
Tongyi Wanxiang video upgrade, topped VBench, video support for generating Chinese, lens texture pull full

2025 is just getting started, and AI video generation is about to have a technological breakthrough?
This morning, Ali's Tongyi Wanphase video generation model announced a heavy upgrade to version 2.1.
There are two versions of the newly released model, which areTongyi ManPhase 2.1 Extreme and Professional, the former focusing on efficient performance, the latter aiming at excellent expressivenessThe
According to the introduction, Tongyi Wanxiang has comprehensively upgraded the overall performance of the model this time, especially in processing complex movements, restoring the real physical laws, improving the movie texture and optimizing the instructions to follow, which opens a new door for AI's artistic creation.
Let's have a glimpse of the video generation effect and see if it can amaze you.
Take the classic "cut steak" as an example, you can see that the texture of the steak is clearly visible, the surface is covered with a thin layer of grease, shimmering and shiny, the blade cuts slowly along the muscle fibers, the meat Q elasticity, the details of the pull full. 
Prompt: In a restaurant, a man is cutting a steak that is steaming hot. In a close-up overhead shot, the man holds a sharp knife in his right hand, places the knife on the steak, and cuts along the center of the steak. The person is dressed in black with white nail polish on his hands, the background is bokeh, there is a white plate with yellow food and a brown table.
And then look at a character close-up generation effect, the little girl's facial expression, hand and body movements are natural and coordinated, the wind swept through the hair is also in line with the laws of motion.

Prompt:Cute young girl standing in a flower bush with her hands comparing to her heart and all kinds of little hearts dancing around her. She is wearing a pink dress, her long hair is blowing in the wind, and her smile is sweet. The background is a spring garden with flowers in full bloom and bright sunshine. HD realistic photography, close up close-up, soft natural light.
Is the model strong enough to run another score. Currently, on VBench Leaderboard, the definitive video generation review list, theThe upgraded Tongyi Wanxiang has reached the top of the list with a total score of 84.7%, surpassing domestic and international video generation models such as Gen3, Pika and CausVid... It looks like the competitive landscape of video generation has seen another wave of change.
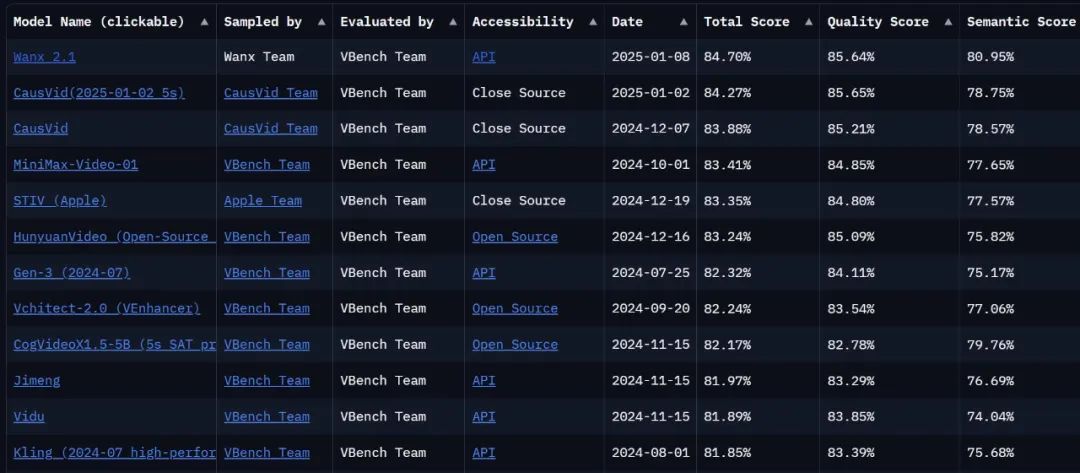
Link to the list: https://huggingface.co/spaces/Vchitect/VBench_Leaderboard
From now on, users will be able to use the latest generation of models on the Tongyi Wanxiang website. Similarly, developers can also call the big model API in AliCloud Bai Lian.
Official website address: https://tongyi.aliyun.com/wanxiang/
first-hand experienceIncreased expressiveness and the ability to play with special effects fonts
In recent times, there has been a rapid iteration of large models for video generation, has the new version of Tongyi Wanxiang achieved a generation level of improvement? We did some real-world testing.
AI video can now write.
First, AI-generated videos can finally say goodbye to 'ghosting'.
Previously, the mainstream AI video generation model on the market has been unable to accurately generate Chinese and English, as long as the place where the text should be, it is a pile of illegible garbage. Now this industry problem has been solved by Tongyi Wanxiang 2.1.
It becameThe first video generation model that supports Chinese text generation and both English and Chinese text effects.The
Users can now generate text and animations with cinematic effects by simply entering a short text description.
For example, a kitten is typing in front of a computer, and seven big words "Work or Eat" pop up on the screen.

In the video generated by Tongyi Wanxiang, the cat sits at the workstation and plays the keyboard and presses the mouse in a serious manner, looking like a contemporary laborer, and the pop-up subtitles, coupled with the auto-generated soundtrack, give the whole picture a more witty feel.
Then there's the English word 'Synced' that pops out of a little orange square box.

Whether it's generating Chinese or English, Tongyi Wanxiang gets it right, with no typos or "ghost writing".
Not only that, but it also supports the application of fonts in a variety of scenarios, theIncluding special effects fonts, poster fonts, and fonts displayed in real scenarios.The
For example, near the Eiffel Tower on the banks of the Seine River, brilliant fireworks blossom in the air, and as the camera closes in, the pink number "2025" gradually grows larger until it fills the entire frame.

No more "ghosting" of large movements
Complex character movement was once a "nightmare" for AI video generation models, and in the past, AI-generated videos would either have hands and feet flying around, change into a living person, or have weird movements that "only turn around but not the head". 
And through advanced algorithm optimization and data training, Tongyi Wanxiang is able to achieve stable and complex motion generation in a variety of scenarios, especially in terms of large-scale limb movement and precise limb rotation, and the breakdancing generated in the picture above is very silky smooth.
Then again, in the generated video below, the man's movements are smooth and natural as he runs, with no problems of left or right legs being indistinguishable or twisted out of shape. And it also pays close attention to detail, as the man leaves imprints every time his toes touch the ground and slightly raises the fine sand.

Prompt: a handsome young man runs along the beach as the golden sunlight pours over the shimmering sea at sunset, stabilizing the tracking shot.
The camera is like a master of the cinema.
The great director Spielberg once said that the secret of a good movie lies in the language of the camera. In order to shoot shocking movie footage, cinematographers are eager to go up and down the sky and fly over the walls. 
But in this age of AI, it's a lot easier to 'make' a movie.
All we need to do is enter a simple text command, such as lens left, lens farther, lens advance, etc., and Tongyi Wanxiang will be able toAutomatically outputs a reasonable video according to the main content of the video and the needs of the camera.The
We enter Prompt: a rock band playing on a front lawn, and as the camera advances, it focuses on the guitarist, who is wearing a leather jacket and has long, messy hair that swings to the beat. The guitarist's fingers jump rapidly across the strings as the rest of the band members in the background give it their all.

a complete picture of everything 2.1 Instructions were strictly followed. The video begins with the guitarist and drummer playing passionately, and as the camera slowly draws in closer, the background blurs and zooms out, highlighting the guitarist's demeanor and hand movements.
Long text commands don't get lost
For AI-generated videos to be stunning, precise text prompts are essential.
However, sometimes the big model has a limited memory, and when faced with textual commands containing various scene switches, character interactions, and complex actions, it tends to lose track of the details or get confused about the logical order.
The new Tongyi Manxiang is a big step forward in terms of long text instructions to follow.
Prompt: A motorcycle rider speeds along a narrow city street at breakneck speeds, avoiding a massive explosion in a nearby building, as flames roar violently, casting a bright orange glow, and debris and shards of metal fly through the air, adding to the chaos at the scene. The rider, dressed in dark gear, bent over and gripping the handlebars tightly, looked focused as he lurched forward at breakneck speed, undeterred by the fire raging behind him. Thick black smoke from the explosion fills the air, shrouding the background in apocalyptic chaos. However, the rider remains relentless, weaving through the chaos with precision, extremely cinematic, ultra-fine detail, immersive, 3D, and coherent action.

In this lengthy textual description above, the narrow streets, bright flames, filling black smoke, flying debris, and riders in dark colored gear ...... are all details captured by Tongyi Manxiang.
Tongyi Wanxiang also has a more powerful concept combination capability, which allows it to accurately understand a variety of different ideas, elements or styles and combine them to create entirely new video content.
The image of an old man in a suit breaking out of an egg and staring wide-eyed at the camera's white-haired old man is quite hilarious, coupled with the sound of a rooster clucking.

Specializing in cartoon oil paintings and other styles
The new version of Tongyi Wanxiang also generates movie-quality video images and has good support for various art styles, such as cartoon, movie color, 3D style, oil painting, classical style, and so on.
Check out this cute little 3D animated monster standing on a grapevine and dancing around.

Prompt: a fluffy, happy little green titi monster stands on a vine branch and sings happily, rotate the camera counterclockwise.
In addition, it supports different aspect ratios, including 1:1, 3:4, 4:3, 16:9 and 9:16, which can be better adapted to different end devices such as TVs, computers and cell phones. 
From the above performance, we can already do some creative work using the Tongyi Manxiang to transform inspiration into 'reality'.
Of course this series of advances can be attributed to AliCloud's upgrades in the basic model of video generation.
Base model significantly optimizedStructure, training and evaluation of all aspects of the "transformation"
On September 19th last year, AliCloud released the Tongyi Wanphase video generation model at the Yunqi Conference, bringing the ability to generate film and TV-grade HD videos. As a fully self-developed visual generation big model of AliCloud, it adopts Diffusion + Transformer The architecture supports image and video generation class tasks, and provides industry-leading visual generation capabilities with many innovations in model frameworks, training data, labeling methods, and product design.
In this upgraded model, the Tongyi Wanxiang team (hereinafter referred to as the team) furtherSelf-developed efficient VAE and DiT architectures, enhanced for modeling spatio-temporal contextual relationships, significantly optimizing the generation.
Flow Matching is an emerging framework for generative model training in recent years, which is simpler to train, achieves comparable or even better quality than diffusion models through Continuous Normalizing Flow, and has faster inference speeds, and is gradually being applied to the field of video generation. For example, Meta's previously released video model Movie Gen uses Flow Matching.
For the selection of training methods, Tongyi Wanxiang 2.1 utilized theFlow Matching Scheme Based on Linear Noise Trajectories, and has been deeply designed for the framework, resulting in improved model convergence, generation quality, and efficiency.

Tongyi Wanxiang 2.1 Video Generation Architecture Diagram
For video VAE, the team designed an innovative video codec scheme by combining caching mechanism and causal convolution.. Among them, the caching mechanism can maintain the necessary information in video processing, thus reducing the repeated computation and improving the computational efficiency; causal convolution can capture the temporal features of the video and adapt to the progressive changes of the video content.
Instead of the direct E2E decoding process for long videos, the implementation replaces the direct E2E decoding process for long videos by splitting the video into chunks and caching the intermediate features so that the graphics card usage is only related to the Chunk size regardless of the original video length, allowing the model to efficiently encode and decode unlimited lengths of 1080P video. The team says this key technology provides a viable path for training videos of arbitrary length.
The following figure shows the comparison of the results of different VAE models. In terms of the model computational efficiency (frame/delay) and video compression reconstruction (Peak Signal to Noise Ratio, PSNR) metrics, the VAE used by Tongyi Wanxiang still achieves the following results despite its non-optimal parametersIndustry-leading video compression and reconstruction qualityThe
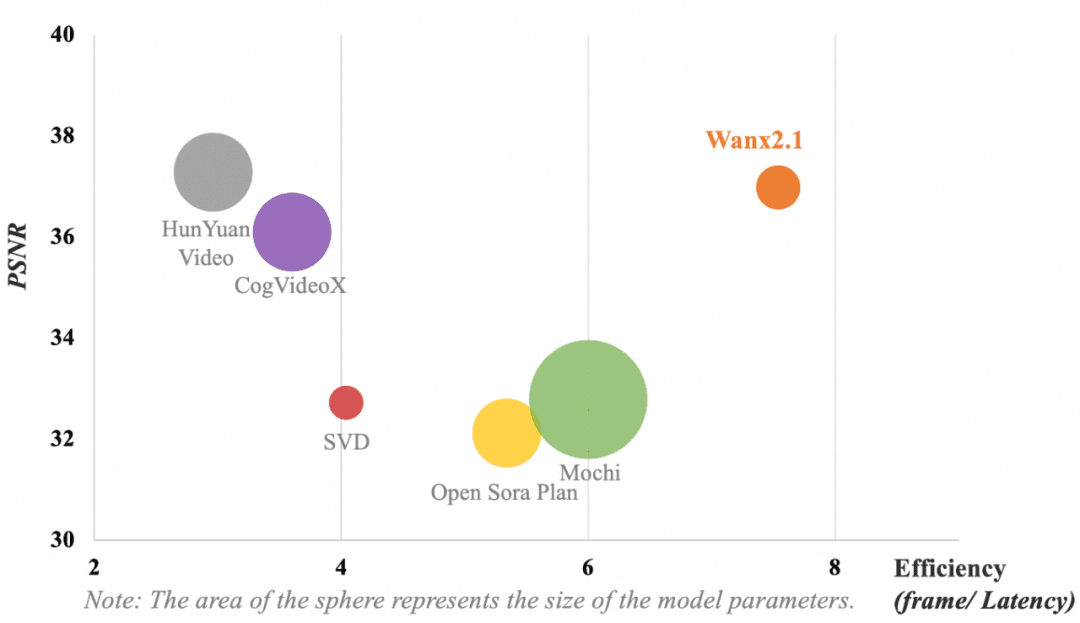
Note: The circle area represents the model parameter size.
The team's core design goal on DiT (Diffusion Transformer) was to achieve robust spatio-temporal modeling capabilities while maintaining an efficient training process. Doing this required some innovative changes.
First, in order to improve the modeling capability of spatio-temporal relations, the team adopted the spatio-temporal full-attention mechanism, which enables the model to more accurately simulate the complex dynamics of the real world. Second, the introduction of the parameter sharing mechanism effectively reduces the training cost while improving the performance. In addition, the team optimized the performance for text embedding by using the cross-attention mechanism to embed text features, which both achieves better text controllability and reduces computational requirements.
Thanks to these improvements and attempts, the DiT structure of the generalized universal phase achieves more obvious convergence superiority at the same computational cost.
In addition to innovations in model architecture, the teamSome optimizations have been made in the areas of ultra-long sequence training and inference, data construction pipeline and model evaluation as well, allowing the model to efficiently handle complex generative tasks with enhanced efficiency advantages.
How to train efficiently with millions of ultra-long sequences
When dealing with ultra-long visual sequences, large models often face challenges at multiple levels, such as computation, memory, training stability, inference latency, and thus efficient coping schemes.
To this end, the team combined the characteristics of the new model workload and the hardware performance of the training cluster to develop a distributed, memory-optimized training strategy to optimize the training performance under the premise of guaranteeing the model iteration time, and eventuallyAchieved industry-leading MFU and efficient training of 1 million ultra-long sequencesThe
On the one hand, the team innovates the distributed strategy by adopting 4D parallel training with DP, FSDP, RingAttention, and Ulysses, which enhances both training performance and distributed scalability. On the other hand, in order to achieve memory optimization, the team adopts a hierarchical memory optimization strategy to optimize the Activation memory and solve the memory fragmentation problem based on the computation and communication volume caused by sequence length.
In addition, computational optimization can improve the efficiency of model training and save resources. For this reason, the team adopts FlashAttention3 for spatio-temporal full-attention computation, and chooses the appropriate CP strategy for slicing by taking into account the computational performance of the training clusters in different sizes. At the same time, the team removes computational redundancy for some key modules, and reduces access overhead and improves computational efficiency through efficient Kernel implementation. In terms of file system, the team makes full use of the read/write characteristics of the high-performance file system in AliCloud's training cluster, and improves read/write performance by slicing Save/Load.

4D Parallel Distributed Training Strategy
At the same time, the team chose a staggered memory usage scheme to address the OOM problems caused by Dataloader Prefetch, CPU Offloading, and Save Checkpoint during training. Moreover, to ensure the stability of training, the team leveraged the intelligent scheduling, slow-machine detection, and self-healing capabilities of AliCloud's training clusters to automatically identify faulty nodes and restart tasks quickly.
Introducing automation in data construction and model evaluation
Training of large models for video generation cannot be done without high quality data at scale and effective model evaluationThe former ensures that the model learns diverse scenarios, complex spatio-temporal dependencies and improves generalization ability, constituting the cornerstone of model training; the latter helps to supervise the model performance so that it better achieves the expected results, and becomes the wind vane of model training.
In terms of data construction, the team has built an automated data construction pipeline with high quality as the criterion, which is highly aligned with the human preference distribution in terms of visual quality and motion quality, so that high-quality video data can be automatically constructed with high diversity, balanced distribution, and other characteristics.
For model evaluation, the team similarly designed a comprehensive set of automated metrics, incorporating more than two dozen dimensions such as aesthetic scoring, motion analysis, and command adherence, and targeted and trained professional scorers capable of aligning to human preferences. With effective feedback from these metrics, the model iteration and optimization process was significantly accelerated.
It can be said that the synergistic innovations in several aspects, such as architecture, training and evaluation, have enabled the upgraded Tongyi Wanphase video generation model to reap significant generational improvements in real-world experience.
GPT-3 moments for video generationHow much longer?
Since last February, OpenAI's Sora Since its introduction, video generation modeling has become the most competitive field in the tech world. From domestic to overseas, startups to tech giants are launching their own video generation tools. However, compared to the generation of text, AI video is more than one level of difficulty in order to achieve the degree of people's acceptance.
If, as OpenAI CEO Sam Altman says, Sora represents the GPT-1 moment in the grand model of video generation, then we can build on that to realize the precise control of textual commands and the ability to adjust angles and camera positions to ensure character consistency. If we build on this foundation to realize the precise control of text commands to AI, adjustable angles and camera positions, ensure the consistency of characters, and other video generation capabilities, plus the unique AI features such as rapid change of style and scene, we may be able to usher in the new "GPT-3 moment" very soon.
From the perspective of the path of technological development, video generation modeling is a process of verifying Scaling Laws. As the ability of the basic model improves, AI will understand more and more human commands and be able to create more and more realistic and reasonable environments.
From a practical point of view, we actually can't wait: since last year, people in the short video, animation, and even film and television industries have begun to utilize video generation AI for creative exploration. If we can break through the limitations of reality and do previously unimaginable things with video generation AI, a new round of industry change is just around the corner.
Now it seems that Tongyi Manxiang has taken the first step.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles




No comments...