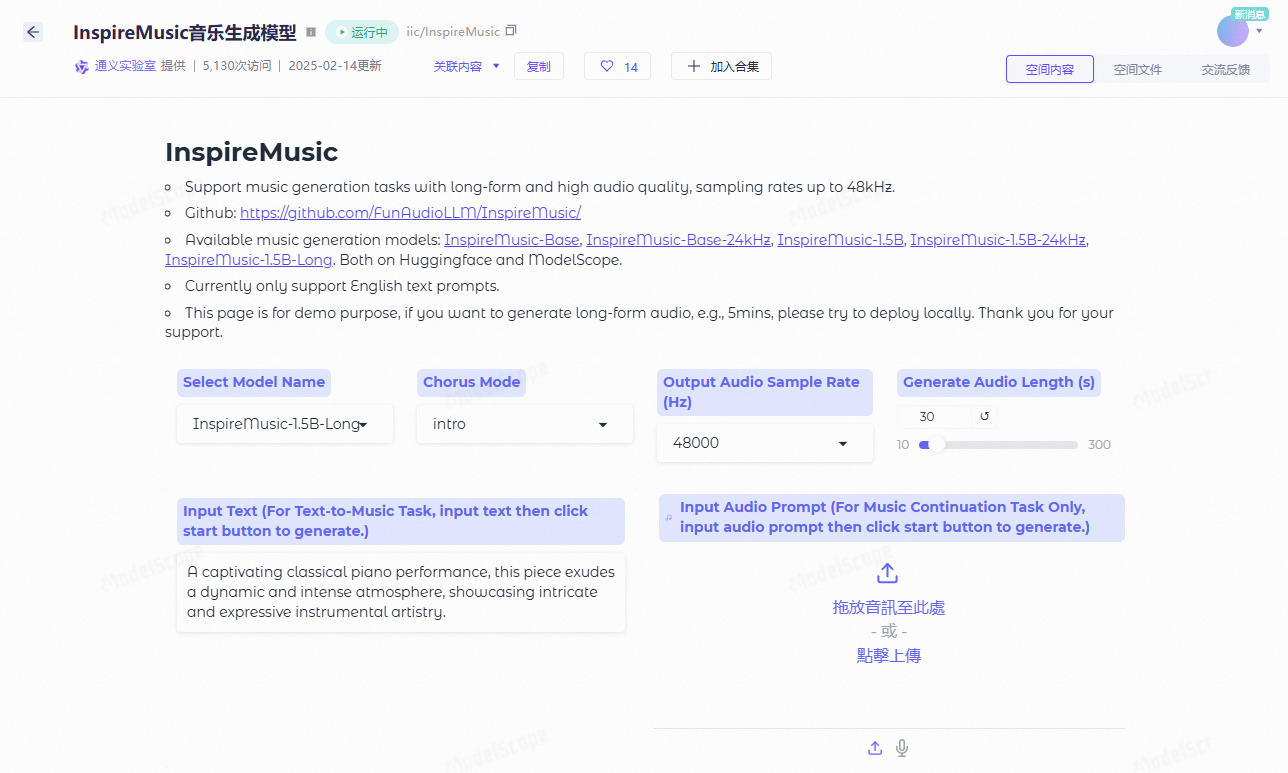
TangoFlux: Fast text-to-dub conversion tool that generates 30 seconds of audio in 3 seconds!

General Introduction
TangoFlux is an efficient text-to-audio (TTA) generation model developed by DeCLaRe Lab. The model is capable of generating up to 30 seconds of 44.1kHz stereo audio in as little as 3.7 seconds.TangoFlux uses stream matching and Clap-Ranked Preference Optimization (CRPO) techniques to enhance TTA alignment by generating and optimizing preference data. The model performs well in both objective and subjective benchmarks, and all code and models are open source to support further TTA generation research.

Experience: https://huggingface.co/spaces/declare-lab/TangoFlux
Singapore University of Technology and Design (SUTD) and NVIDIA have jointly announced TangoFlux, a highly efficient text-to-audio generation (TTA) model with approximately 115 million parameters that can generate up to 44.1kHz audio in just 3.7 seconds on a single A40 GPU. With approximately 515 million parameters, the model is capable of generating up to 30 seconds of 44.1kHz audio in just 3.7 seconds on a single A40 GPU. TangoFlux not only has ultra-fast generation speed, but also has better audio quality than open source audio models such as Stable Audio.
Compare TANGoFLux with other state-of-the-art open-source text-to-audio generation models: not only does TANGoFLux generate roughly 2x faster than the fastest models, but it also achieves better audio quality (as measured by CLAP and FD scores), all of this with fewer trainable parameters.

TangoFlux, titled "Ultra-Fast, Faithful Text-to-Audio Generation via Stream Matching and Clap-Ranked Preference Optimization," consists of FluxTransformer blocks, which are Diffusion Transformers (DiTs) and Multi-Modal Diffusion Transformers (MMDiTs) that condition on text cues and duration embeddings to generate up to 30 seconds of 44.1kHz audio. These are the Diffusion Transformer (DiT) and Multimodal Diffusion Transformer (MMDiT), which are conditioned on textual cues and duration embeddings in order to generate 44.1kHz audio of up to 30 seconds in length.TangoFlux learns rectified streaming trajectories of the latent representations of the audio encoded by the Variable Auto-Encoder (VAE).The TangoFlux training pipeline consists of three phases: pre-training, fine-tuning, and optimization of the preferences using the CRPO. Specifically, CRPO iteratively generates new synthetic data and constructs preference pairs for preference optimization using DPO losses for stream matching.

Function List
- Fast Audio Generation: Generate up to 30 seconds of high-quality audio in 3.7 seconds.
- Stream Matching Technology: Audio generation using FluxTransformer and Multimodal Diffusion Transformers.
- CRPO Optimization: Improve audio generation quality by generating and optimizing preference data.
- Multi-stage training: It consists of three phases: pre-training, fine-tuning and preference optimization.
- open source: All code and models are open-sourced to support further research.
Using Help
Installation process
- Environment Configuration: Ensure that Python 3.7 and above is installed and that the necessary dependency libraries are installed.
- clone warehouse: Run in a terminal
git clone https://github.com/declare-lab/TangoFlux.gitCloning Warehouse. - Installation of dependencies: Go to the project directory and run
pip install -r requirements.txtInstall all dependencies.
Usage Process
- model training::
- Configuration Accelerator: Run
accelerate configand follow the prompts to configure the runtime environment. - Configure the training file path: in the
configs/tangoflux_config.yamlSpecify the training file path and model hyperparameters in the - Run the training script: Use the following command to start the training:
CUDA_VISIBLE_DEVICES=0,1 accelerate launch --config_file='configs/accelerator_config.yaml' src/train.py --checkpointing_steps="best" --save_every=5 --config='configs/tangoflux_config.yaml'- DPO training: modify the training file to include the "chosen", "reject", "caption" and "duration" fields and run the following command:
CUDA_VISIBLE_DEVICES=0,1 accelerate launch --config_file='configs/accelerator_config.yaml' src/train_dpo.py --checkpointing_steps="best" --save_every=5 --config='configs/tangoflux_config.yaml' - Configuration Accelerator: Run
- model-based reasoning::
- Download Model: Make sure you have downloaded the TangoFlux model.
- Generate Audio: Use the following code to generate audio from a text prompt:
import torchaudio from tangoflux import TangoFluxInference from IPython.display import Audio model = TangoFluxInference(name='declare-lab/TangoFlux') audio = model.generate("生成音频的文本提示", duration=10) Audio(audio, rate=44100)
Detailed Function Operation
- Text-to-audio generation: Enter a text prompt, set the duration of the generated audio (1 to 30 seconds), and the model will generate the corresponding high-quality audio.
- bias optimization: With CRPO technology, the model is able to generate audio that is more in line with the user's preferences.
- Multi-stage training: It consists of three phases: pre-training, fine-tuning and preference optimization to ensure the quality and consistency of the audio generated by the model.
caveat
- hardware requirement: It is recommended to use a GPU with higher computational power (e.g. A40) for optimal performance.
- Data preparation: Ensure diversity and quality of training data to improve model generation.
With these steps, users can quickly get started with TangoFlux for high-quality text-to-audio conversion. Detailed installation and usage instructions ensure that users can successfully complete the model training and inference process.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts

No comments...