Step-Video-T2V: A Vincennes Video Model Supporting Multilingual Input and Long Video Generation

General Introduction
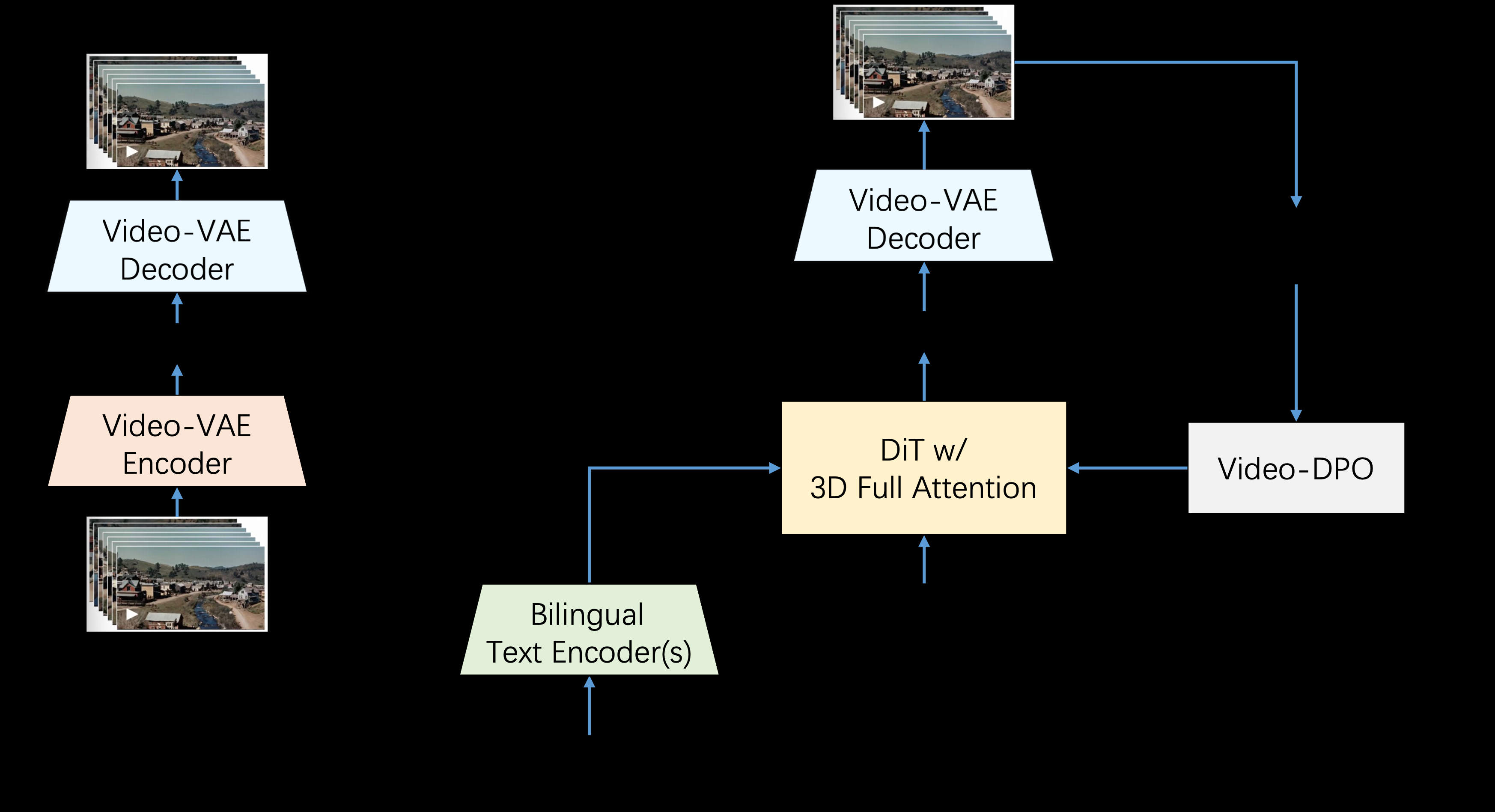
Step-Video-T2V is an advanced text-to-video conversion model by StepFun AI (Step Star). The model has 3 billion parameters and is capable of generating videos up to 204 fps. With a deeply compressed Variable Auto-Encoder (VAE), the model achieves a spatial compression of 16x16 and a temporal compression of 8x, which improves the efficiency of training and inference.Step-Video-T2V performs well in the field of video generation, especially in terms of video motion and efficiency. However, there are still some challenges for handling complex motions. The model is open source and users can access and contribute code on GitHub.
Function List
- Generate high-quality video: Generate videos up to 204 fps using 3 billion parameters.
- Deep compression technique: 16x16 spatial compression and 8x temporal compression using deep compression variational self-encoder.
- Bilingual Support: Supports text prompts in English and Chinese.
- Open source and community support: models and benchmark datasets are open sourced to foster innovation and empower creators.
Using Help
Installation process
- Cloning GitHub repositories:
git clone https://github.com/stepfun-ai/Step-Video-T2V.git - Go to the project catalog:
cd Step-Video-T2V - Create and activate a virtual environment:
conda create -n stepvideo python=3.10 conda activate stepvideo - Install the dependencies:
pip install -e . pip install flash-attn --no-build-isolation ## flash-attn是可选的
Guidelines for use
Generate Video
- Prepare text prompts to be saved in a file, for example
prompt.txt::飞机在蓝天中飞翔 - Run the video generation script:
python generate_video.py --input prompt.txt --output video.mp4
Detailed function operation flow
- Generate high quality video::
- Text Input: User inputs text describing the content of the video.
- Model Processing: the Step-Video-T2V model parses text and generates video.
- Video Output: The generated video is saved in MP4 format, which can be viewed and shared by users at any time.
- Deep compression technology::
- Spatial compression: Improve the efficiency of video generation through 16x16 spatial compression technology.
- Temporal compression: Video generation speed and quality are further optimized through 8x temporal compression technology.
- Bilingual support::
- English support: Users can input English text, and the model automatically parses and generates the corresponding video.
- Chinese support: Users can enter Chinese text, the model can also generate the corresponding video, to support the needs of multilingual users.
- Open source and community support::
- Open source code: Users can access the full code of the model on GitHub to deploy and modify it themselves.
- Community contribution: Users can submit code contributions to participate in model improvement and optimization.
Single-GPU Inference and Quantization
The Step-Video-T2V project supports single-GPU inference and quantization, significantly reducing the amount of video memory required. Please refer toRelated ExamplesGet details.
Best Practice Reasoning Settings
Step-Video-T2V performs well in the inference setting, consistently generating high-fidelity and dynamic video. However, our experiments show that variations in the inference hyperparameters affect the generation quality.
| Models | infer_steps | cfg_scale | time_shift | num_frames |
|---|---|---|---|---|
| Step-Video-T2V | 30-50 | 9.0 | 13.0 | 204 |
| Step-Video-T2V-Turbo (Inference Step) Distillation) | 10-15 | 5.0 | 17.0 | 204 |
Model Download
| mould | 🤗 Huggingface | 🤖 Modelscope |
|---|---|---|
| Step-Video-T2V | downloading | downloading |
| Step-Video-T2V-Turbo (Inference Step Distillation) | downloading | downloading |
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts

No comments...