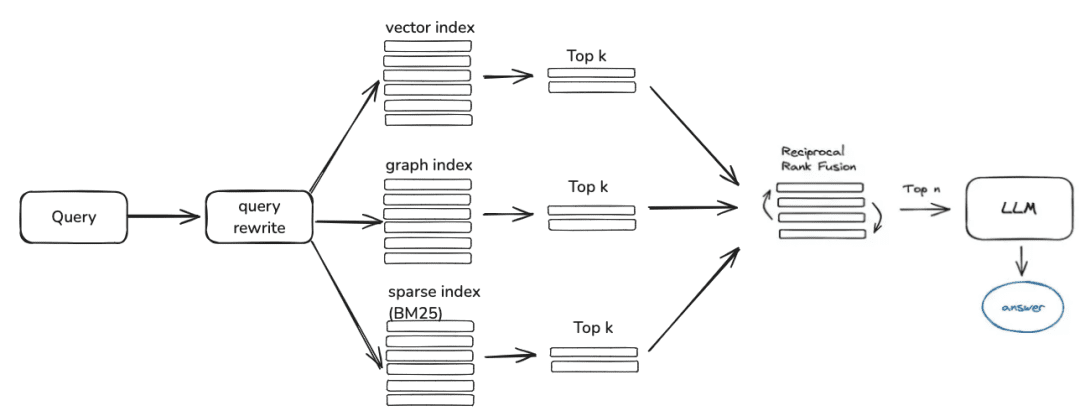
- EmbeddingRetriever
class EmbeddingRetriever(BaseRetriever): """Embedding retriever.""" def __init__( self, index_store: IndexStoreBase, top_k: int = 4, query_rewrite: Optional[QueryRewrite] = None, rerank: Optional[Ranker] = None, retrieve_strategy: Optional[RetrieverStrategy] = RetrieverStrategy.EMBEDDING, ): pass async def _aretrieve_with_score( self, query: str, score_threshold: float, filters: Optional[MetadataFilters] = None, ) -> List[Chunk]: """ Retrieve knowledge chunks with score. Args: query (str): Query text. score_threshold (float): Score threshold. filters: Metadata filters. Returns: List[Chunk]: List of chunks with score. """ queries = [query] new_queries = await self._query_rewrite.rewrite( origin_query=query, context=context, nums=1 ) queries.extend(new_queries) candidates_with_score = [ self._similarity_search_with_score( query, score_threshold, filters, root_tracer.get_current_span_id() ) for query in queries ] new_candidates_with_score = await self._rerank.arank( new_candidates_with_score, query ) return new_candidates_with_score
- index_store: specific vector database
- top_k: number of specific candidate chunks returned
- query_rewrite: query rewrite function
- rerank: reordering function
- query:Original query
- score_threshold: score, by default we filter out contexts with a similarity score less than a threshold value
- filters:
Optional[MetadataFilters], metadata information filter, mainly can be used to front through the attribute information to sieve out some of the mismatched candidate information.
from enum import Enum from typing import Union, List from pydantic import BaseModel, Field class FilterCondition(str, Enum): """Vector Store Meta data filter conditions.""" AND = "and" OR = "or" class MetadataFilter(BaseModel): """Meta data filter.""" key: str = Field( ..., description="The key of metadata to filter." ) operator: FilterOperator = Field( default=FilterOperator.EQ, description="The operator of metadata filter." ) value: Union[str, int, float, List[str], List[int], List[float]] = Field( ..., description="The value of metadata to filter." )
- Graph RAG
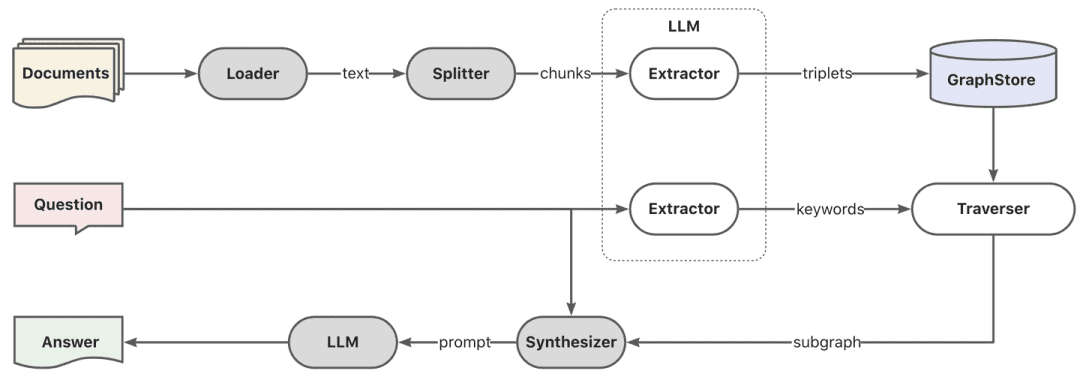
Firstly, keyword extraction is performed through the model, here can be done through the traditional nlp technique for word splitting, or through the big model for word splitting, and then the keywords are done according to the synonyms to do the expansion, to find the keyword candidate list, and it is better to recall the local subgraphs according to the keyword candidate list by calling the explore method.
KEYWORD_EXTRACT_PT = (
"A question is provided below. Given the question, extract up to "
"keywords from the text. Focus on extracting the keywords that we can use "
"to best lookup answers to the question.\n"
"Generate as more as possible synonyms or alias of the keywords "
"considering possible cases of capitalization, pluralization, "
"common expressions, etc.\n"
"Avoid stopwords.\n"
"Provide the keywords and synonyms in comma-separated format."
"Formatted keywords and synonyms text should be separated by a semicolon.\n"
"---------------------\n"
"Example:\n"
"Text: Alice is Bob's mother.\n"
"Keywords:\nAlice,mother,Bob;mummy\n"
"Text: Philz is a coffee shop founded in Berkeley in 1982.\n"
"Keywords:\nPhilz,coffee shop,Berkeley,1982;coffee bar,coffee house\n"
"---------------------\n"
"Text: {text}\n"
"Keywords:\n"
)
def explore(
self,
subs: List[str],
direct: Direction = Direction.BOTH,
depth: Optional[int] = None,
fan: Optional[int] = None,
limit: Optional[int] = None,
) -> Graph:
"""Explore on graph."""
DBSchemaRetrieverThis is partly a schema-linking search for ChatData scenariosMainly through schema-linking way by two-stage similarity retrieval, first find the most relevant table first, then the most relevant field information.
Pros: this two-stage search is also intended to address community feedback about the large wide table experience.
def _similarity_search(self, query, filters: Optional[MetadataFilters] = None) -> List[Chunk]:
"""Similar search."""
# Perform similarity search with scores
table_chunks = self._table_vector_store_connector.similar_search_with_scores(
query, self._top_k, 0, filters
)
# Filter out chunks with 'separated' metadata
not_sep_chunks = [
chunk for chunk in table_chunks if not chunk.metadata.get("separated")
]
separated_chunks = [
chunk for chunk in table_chunks if chunk.metadata.get("separated")
]
# If no separated chunks, return the non-separated chunks
if not separated_chunks:
return not_sep_chunks
# Create tasks list for retrieving fields from separated chunks
tasks = [
lambda c=chunk: self._retrieve_field(c, query) for chunk in separated_chunks
]
# Run tasks concurrently with a concurrency limit of 3
separated_result = run_tasks(tasks, concurrency_limit=3)
# Combine and return results
return not_sep_chunks + separated_result
- table_vector_store_connector: responsible for retrieving the most relevant tables.
- field_vector_store_connector: responsible for retrieving the most relevant fields.
2. Knowledge processing, knowledge retrieval optimization ideas
Currently RAG Smart Q&A apps several pain points:
- After more and more documents in the knowledge base, the retrieval noise is high and the recall accuracy is not high
- Incomplete recalls and lack of completeness
- Recalls and user question intent have little relevance
- Only being able to answer static data and not being able to access knowledge dynamically results in a dull and dumb answering application.
1. Knowledge Processing Optimization
Unstructured/semi-structured/structured data processing, ready to determine the upper limit of the RAG application, so first of all need to do a lot of fine-grained ETL work in the knowledge processing, indexing stage, the main optimization of the direction of the idea:
- Unstructured -> Structured: structured organization of knowledge information.
- Extract richer, more diverse semantic information.
1.1 Knowledge loading
Purpose: Accurate parsing of documents is needed to recognize different types of data in a more diversified way.
Optimization Recommendations:
- It is recommended that docx, txt or other text prior to processing for pdf or markdown format, so that you can use some recognition tools to better extract the contents of the text.
- Extracts table information from text.
- Preserve markdown and pdf title hierarchy information for the next hierarchical relationship tree and other indexing methods to prepare.
- Retain image links, formulas, and other information, also uniformly processed into markdown format.
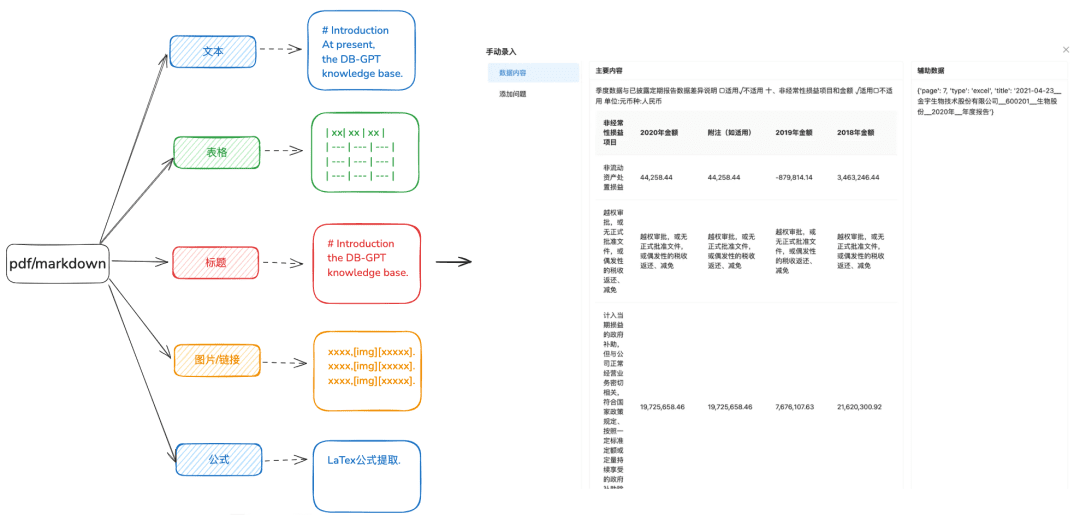
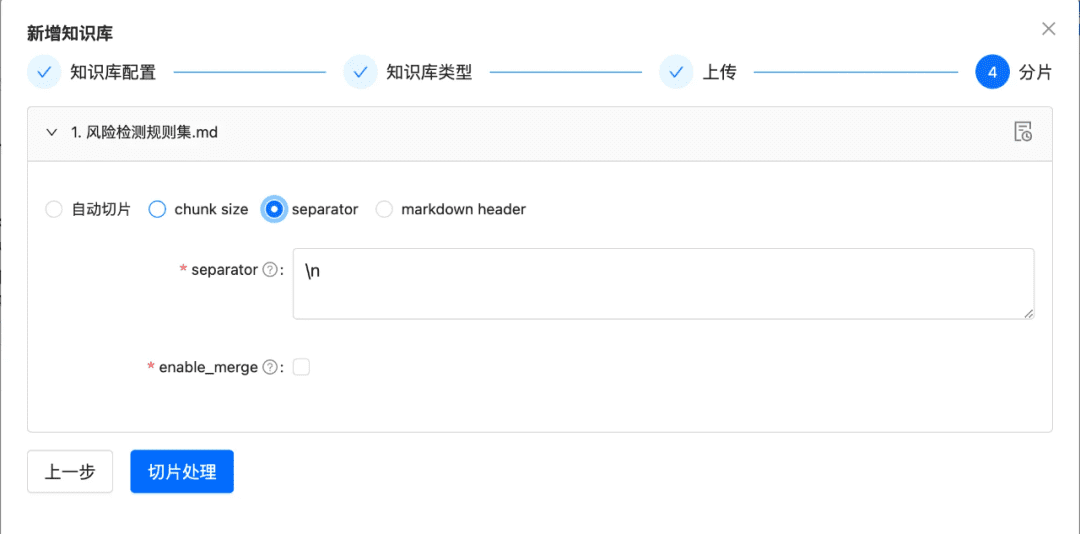
1.2 Slice Chunk as intact as possible
Purpose: To preserve contextual integrity and relevance, which is directly related to response accuracy.
Staying within the contextual limits of the larger model, chunking ensures that the text input to LLMs does not exceed their token limits.
Optimization Recommendations:
- Images + Tables extracted as separate Chunks, keeping table and image captions in metadata metadata
- Document content is split as much as possible according to the header hierarchy or Markdown Header, preserving the integrity of the chunk as much as possible.
- If there is a custom separator you can slice and dice by the custom separator.
1.3 Diversified information extraction
In addition to Embedding vector extraction of documents, other diversified information extraction can enhance the data of documents and significantly improve the RAG recall effect.
- knowledge map
- Advantages: 1. Addressing the lack of completeness of NativeRAG, there is still the problem of illusion, and the accuracy of knowledge, including the completeness of knowledge boundaries, the clarity of knowledge structure and semantics, is a semantic complement to the ability of similarity retrieval.
- Scenarios: For rigorous specialized fields (medical, O&M, etc.) where the preparation of knowledge needs to be constrained and where hierarchical relationships between knowledge can be clearly established.
- How to realize:
1. Depend on the big model to extract (entity,relationship,entity) ternary relationship.
2. Relying on pre-quality, structured knowledge preparation, cleaning, extraction, through business rules through manual or custom SOP process to build knowledge graph.
- Doc Tree
- Applicable scenarios: solves the problem of insufficient contextual integrity, but also matches based entirely on semantics and keywords, and can reduce noise
- How to realize: build a tree node of chunk with title level to form a multinomial tree structure, each level node only needs to store the document title, leaf nodes store the specific text content. In this way, using the tree traversal algorithm, if the user question hits the relevant non-leaf title node, the relevant child node data can be recalled. This way there is no problem of chunk integrity deficiency.
This part of the Feature we will also put into the community early next year.
- Extracting QA pairs requires front-end extraction of QA pair information by predefined or model extraction methods
- Applicable Scenarios:
- The ability to hit the question in the retrieval and direct recall, directly retrieve the answer the user wants, applicable to some FAQ scenarios, recall integrity is not enough scenarios.
- How to realize:
- Predefined: add some questions for each chunk in advance
- Model Extraction: Given a context, let the model perform QA pair extraction.
- Metadata extraction
- How to realize: According to the characteristics of their own business data, extract the characteristics of the data for retention, such as tags, categories, time, version and other metadata attributes.
- Applicable scenarios: retrieval can be pre-filtered to remove most of the noise based on metadata attributes.
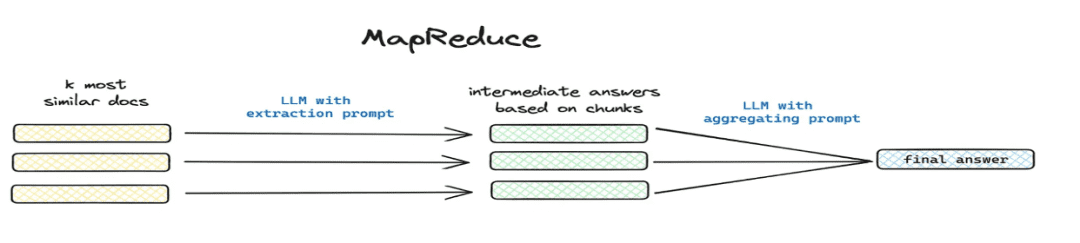
- summarize and extract
- Applicable scenarios: settlement
这篇文章讲了个啥(math.) genus总结一下and other global problem scenarios. - How to implement: segmented extraction via mapreduce etc., extract summary information for each chunk via model.
- Applicable scenarios: settlement
1.4 Knowledge processing workflow
at the present time DB-GPT Knowledge base provides knowledge processing capabilities such as document uploading -> parsing -> slicing -> Embedding -> knowledge graph triad extraction -> vector database storage -> graph database storage, etc., but it does not have the ability to extract complex and personalized information from documents, so it is hoped that by constructing a knowledge processing workflow template to complete the complex, visual, user-defined knowledge extraction, transformation, and processing processes. Therefore, we hope to build a knowledge processing workflow template to complete the complex, visualized, user-definable knowledge extraction, conversion, processing process.
Knowledge processing workflow:
https://www.yuque.com/eosphoros/dbgpt-docs/vg2gsfyf3x9fuglf
2. RAG process optimization RAG process optimization we are divided into a static document RAG and dynamic data acquisition RAG, most of the current RAG involved only covers the unstructured document static assets, but the actual business of many scenarios of the Q&A is through the tool to obtain dynamic data + static knowledge data together to answer the scenario, not only need to retrieve the static knowledge, but also need to be RAG not only need to retrieve the static knowledge, but also need the RAG to retrieve the information of the tools inside the tool asset library and execute the acquisition of dynamic data.
2.1 Static Knowledge RAG Optimization
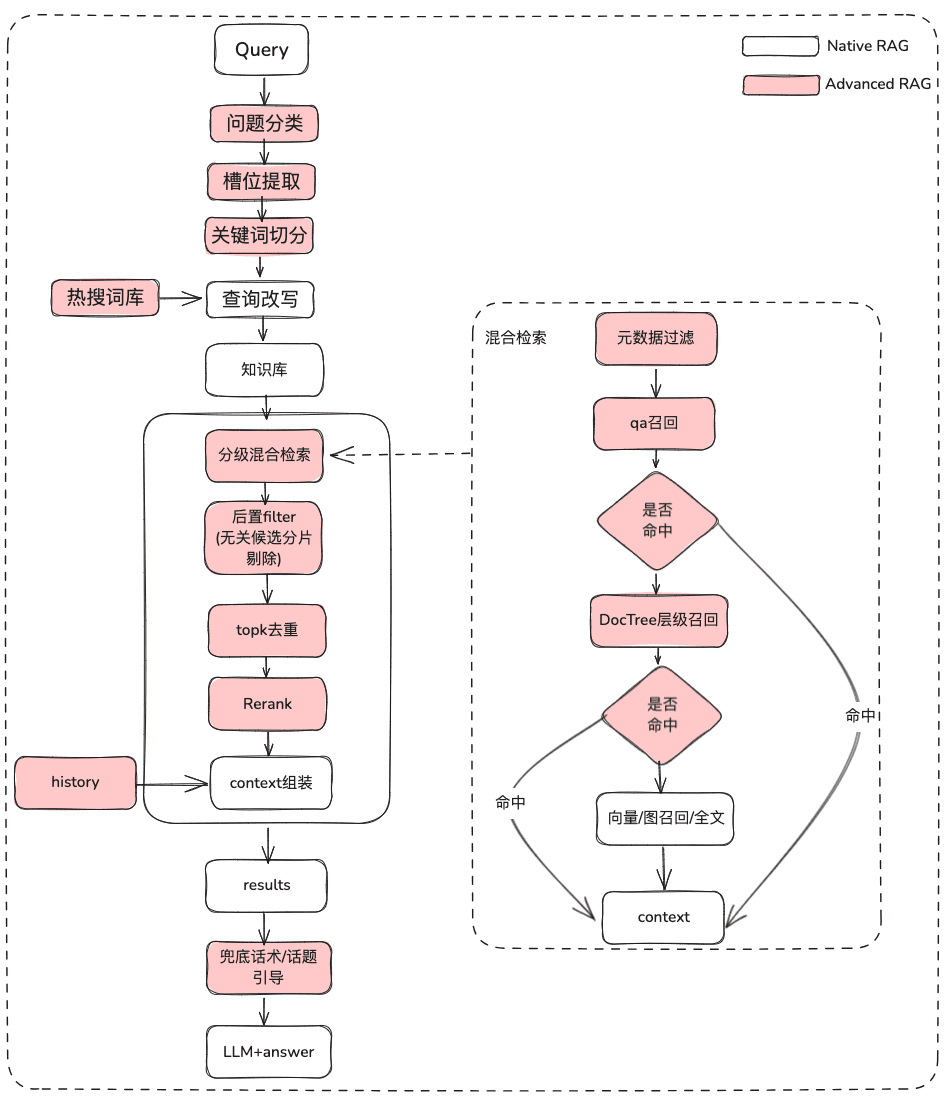
(1) Treatment of the original problem
Purpose: Clarify user semantics and optimize the user's original question from a fuzzy, ill-intended query to a retrievable Query that is richer in meaning.
- Raw problem categorization, by which problems can be
- LLM classification (
LLMExtractor) - Constructing embedding + logistic regression to implement a two-tower model, text2nlu DB-GPT-Hub/src/dbgpt-hub-nlu/README.zh.md at main - eosphoros-ai/DB-GPT-Hub
- LLM classification (
- tip:Need high quality Embedding model, recommend bge-v1.5-large
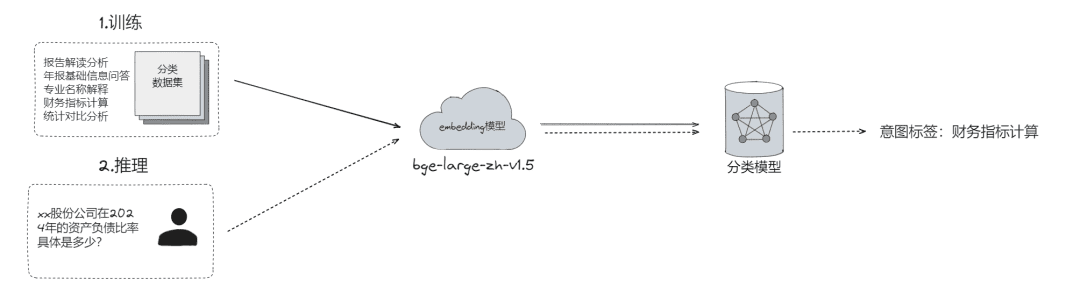
- Ask the user back, and if the semantics are not clear throw the question back to the user for question clarification, through multiple rounds of interaction
- Suggests a shortlist of questions to the user based on semantic relevance using a searchable thesaurus.
- Slot extraction, which aims to obtain key slot information in the user's question, such as intent, business attributes, and so on
- LLM extraction (
LLMExtractor)
- LLM extraction (
- Rewrite of the question
- Rewriting of the Hot Search Thesaurus
- multilayered interaction
(2) Metadata Filtering
When we divide the index into many chunks and are stored in the same knowledge space, retrieval efficiency will become a problem. For example, when users ask for information about "Zhejiang I Wu Technology Company", they do not want to recall information about other companies. Therefore, if you can filter by the company name metadata attribute first, it will greatly improve the efficiency and relevance.
async def aretrieve( self, query: str, filters: Optional[MetadataFilters] = None ) -> List[Chunk]: """ Retrieve knowledge chunks. Args: query (str): async query text. filters (Optional[MetadataFilters]): metadata filters. Returns: List[Chunk]: list of chunks """ return await self._aretrieve(query, filters)
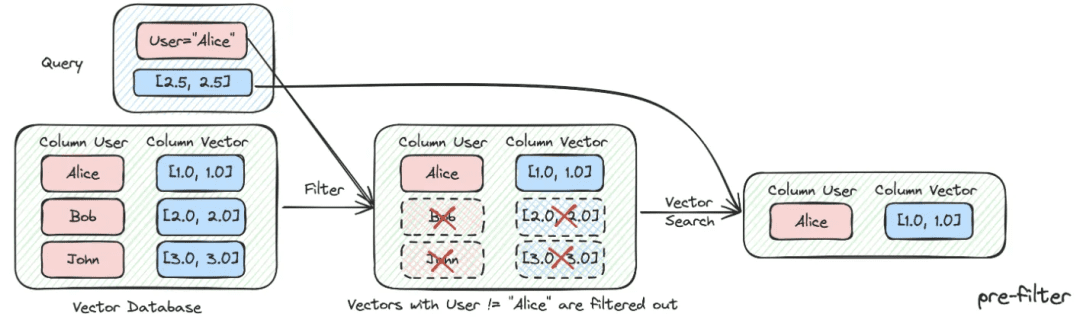
(3) Multi-strategy hybrid recall
- According to the priority recall, the priority is defined separately for different retrievers, and the content is returned immediately after retrieval
- Define different retrievals such as qa_retriever, doc_tree_retriever to be written to the queue, and prioritize the recall by using the first-in-first-out property of the queue.
class RetrieverChain(BaseRetriever): """Retriever chain class.""" def __init__( self, retrievers: Optional[List[BaseRetriever]] = None, executor: Optional[Executor] = None, ): """Create retriever chain instance.""" self._retrievers = retrievers or [] self._executor = executor or ThreadPoolExecutor() async def retrieve(self, query: str, score_threshold: float, filters: Optional[dict] = None): """Perform retrieval with the given query, score threshold, and filters.""" for retriever in self._retrievers: candidates_with_scores = await retriever.aretrieve_with_scores( query=query, score_threshold=score_threshold, filters=filters ) if candidates_with_scores: return candidates_with_scores
- Multi-Knowledge Indexing/Spatial Parallel Recall
- Getting candidate lists by parallel recall through different indexing forms of knowledge to ensure recall completeness
(4) Post-filtering
After going through the coarse screening candidate list, how do you filter the noise through the fine screening?
- Irrelevant Candidate Segmentation Rejection
- Timeliness rejection
- Business attributes do not satisfy culling
- topk de-duplication
- Reordering It is not enough to rely on the recall of coarse screening, at this time, we need to have some strategies to do reordering of the retrieved results, such as making some readjustments to the combination relevance, matching and other factors, to get the ordering that is more in line with our business scenarios. Because after this step, we will send the results to LLM for final processing, so the results of this part are very important.
- Fine screening using relevant reordering models, either open-source models or models with business semantic fine-tuning.
## Rerank model # RERANK_MODEL = bce-reranker-base #### If you do not set RERANK_MODEL_PATH, DB-GPT will read the model path from EMBEDDING_MODEL_CONFIG based on the RERANK_MODEL. # RERANK_MODEL_PATH = /Users/chenketing/Desktop/project/DB-GPT-NEW/DB-GPT/models/bce-reranker-base_v1 #### The number of rerank results to return # RERANK_TOP_K = 5
- Business RRF-weighted composite score culling based on different indexed recalls
score = 0.0 for q in queries: if d in result(q): score += 1.0 / (k + rank(result(q), d)) return score # where: # k is a ranking constant # q is a query in the set of queries # d is a document in the result set of q # result(q) is the result set of q # rank(result(q), d) is d's rank within the result(q) starting from 1
(5) Display Optimization + Touting / Topic Leads
- Getting the model to output using markdown formatting
基于以下给出的已知信息,遵守规范约束,专业、简要回答用户的问题。 规范约束: 1. 如果已知信息包含的图片、链接、表格、代码块等特殊 markdown 标签格式的信息,确保在答案中包含原文这些图片、链接、表格和代码标签,不要丢弃不要修改,例如: - 图片格式:`` - 链接格式:`[xxx](xxx)` - 表格格式:`|xxx|xxx|xxx|` - 代码格式:```xxx```。 2. 如果无法从提供的内容中获取答案,请说:“知识库中提供的内容不足以回答此问题”,禁止胡乱编造。 3. 回答的时候最好按照 1.2.3. 点进行总结,并以 Markdown 格式显示。
2.2 Dynamic Knowledge RAG Optimization
Documentation knowledge is relatively static, can not answer personalized and dynamic information, need to rely on some third-party platform tools to answer, based on this situation, we need some dynamic RAG approach, through the tool asset definition -> tool selection -> tool validation -> tool execution to obtain dynamic data.
(1) Tool Asset Library
Build an enterprise domain tool asset library to integrate tool APIs, tool scripts scattered to various platforms, and then provide end-to-end usage capability of intelligences. For example, in addition to the static knowledge base, we can process tools by importing tool libraries.

(2) Tool Recall
Tool recall follows the idea of RAG recall for static knowledge, and then the complete tool execution lifecycle is used to obtain the results of tool execution.
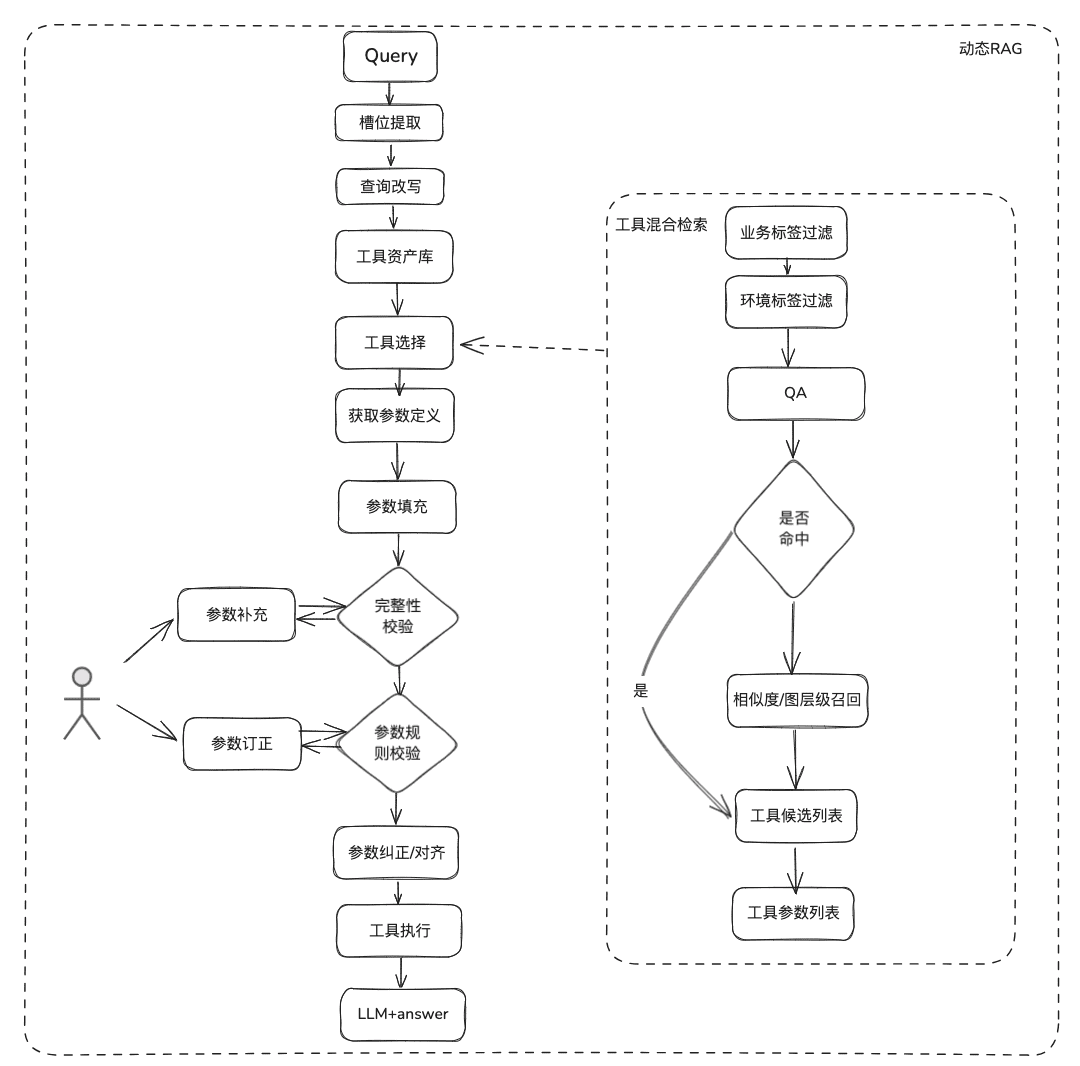
- Slot extraction: through the traditional nlp to obtain the LLM will be parsed user issues, including common business types, environmental standards, domain model parameters and so on
- Tool selection: recall along the lines of static RAG with two main layers, tool name recall and tool parameter recall.
- Tool Parameter Recall, which is similar in idea to TableRAG, recalls the table name first, then the field name.
- Parameter filling: need to be based on the recalled tool parameter definitions, and the slot extracted parameters to be matched
- You can code to populate it, or you can have the model populate it.
- Optimization Ideas: Since the parameter names of the same parameters of the various platform tools are not unified, and it is not convenient to go to the governance, it is suggested that you can first carry out a round of domain model data expansion, and after getting the whole domain model, the parameters that are needed will exist.
- parameter calibration
- Integrity check: performs integrity check on the number of parameters
- Parameter Rule Checking: Performs rule checking on parameter name type, parameter value, enumeration and so on.
- Parameter correction/alignment, this part is mainly to reduce the number of interactions with the user, automated completion of the user parameter error correction, including case rules, enumeration rules, etc. eg.
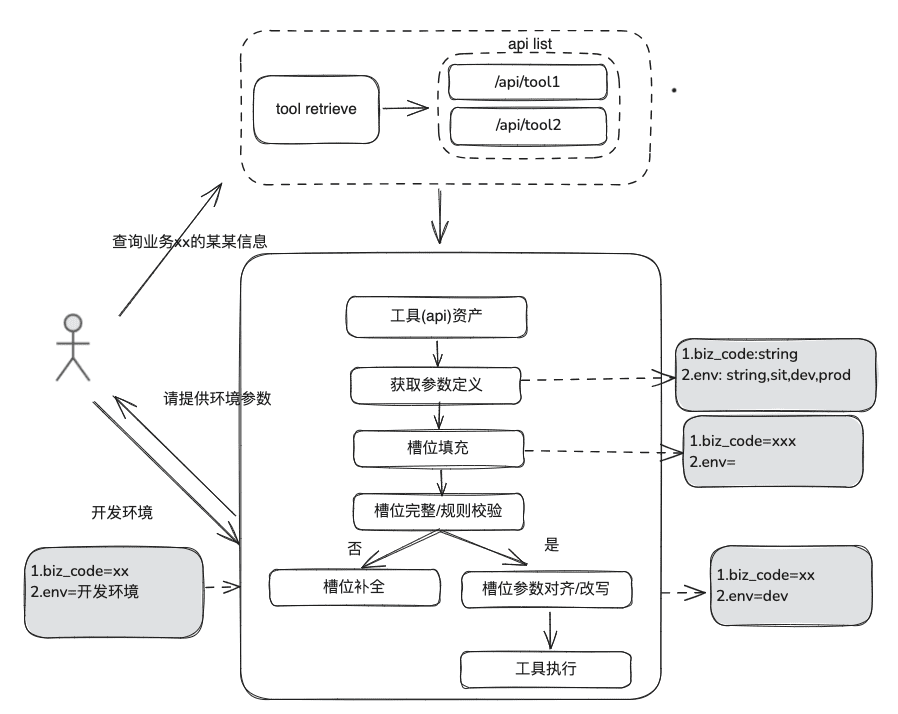
2.3 RAG Review
When evaluating the Smart Q&A process, the recall relevance accuracy as well as the relevance of the modeled Q&A need to be evaluated separately and then considered together to determine where the RAG process still needs to be improved.
Evaluation of indicators:
EvaluationMetric ├── LLMEvaluationMetric │ ├── AnswerRelevancyMetric ├── RetrieverEvaluationMetric │ ├── RetrieverSimilarityMetric │ ├── RetrieverMRRMetric │ └── RetrieverHitRateMetric
RAGRetrieverEvaluationMetric:RetrieverHitRateMetric:: The hit rate measures the RAGretrieverThe proportion of recalls appearing in the top-k documents of the retrieval results.RetrieverMRRMetric:Mean Reciprocal RankThe accuracy of each query is calculated by analyzing the ranking of the most relevant documents in the search results. More specifically, it is the average of the inverse rank of relevant documents for all queries. For example, if the most relevant document is ranked first, its inverse rank is 1; if it is ranked second, it is 1/2; and so on.RetrieverSimilarityMetric: Similarity metrics are calculated to compute the similarity between recalled content and predicted content.
模型生成Answer Indicator.
AnswerRelevancyMetric:: Intelligent body answer relevance metrics by how well the intelligent body answer matches the user's question. A high relevance answer not only requires the model to understand the user's question, but also requires it to generate an answer that is closely related to the question. This directly affects the user's satisfaction and the usefulness of the model.
3.RAG Landing Case Sharing
1. RAG in the area of data infrastructure
1.1 O&M Intelligence Body Background
In the data infrastructure field, there are many O&M SREs that receive a large number of alerts every day, so a lot of time is spent responding to emergencies, which leads to troubleshooting, then troubleshooting, which leads to experience. Another part of the time is spent responding to user inquiries, requiring them to use their knowledge and experience in using tools to answer questions.
Therefore, we hope to solve these problems of alarm diagnosis and answering questions by building a generalized intelligence for data infrastructure.
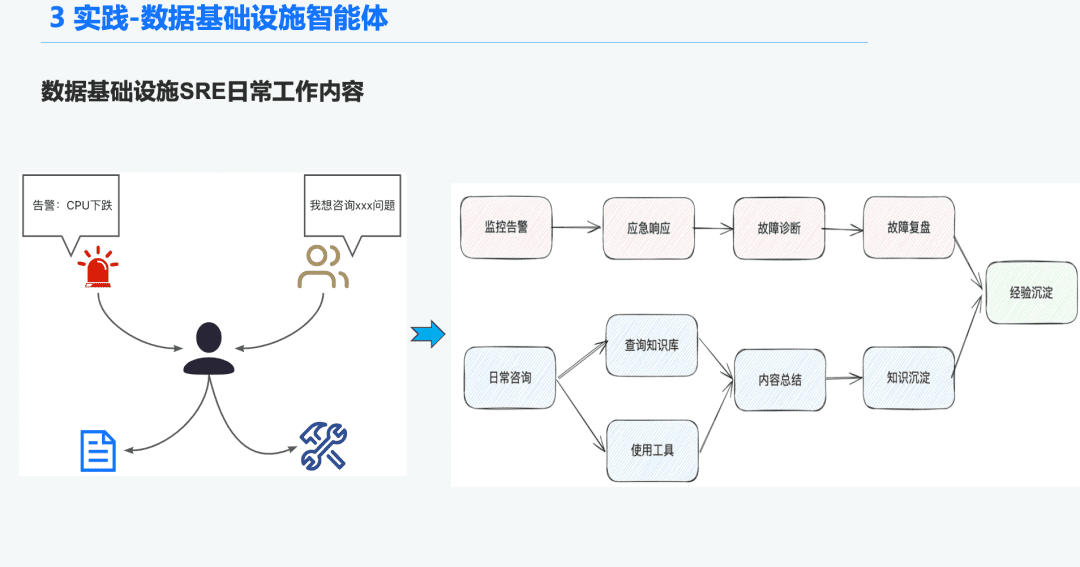
1.2 Rigorous and professional RAG
The traditional RAG + Agent technology can solve generalized, less deterministic, single-step task scenarios. However, when facing professional scenarios in the field of data infrastructure, the entire retrieval process must be deterministic, professional and realistic, and requires step-by-step reasoning.
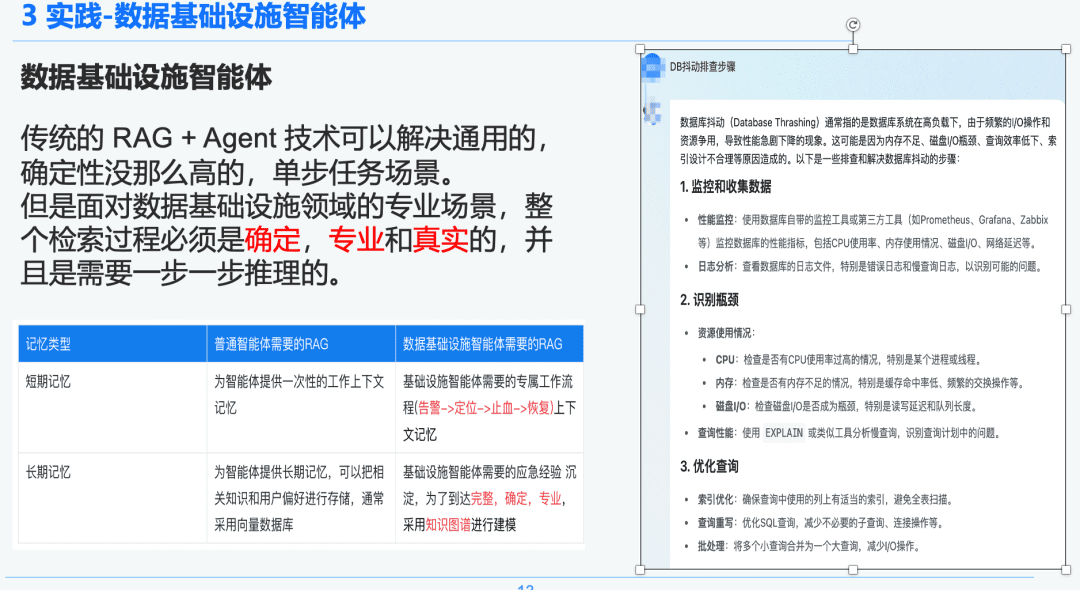
On the right is a generalized summary via NativeRAG, which may be useful information for a C-suite user who doesn't have that much domain knowledge, and then for a professional, this part of the answer won't make much sense.
We therefore compare the difference between generalized intelligences and data infrastructure intelligences over RAG:
- General-purpose intelligences: traditional RAGs do not require so much intellectual rigor and expertise, and are suitable for some business scenarios such as customer service, tourism, and platform Q&A robots.
- Data Infrastructure Intelligence Body: The RAG process is rigorous and professional, requiring an exclusive RAG workflow with contexts including (alert -> locate -> stop the bleeding -> recover) and structured extraction of Q&A and emergency response experience precipitated by experts to establish hierarchical relationships. Therefore we choose Knowledge Graph as the data bearer.
1.3 Knowledge processing
Based on the determinism and specificity of data infrastructure, we choose to use it as a knowledge bearer for diagnosing emergency response experiences by combining knowledge graphs. Our knowledge experience of emergency troubleshooting events precipitated by SRE Combined with the emergency review process, we built a DB emergency event-driven knowledge graph, we took DB jitter as an example, several events affecting DB jitter, including slow SQL problems, capacity problems, we built relationships between each emergency event.
Finally, we have established a standardized knowledge processing system of multi-source knowledge -> knowledge structured extraction -> emergency relationship extraction -> expert review -> knowledge storage step by step by standardizing the rules of emergency events.

1.4 Knowledge retrieval
In the intelligent body retrieval phase, we use GraphRAG as the bearer of static knowledge retrieval, so after recognizing the DB jitter anomaly, we find the nodes related to the DB jitter anomaly node as the basis of our analysis, as each node also retains some metadata information of each event in the knowledge extraction phase, including event name, event description, related tools, tool parameters, etc.
Therefore, we can obtain the return results through the execution lifecycle link of the execution tool to get the dynamic data to be used as the basis of emergency diagnosis for troubleshooting. Through this dynamic and static hybrid recall approach, the certainty, professionalism and rigor of the execution of the data infrastructure intelligences are guaranteed compared with the pure and simple RAG recall.
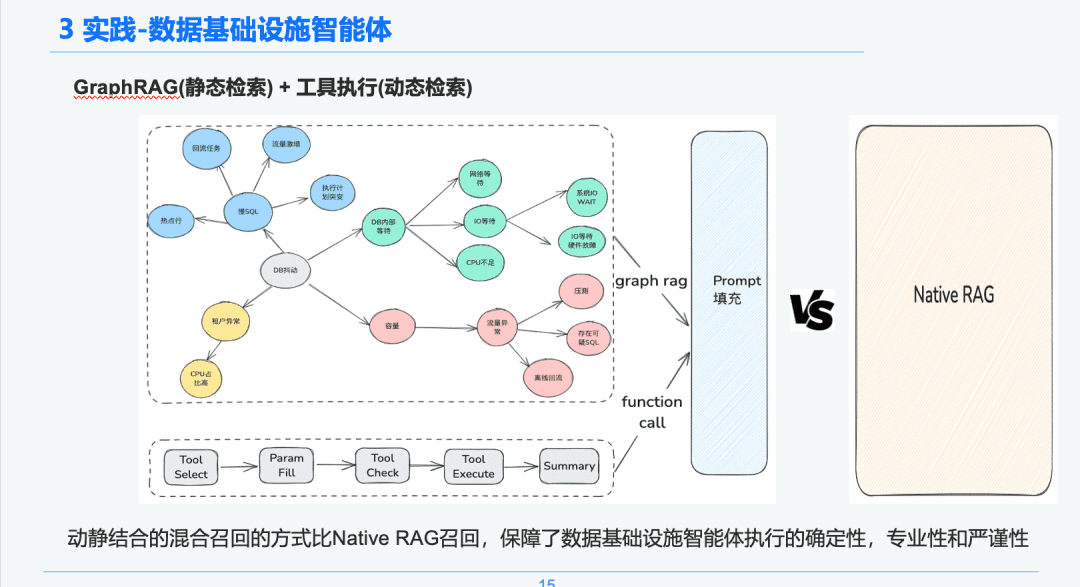
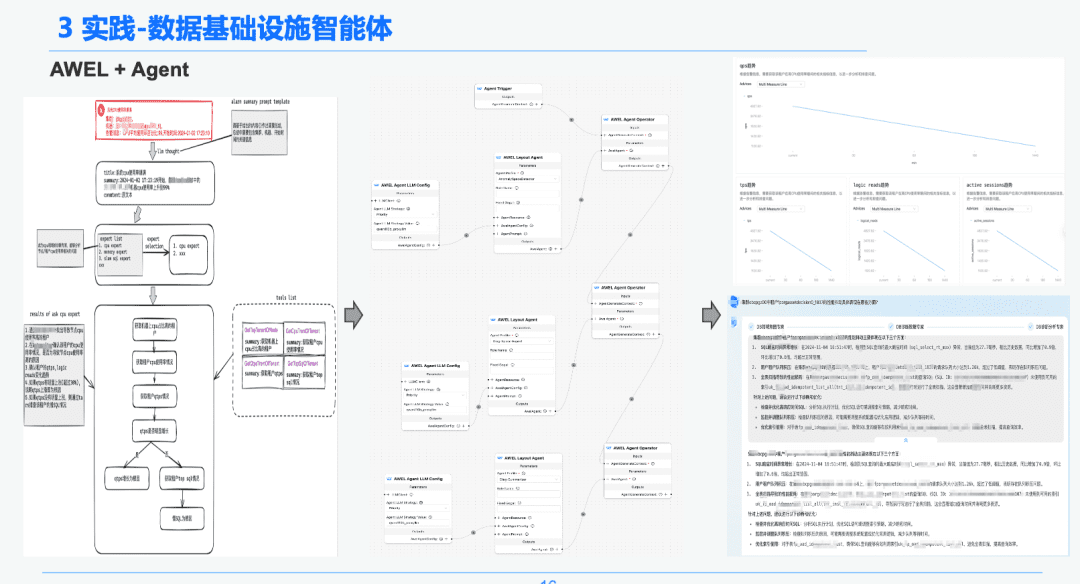
1.5 AWEL + Agent
Finally, through the community AWEL+AGENT technology, the paradigm of AGENT orchestration has been used to create from Intent Experts -> Emergency Diagnostic Experts -> Diagnostic Root Cause Analysis Experts.
Each Agent has a different function. The Intent Expert is responsible for identifying and parsing the user's intent and identifying alert messages. The Diagnostic Expert needs to locate the root cause node that needs to be analyzed through GraphRAG, as well as obtain specific root cause information. Analytics expert needs to combine the data of each root cause node + historical analysis review report to generate a diagnostic analysis report.
2. RAG in the area of financial reporting analysis
Latest Practice! How to build a financial report analysis assistant based on DB-GPT?
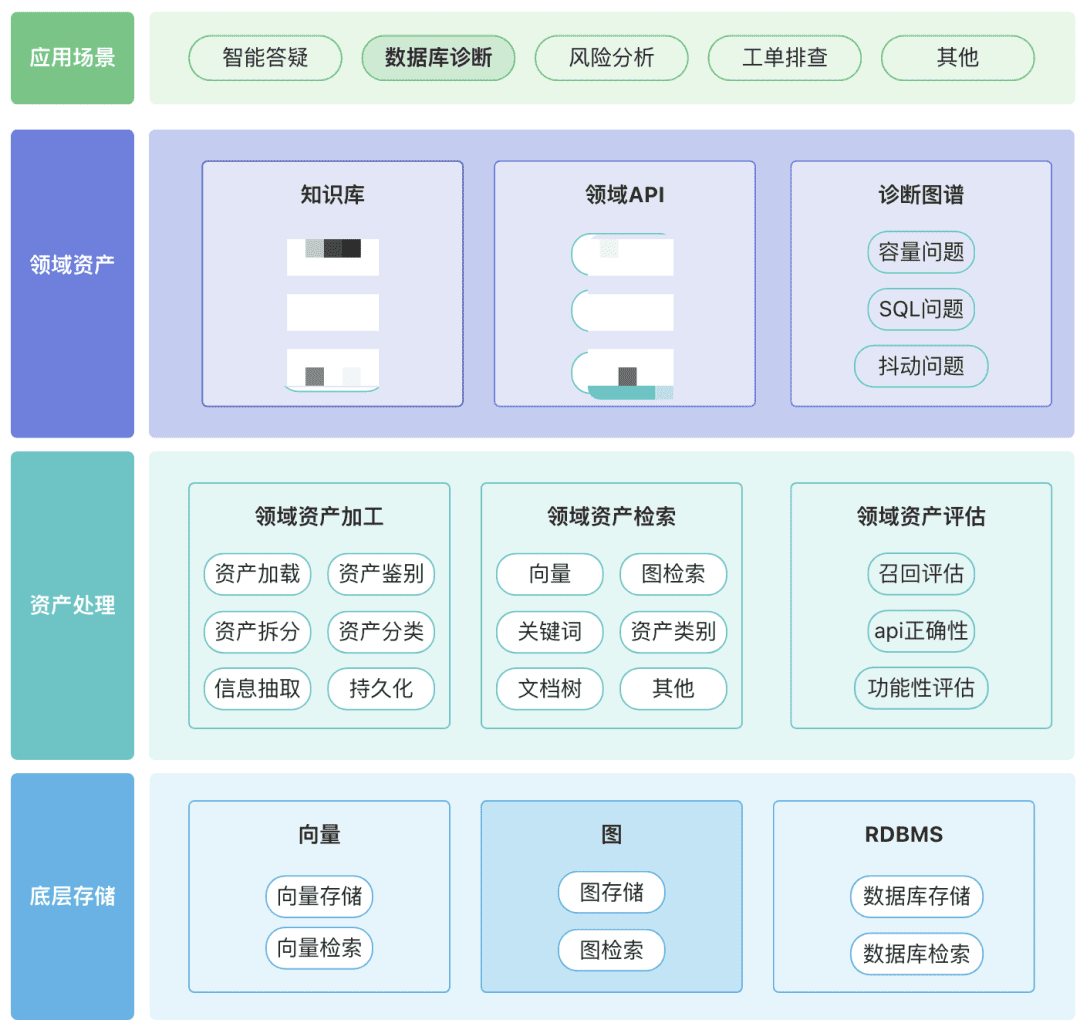
You can build your own repository of domain assets, including knowledge assets, tool assets, and knowledge graph assets, around your domain.
- Domain Assets:Domain assets include knowledge bases, APIs, and tool scripts.
- Asset processing, the entire asset data link involves domain asset processing, domain asset retrieval and domain asset evaluation.
- Unstructured -> Structured: categorized in a structured way, correctly organizing knowledge information.
- Extract richer semantic information.
- Asset Retrieval:
- Hopefully, it's a hierarchical, prioritized search rather than a single search
- Post-filtering is important, preferably through the business semantics of some rules.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...