What is Transformer?


Transformer is a deep learning modeling architecture for Natural Language Processing (NLP), proposed by Vaswani et al. in 2017. It is mainly used for processing sequence-to-sequence tasks such as machine translation, text generation etc.
Simply put, the principle of the Transformer model for text generation is - "Predict the next word".
Given a text (prompt) by the user, the model predicts what the next word is most likely to be. The core innovation and power of Transformers is their use of the self-attention mechanism, which allows them to process entire sequences and capture long-distance dependencies more efficiently than previous architectures (RNNs).
Also of note, huggingface/transformers on GitHub is a repository of HuggingFace's implementation of the Transformer, including the Transformer implementation and a large number of pre-trained models.
Current LLMs are basically based on the Transformer architecture with improved optimization techniques and training methods.
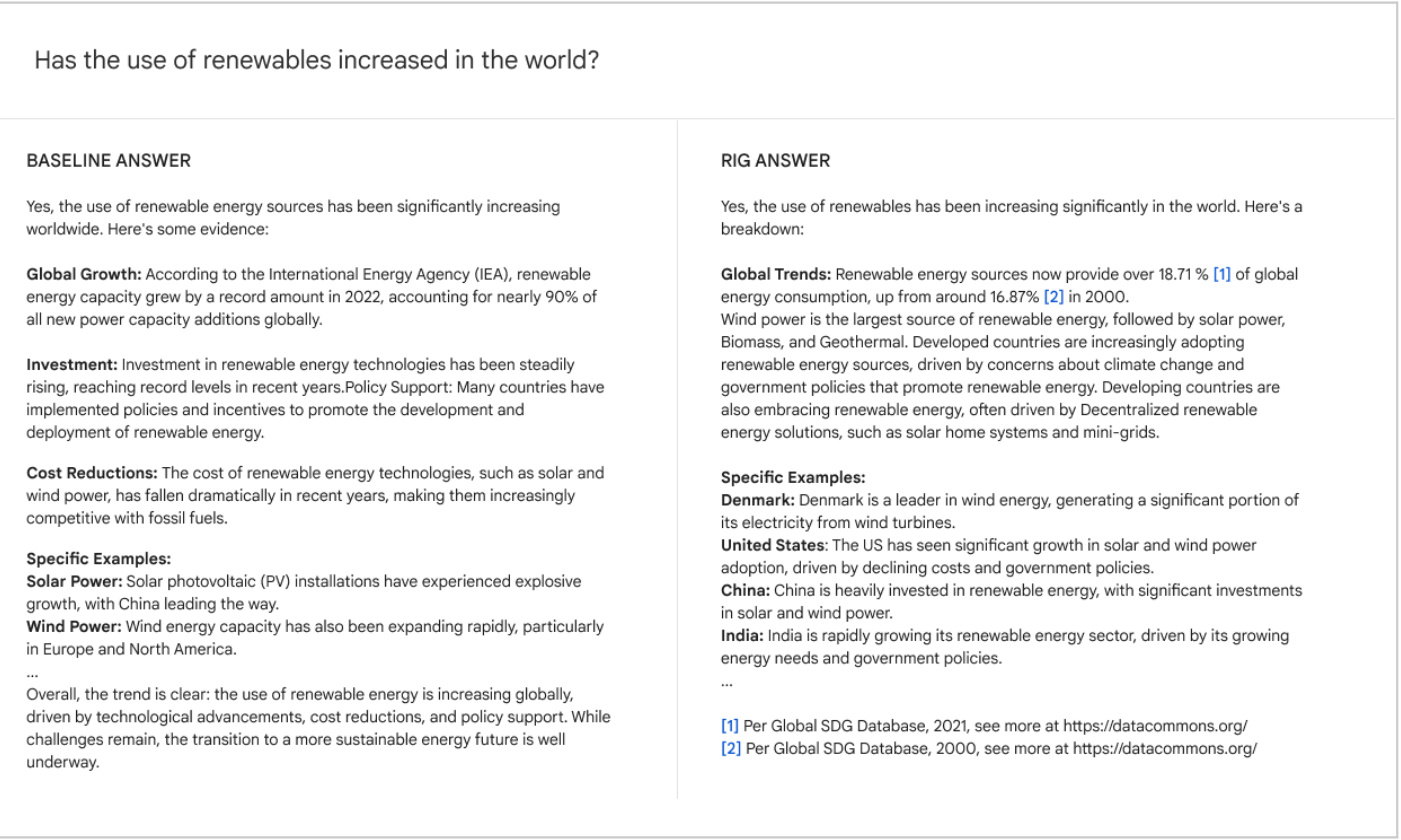
Structure of Transformer
Each Text Generation Transformer consists of three key components:
Embedding layer (Embedding) ::
- The text input is split into smaller units called tokens, which can be words or sub-words.
- These lexical elements are converted into numerical vectors called embeddings.
- These embedding vectors capture the semantic meaning of words
Transformer block ::
This is the basic building block for the model to process and transform the input data. Each block consists of:
- Attention Mechanism ::
- Core components of the Transformer block
- Allow lexical elements to communicate with each other
- Capturing contextual information and relationships between words
- Multilayer Perceptron (MLP) Layer ::
- A feed-forward network, processing each lexical element independently
- The goal of the attentional layer is to route information between lexical elements
- The goal of MLP is to optimize the representation of each lexical element
Output Probabilities ::
- Final linear and softmax layers
- Converting processed embeddings to probabilities
- Enables the model to predict the next lexical element in the sequence
Benefits of Transformer:
- parallelization The Transformer is a RNN, which can be trained in parallel using GPUs to improve the training speed because the Transformer does not need to process the data sequentially.
- long-distance dependence : The self-attention mechanism allows the Transformer to efficiently capture long-range dependencies in sequences.
- dexterity : Transformer can be easily extended to larger models (e.g., BERT, GPT, etc.) and performs well in a variety of NLP tasks.
Disadvantages of Transformer:
- High computational complexity The computational complexity of the self-attention mechanism is O(n^2), which consumes more computational resources when the length of the input sequence is long.
- High demand for data : Transformers usually require a large amount of data for training in order to maximize their performance.
- Lack of intrinsic sequence information : Since there is no built-in sequence processing mechanism (e.g., time-steps in RNNs), additional mechanisms (e.g., position encoding) are needed to introduce sequence information.
Refs
The first of these two references is to the classic paper on transformers, Attention Is All You Need. It was this paper that first proposed the transformer.
The second is a visualization of the transformer, which allows you to see the internal structure of the transformer.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...