Image generation model CogView4, announced as open source!


This image blends classical Chinese art with modern elements, inspired by the Northern Song Dynasty painter Wang Ximeng's Thousand Miles of Rivers and Mountains. The image shows a magnificent landscape scroll, with the green landscape technique resulting in rolling hills and vast rivers, rich layers of color and exquisite details. On top of this picturesque landscape, a brush character "CogView4" appears subtly, with a strong and forceful font, and the ink is in the right shade, as if it is the mark of an ancient literati who waved the brush while enjoying the beautiful scenery. The words "CogView4" complement the surrounding landscape, neither being too abrupt nor too harmonious, but rather adding a sense of dialog across time and space. The whole picture has the flavor of classical landscape, but also incorporates elements of modern technology, presenting a unique artistic tension, allowing people to appreciate the traditional aesthetics while also feeling the collision and fusion of modern creativity.
Today we officially released and open-sourced our latest image generation model, CogView4.
The model has strong complex semantic alignment and command following capabilities, supports bilingual inputs of arbitrary length, generates images of arbitrary resolution within a given range, and has strong text generation capabilities. The model is also the first image generation model open-sourced under the Apache 2.0 protocol.
I. Assessment
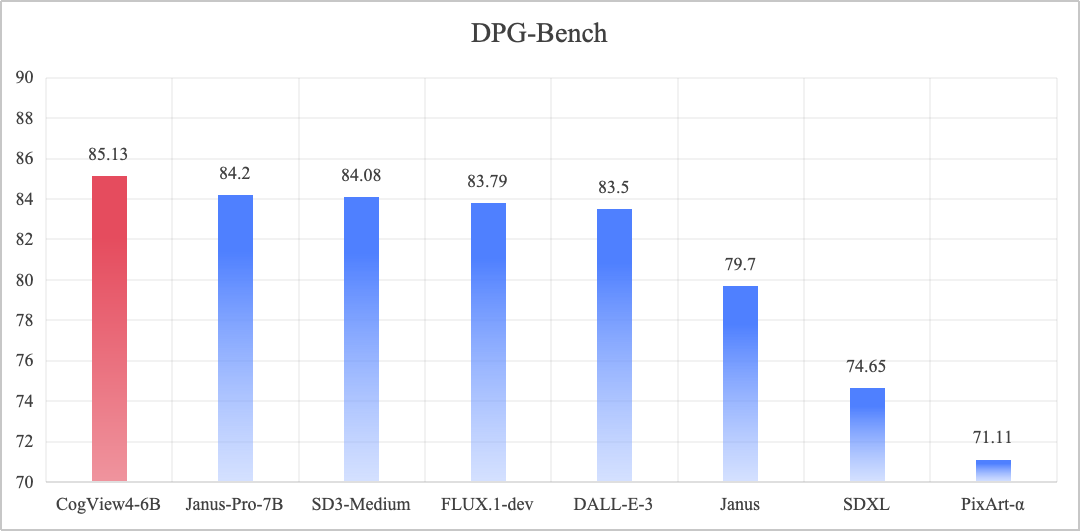
DPG-Bench (Dense Prompt Graph Benchmark) is a benchmark test for evaluating text-to-image generation models, focusing on the performance of the models in terms of complex semantic alignment and instruction following capabilities.
CogView4-6B, which has the #1 overall score in the DPG-Bench benchmarks and achieves SOTA in the open-source Vincennes diagram model.
II. Arbitrary length & arbitrary resolution
The CogView4 model implements a hybrid training paradigm of text descriptions of arbitrary length and images of arbitrary resolution.
1、Image position encoding
CogView4 uses two-dimensional rotational position encoding (2D RoPE) to model the position information of an image and supports the task of generating images with different resolutions by interpolating the position encoding.
2. Diffusion generation modeling
The model is modeled using a Flow-matching scheme for diffusion generation and combined with parametric linear dynamic noise planning to accommodate the signal-to-noise ratio requirements of different resolution images.
3、Architecture design
In terms of DiT model architecture, CogView4 continues the Share-param DiT architecture of its predecessor and designs independent adaptive LayerNorm layers for text and image modalities separately to realize efficient inter-modal adaptation.
4. Multi-stage training
CogView4 employs a multi-stage training strategy that includes base resolution training, pan-resolution training, high-quality data fine-tuning, and human preference alignment training. This staged training approach not only covers a wide range of image distributions, but also ensures that the generated images are highly aesthetically pleasing and aligned with human preferences.
5. Training framework optimization
From a textual perspective, CogView4 breaks through the limitation of the traditional fixed token length, allows higher token upper bounds, and significantly reduces textual token redundancy during training. When the average length of the training caption is in the range of 200-300 tokens, CogView4 reduces the token redundancy by about 50% compared to the traditional scheme with fixed 512 tokens, and achieves an efficiency improvement of 5%-30% in the progressive training phase of the model.
From an image perspective, mixed-resolution training enables the model to support arbitrary resolution generation over a wide range, greatly enhancing creative freedom. The target resolution only needs to fulfill the following conditions:
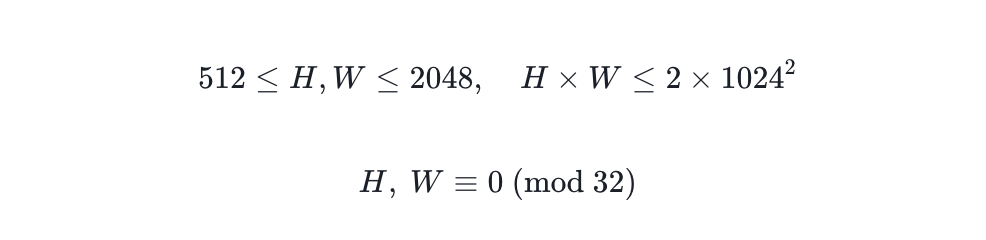
Both of these can greatly increase creative freedom.
Example: Extra-long story (four-panel comic)

Princess: a human female, beautiful and elegant, dressed in a gorgeous princess costume, imprisoned in a monster's lair.
King: Human male, majestic and benevolent, dressed in ornate kingly garb and seated on the throne of the kingdom.
Flame Dragon: a monster, covered in flame-like scales, spitting flames, and huge in size.
Dark Lord: Monster, huge in size, covered in darkness, possessing great magical power.
Scene 1: Xiaoming embarks on a journey
Create an anime-style scene with a magnificent kingdom courtyard in the background. The main character in the scene is Kotomine (a human boy with a brave heart, holding a sword and wearing a simple warrior costume), who is shown in a pose embarking on a journey. Includes details of the flowers in the courtyard and the castle in the distance, with the light of the morning sun conveying bravery and determination. Quality: masterpiece, best quality, super detailed, 4k
Scene 2: Ming defeats the Flame Dragon
Create an anime style scene with a fiery crater in the background. The main character in the scene is Kotomine (a human boy with a brave heart, holding a sword and wearing a simple warrior costume), who is in the moment of victory over a flaming dragon. Includes details of the rocks and lava in the crater, and the fiery red lighting conveys fierceness and courage. Quality: masterpiece, best quality, super detailed, 4k
Scene 3: Ming's Battle with the Dark Lord
Create an anime-style scene with a shadowy monster lair in the background. The main character in the scene is Ming (a human boy with a brave heart, sword in hand, and a simple warrior costume), who is in the middle of a fierce battle with the Dark Lord. Includes details of the darkness and magical energy of the lair, and the somber lighting conveys intensity and tension. Quality: masterpiece, best quality, super detailed, 4k
Scene 4: Ming Rescues the Princess
Create an anime-style scene with the interior of a deserted castle in the background. The main characters in the scene are Ming (a human boy with a brave heart, holding a sword and wearing a simple warrior's costume) and the Princess (a human woman, beautiful and elegant, wearing a gorgeous princess' costume), who are in the heartwarming scene of Ming rescuing the Princess. Includes details of the castle's interior ruins and dim lighting, and the gentle lighting conveys touching and redemption. Quality: masterpiece, best quality, super detailed, 4k
C. Support for Chinese and English
In terms of technical implementation, CogView4 switches the text encoder from the English-only T5 encoder to the bilingual GLM-4 encoder, and is trained with bilingual graphic pairs, so that the CogView4 model has the ability of inputting bilingual prompt words.
So far, CogView4 is the first open-source text-generated graphical model that supports bilingual cue word input, and is especially good at understanding and following Chinese cue words and generating Chinese characters in the screen. These two features are more suitable for a wide range of creative needs in domestic advertising, short videos and other fields.

IV. Apache protocol
CogView4-6B model supports Apache2.0 protocol, and will subsequently add ControlNet, ComfyUI and other eco-support, a full set of fine-tuning toolkit will soon be available.
Model Warehouse:
https://huggingface.co/THUDM/CogView4-6B
https://modelscope.cn/models/ZhipuAI/CogView4-6B
updated CogView4 The model will go live on March 13 at chatglm.cn.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...