SuperCLUE Review: DeepSeek-R1 Third-Party Platform Stability Crossover, Pick the Right Platform, Performance Soars!

DeepSeek-R1 Stability Evaluation Report on Third-Party Platforms
The rapid development of artificial intelligence has given rise to a number of outstanding inference models. deepSeek-R1 has quickly become the center of attention in the industry due to its outstanding performance and ability to handle complex tasks. However, with the proliferation of users and the increase of external cyber-attacks, the stability problem of DeepSeek-R1 has been gradually exposed. To address this challenge, several third-party platforms have launched their own solutions for the DeepSeek-R1 Model optimization services, and strive to provide users with a more stable and efficient use of the experience.
In order to help users fully understand the service quality of different platforms and make an informed choice based on their needs, the organization has conducted a survey on a number of third-party platforms that support DeepSeek-R1.Stability EvaluationThis evaluation was conducted on 12 representative third-party platforms. In this evaluation, 12 representative third-party platforms were selected, and 20 original elementary school oracle reasoning questions were designed to examine the actual performance of DeepSeek-R1 model on each platform. The evaluation dimensions cover key indicators such as response rate, reasoning time and accuracy. This report aims to present the first evaluation results of the web-based platforms, reflecting the stability level of each platform at the point of release. In the future, the organization will continue to follow up and conduct more comprehensive evaluations on various platforms, including web-based, API, APP and even locally deployed versions.
Summary of DeepSeek-R1 Stability Evaluation Experience
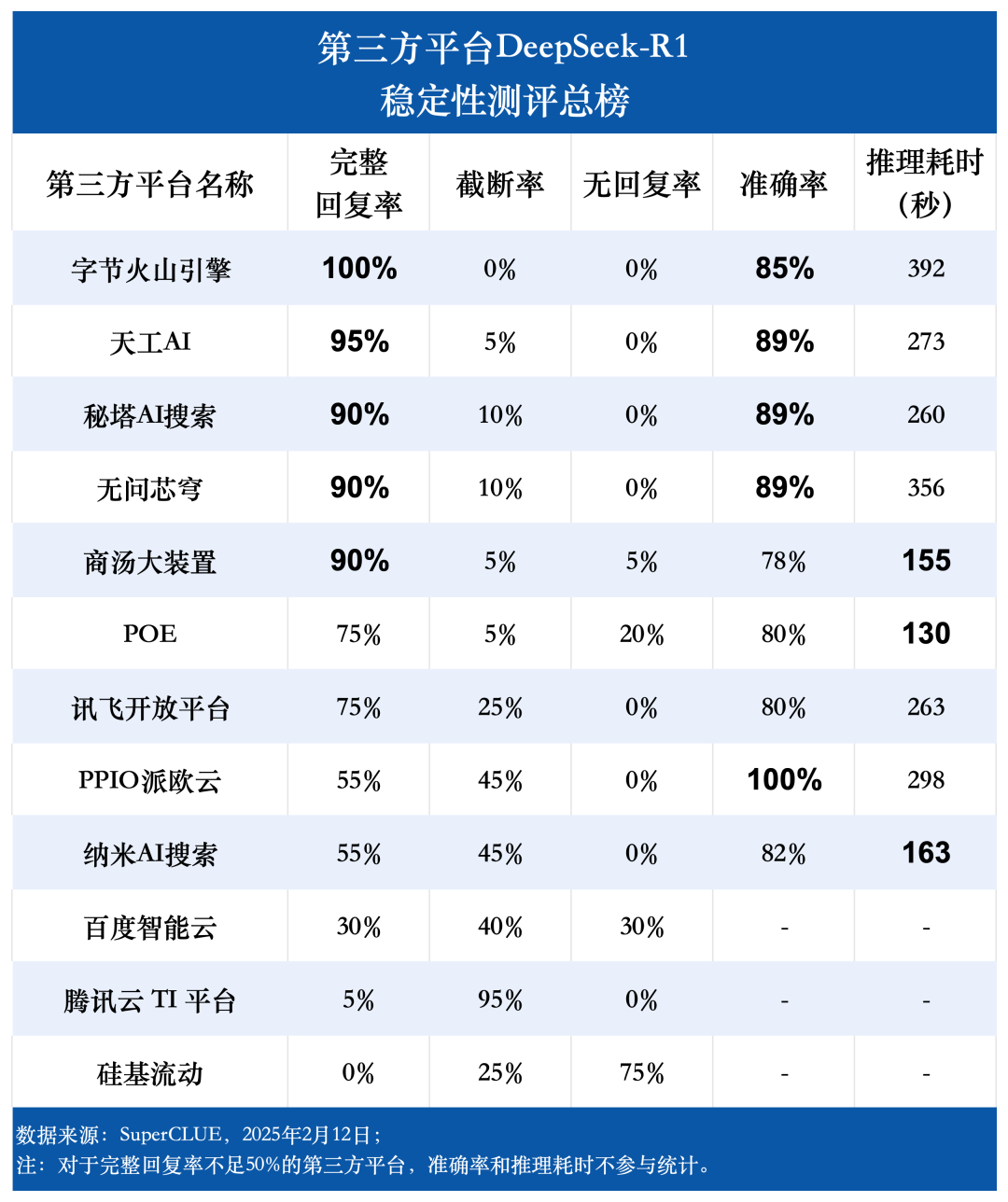
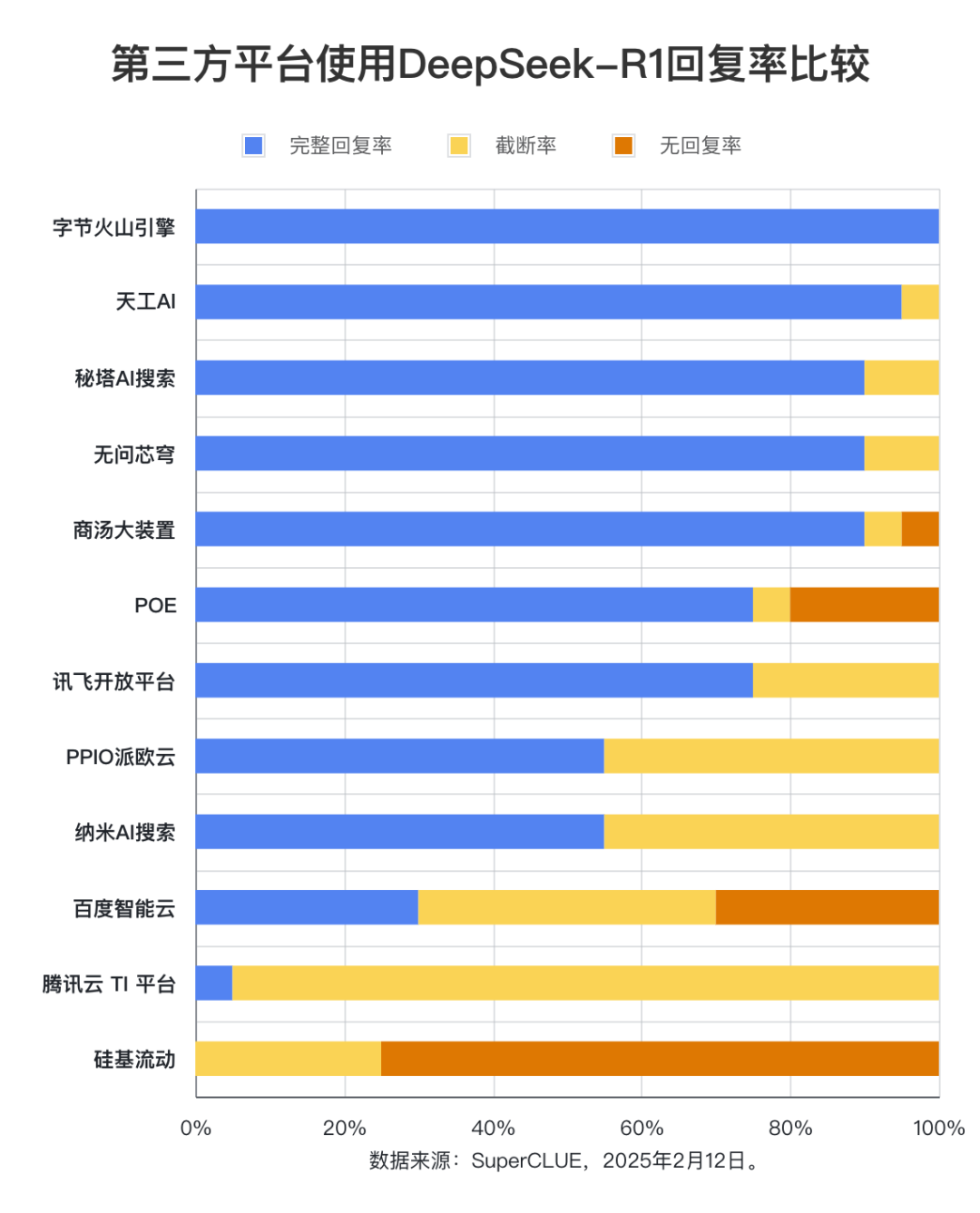
Evaluation point 1: Third-party platforms vary significantly in their DeepSeek-R1 complete response rates.
The evaluation results show that Byte Volcano Engine (100%), Tiangong AI (95%), Secret Pagoda AI Search, Unquestioning Core Dome, and Shangtang Big Device (all 90%) have outstanding performance in terms of complete response rate, demonstrating excellent stability. In contrast, Baidu Intelligent Cloud, Tencent Cloud TI Platform, and Silicon Mobility all had complete response rates lower than 50%, indicating that their stability could be improved. This finding emphasizes the importance of platform stability in the user selection process.
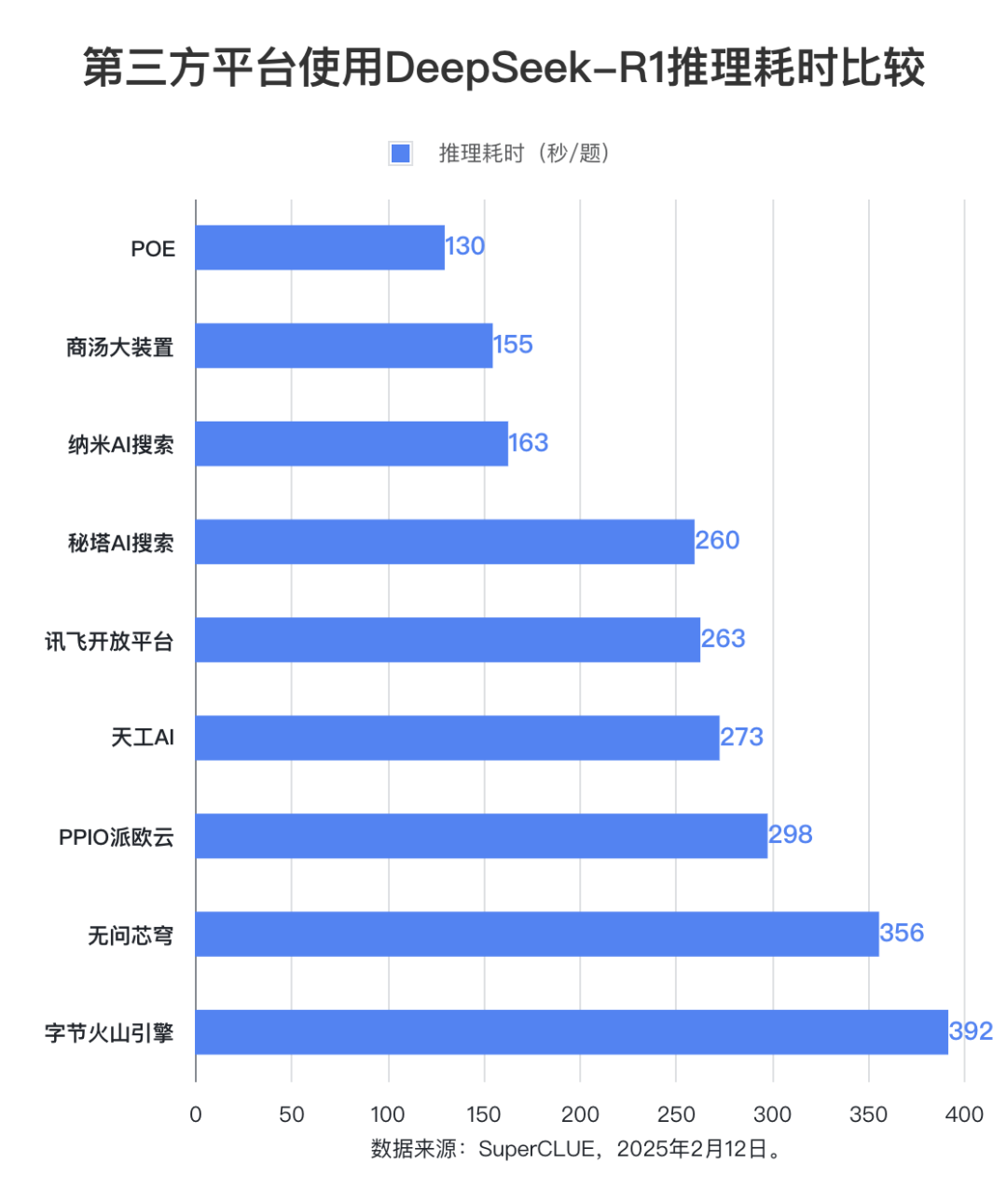
Evaluation point 2: The DeepSeek-R1 model inference time varies significantly across platforms, with the difference between the longest and shortest time-consuming platforms nearly three times.
In terms of inference time, the POE platform is the best performer, with an average time of 130 seconds per question. The BT Big Device and Nano AI Search follow closely behind, with an average time per question of 155 seconds and 163 seconds, respectively. Byte Volcano Engine took the longest average time per question, reaching 392 seconds.
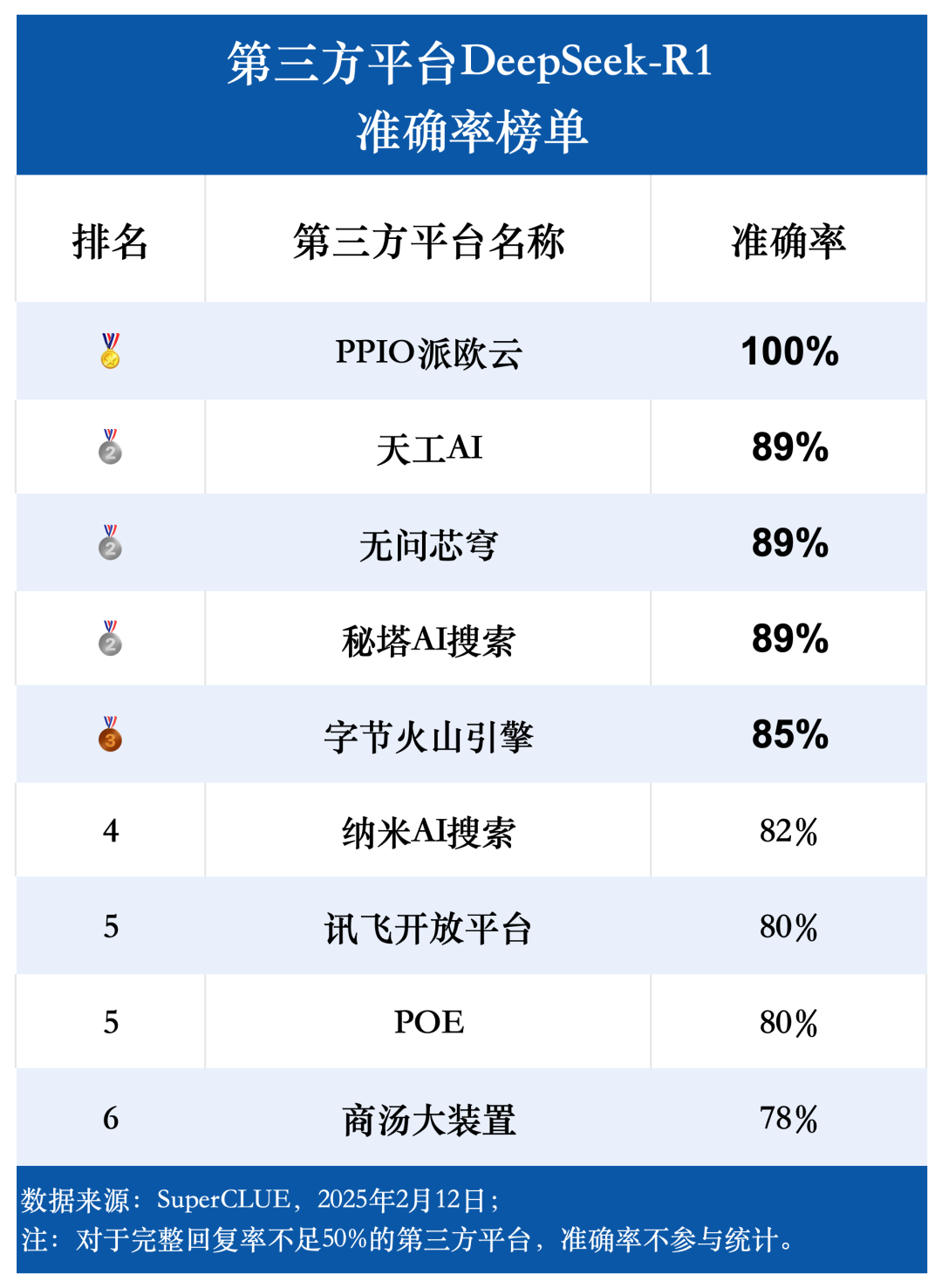
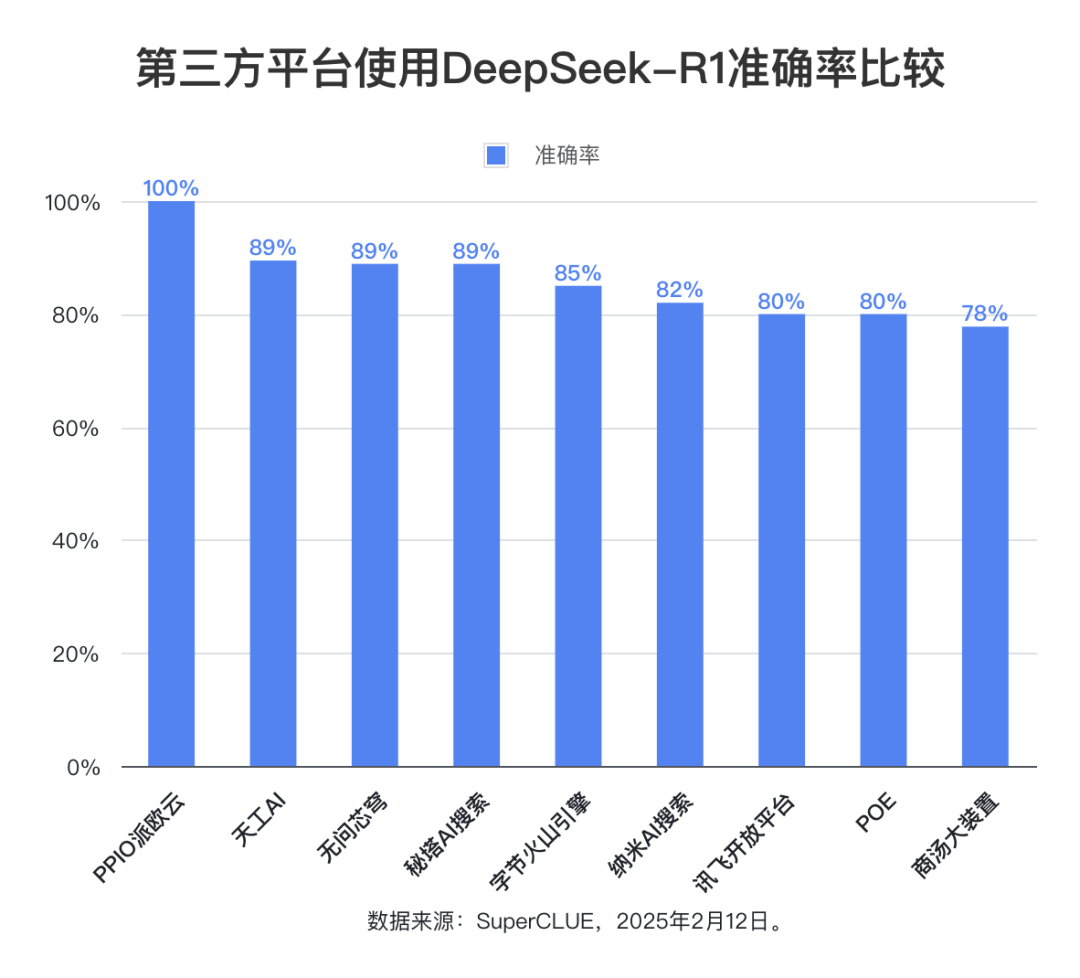
Evaluation point 3: The overall accuracy of the DeepSeek-R1 model is high across all platforms, reflecting the strong and reliable performance of the model itself.
The evaluation data shows that except for the platforms with a complete response rate lower than 50%, the average accuracy rate of the other nine platforms is as high as 85.76%, with the highest accuracy rate even reaching 100%, and the lowest accuracy rate remaining at 78%. This fully proves that the DeepSeek-R1 model itself has excellent performance and reliability, and can provide stable and high accuracy support for all kinds of third-party applications. This fully proves that the DeepSeek-R1 model itself has excellent performance and reliability, and can provide stable and high accuracy support for various third-party applications.
Overview of the list
Complete response rate + truncation rate + no response rate = 100%
- Complete response rate: The model gives complete responses without problems such as truncation or no response, but does not take into account whether the answer is correct or not. Calculated as the number of complete response questions divided by the total number of questions.
- truncation rate: The model had a break in the response process and failed to give a complete answer. Calculated as the number of truncated questions divided by the total number of questions.
- no reply rate: The model fails to give an answer for special reasons (e.g. no response/request error). Calculated as the number of non-responsive questions divided by the total number of questions.
- accuracy: For questions with complete responses to the model, the percentage of answers that agree with the standard answer. Only the correctness of the final answer is assessed, the solution process is not examined.
- Reasoning elapsed time (seconds/question): The average time used by the model to reason about each answer for questions with complete responses to the model.
Methodology
1. For each of the third-party platforms, a standardized test of 20 elementary school Olympiad questions was used to ensure fairness and comparability of the assessment.2. Considering that the output content of reasoning questions is usually long, for the support of adjusting the maximum output token For platforms with max_tokens, set this parameter to the maximum value, and leave the rest of the parameters at the platform's default settings.3. Statistical method of reasoning time-consuming: for platforms with their own reasoning timing function, the statistical results provided by the platform are used; for platforms that do not have this function, manual timing is used.
Evaluation results
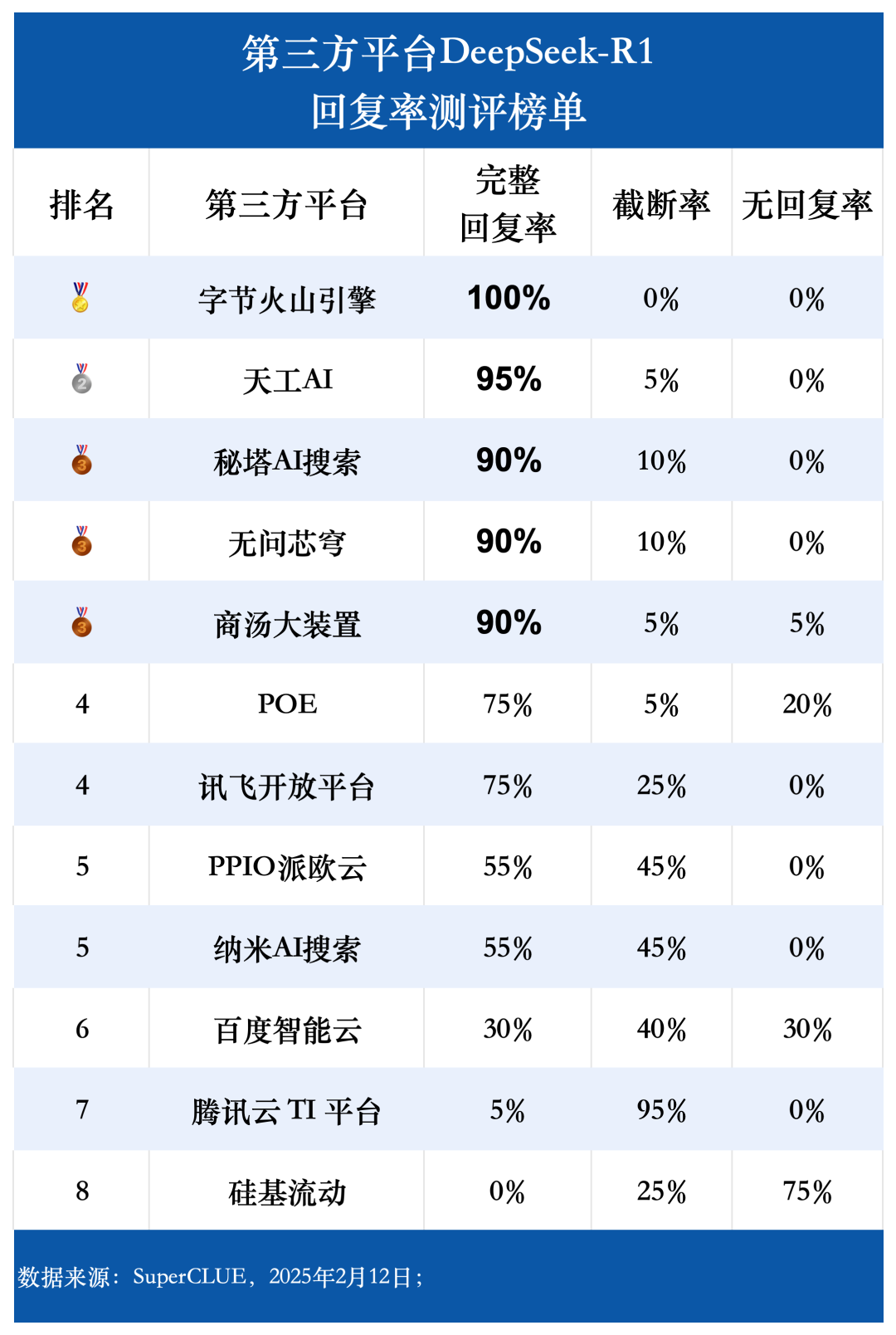
(1) Complete response rate
The evaluation data shows that the complete response rate of Byte Volcano Engine, Tiangong AI, Secret Tower AI Search, Unquestionable Core Dome and Shangtang Big Device all reached more than 90%. Among them, the byte volcano engine has the best performance, with a complete response rate of 100%. In contrast, the complete response rate of Baidu Intelligent Cloud, Tencent Cloud TI platform and silicon-based mobility is significantly lower, with a rate of less than 50%. In terms of truncation rate, the Tencent Cloud TI platform has a rate of up to 95%. silicon-based mobility has the most frequent cases of unresponsive or erroneous requests, with a rate of 75%. response rate reached 75%.
(2) Accuracy
The statistical range of the accuracy rate is limited to the questions for which the model gives a complete response, reflecting the proportion of questions that are answered correctly by the model. The evaluation results show that the average accuracy rate of nine third-party platforms using the DeepSeek-R1 model reaches 85.76%, which further confirms the high quality and reliability of the DeepSeek-R1 model itself and its ability to provide stable and accurate support for various application scenarios.
(3) Time-consuming reasoning
In terms of average inference time per question, the POE platform performs best at 130 seconds. The reasoning time of Shangtang Big Device and Nano AI Search is also relatively short, both within 200 seconds. The reasoning time of No Question Vault and Byte Volcano Engine is relatively long, both exceeding 350 seconds. Other platforms take between 250-300 seconds.

Sample Display
Title: A frog climbs up a 10-meter deep well at 6:00 a.m. For every 2 meters it climbs up the well, it slips 0.5 meters because of slippage in the walls. The time it takes to slide down 0.5 m is one-half the time it takes to climb up 2 m. At 6:12 a.m., the frog reaches a point 2.5 m from the mouth of the well, so how many minutes did it take the frog to climb from the bottom of the well to the mouth of the well?
Standard answer: 15.2 minutes (i.e. 15 minutes 12 seconds)
Reference answer (from the model: Gemini-2.0-Flash-Exp):

Cause analysis
1. The maximum output length limitation of the model is one of the important factors leading to the interruption of responses. Statistics show that some platforms fail to provide flexible adjustment of the max_tokens parameter (e.g., Baidu Intelligent Cloud, Tencent Cloud TI platform, etc.). This makes the model more prone to truncation when generating longer replies. The data shows that the average truncation rate of platforms that cannot set the max_tokens parameter is 39%, while the truncation rate of platforms that can set the parameter is 16.43%. In particular, in this evaluation, the complexity of elementary school Olympiad questions and the tediousness of the problem solving steps lead to a significant increase in the length of the content that needs to be generated by the model, and the problem of token restriction is further amplified as a result. that exacerbates the occurrence of output truncation.

2. Platform user load is also a potential factor that affects the stability of model services.
Considering the differences in user volume of different platforms, platforms with a larger number of users may face a higher risk of instability due to overloaded servers. The lack of platform service stability may indirectly affect the completeness and inference speed of model-generated responses.
Conclusions and recommendations
1. There are significant differences in the stability performance of different third-party platforms when deploying and running the DeepSeek-R1 model. Users are advised to choose a platform thatIntegrated assessment The technical architecture, resource scheduling capabilities, and user load of each platform, andIntegration of their own needs(e.g., response rate, reasoning time consumption, and other indicators) to weigh. For users seeking higher stability, they can prioritize platforms with relatively fewer users but more balanced resource allocation to reduce the risk of performance fluctuations due to high concurrency.
2. The evaluation data shows that platforms such as Byte Volcano Engine, Tiangong AI, Secret Tower AI Search, No Questions Asked Core Dome, and Shangtang Great DeviceComplete response rates of 90% and higherThe results show that these platforms perform well in guaranteeing the integrity and reliability of the model output. For application scenarios that need to ensure a high response rate, it is recommended that the above platforms be prioritized for technical support.
3. existtime-consuming reasoningAspects.POE platforms and big installations in Shangtang Demonstrating obvious advantages, its low-latency characteristics make it more suitable for application scenarios with high real-time requirements. It is recommended that users prioritize the sensitivity of reasoning time consumption according to specific business requirements when choosing a platform in order to achieve the best balance between performance and cost.
Attached is the DeepSeek-R1 experience site for each platform:
Byte Volcano Engine:https://console.volcengine.com/ark/region:ark+cn-beijing/experience/chat
Silicon-based flow: https://cloud.siliconflow.cn/playground/chat/17885302724
Baidu Smart Cloud: https://console.bce.baidu.com/qianfan/ais/console/onlineTest/LLM/DeepSeek-R1
Secret Tower AI Search: https://metaso.cn/
No questions asked core dome: https://cloud.infini-ai.com/genstudio/experience
PPIO Paio Cloud:https://ppinfra.com/llm
Nano AI Search: https://bot.n.cn/chat?src=AIsearch
Shang Tang's great device: https://console.sensecore.cn/aistudio/experience/conversation
Tinker AI: https://www.tiangong.cn/
POE:https://poe.com/
Tencent Cloud TI Platform: https://console.cloud.tencent.com/tione/v2/aimarket/detail/deepseek_series?regionId=1&detailTab=deep_seek_v1
Cyberoam Open Platform:https://training.xfyun.cn/experience/text2text?type=public&modelServiceId=2501631186799621
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts
![[转]用 2000 美元 EPYC 服务器本地跑起 Deepseek R1 671b 大模型](https://aisharenet.com/wp-content/uploads/2025/02/78984d5c0694467.png)


No comments...