
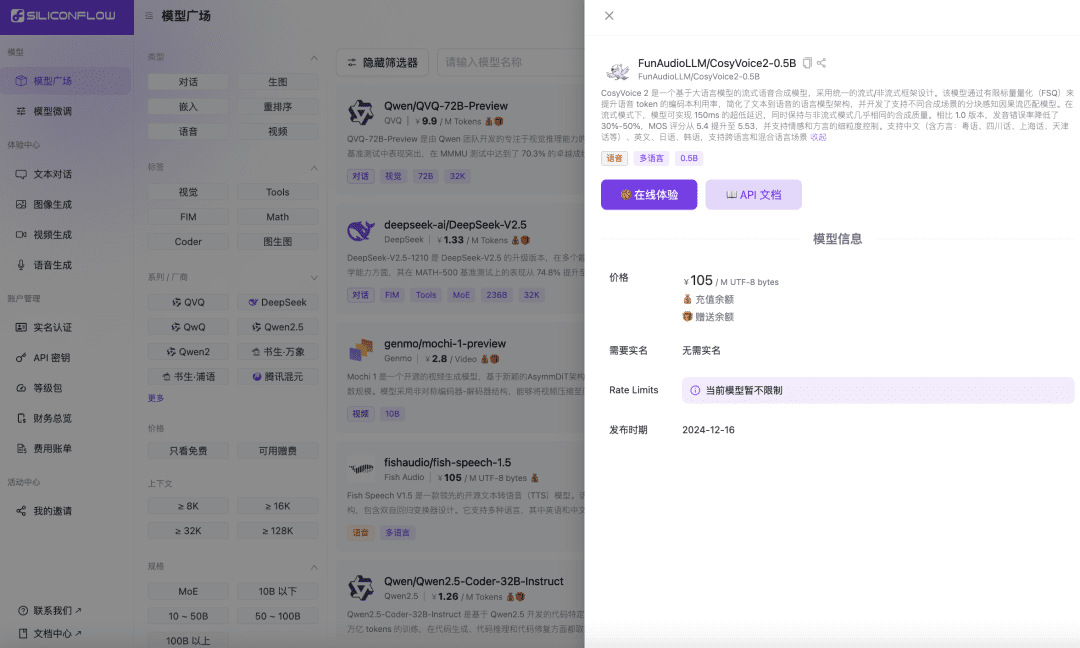
Siliconcloud Goes Live with Accelerated CosyVoice2: 150ms Real-Time Speech Synthesis, Support for Mixed Languages and Dialects


Recently, the speech team of Ali Tongyi Lab officially released a speech synthesis modelCosyVoice2. The model supports bi-directional streaming of text and speech, supports multilingualism, mixed languages and dialects, and provides more accurate, stable, faster and better speech generation capabilities. Now, Siliconcloud, a silicon-based flow Siliconcloud, is officially online with the inference acceleration version CosyVoice2-0.5B (priced at ¥105/ M UTF-8 bytes, each character occupies 1 to 4 bytes), which includes the network transmission time, making the model output latency as low as 150ms, bringing a more efficient user experience to your generative AI applications. Like other language synthesis models on SiliconCloud, CosyVoice2 supports out-of-the-box 8 preset tones, user-preset tones as well as dynamic tones, and customizable speech rate, audio gain, and output sample rate.
Online Experience
https://cloud.siliconflow.cn/playground/text-to-speech/17885302679
API documentation
https://docs.siliconflow.cn/api-reference/audio/create-speech
Get a feel for SiliconCloud's reasoning-accelerated version of CosyVoice 2.0.
Combined with SiliconCloud's previously liveAli Speech Recognition Model SenseVoice-Small (available for free)With the help of the model API, developers can efficiently develop end-to-end voice interaction applications, including audiobooks, streaming audio outputs, virtual assistants, and other applications.
Model features and performance
CosyVoice2 is a streaming speech synthesis model based on a large language model, designed using a unified streaming/non-streaming framework. The model improves the codebook utilization of speech tokens through Finite Scalar Quantization (FSQ), simplifies the text-to-speech language model architecture, and develops a chunk-aware causal stream matching model that supports different synthesis scenarios. In streaming mode, the model achieves an ultra-low latency of 150ms while maintaining almost the same synthesis quality as in non-streaming mode.
In addition, CosyVoice2 has made significant progress in the integration of the base model and the command model, not only continuing the support for emotions, speaking styles and fine-grained control commands, but also adding the ability to handle Chinese commands.CosyVoice2 also introduces role-playing features, such as the ability to mimic robots and Peppa Pig's style of speech.
Specifically, version 2.0 has the following advantages over CosyVoice version 1.0:
Multi-language support
- Supported languages: Chinese, English, Japanese, Korean, Chinese dialects (Cantonese, Sichuan, Shanghainese, Tianjin, Wuhan, etc.)
- Cross-language & Mixed-language: Supports zero-sample speech cloning in cross-language and code-switching scenarios.
ultra-low latency
- Bi-directional streaming support: CosyVoice 2.0 integrates offline and streaming modeling technologies.
- Fast First Packet Synthesis: Achieve delays as low as 150 ms while maintaining high quality audio output.
highly accurate
- Pronunciation Improvement: Pronunciation errors reduced by 30% to 50% compared to CosyVoice 1.0.
- Benchmark Achievement: achieve the lowest character error rate on the difficult test set of the Seed-TTS evaluation set.
high stability
- Tone Consistency: Ensures reliable and consistent timbre for zero-sample and cross-lingual speech synthesis.
- Cross-language synthesis: significant improvements over version 1.0.
natural fluency
- Rhythmic and tonal enhancement: increased MOS assessment score from 5.4 to 5.53.
- Emotion and dialect flexibility: Supports finer emotion control and dialect accent adjustment.
Developer Evaluation
Once CosyVoice 2.0 was released, some developers experienced it first. Some developers said that it supports ultra-fine control features and more realistic and natural voice synthesis. 
 However, some users said that despite being attracted by its excellent speech generation performance, deployment became a major challenge.
However, some users said that despite being attracted by its excellent speech generation performance, deployment became a major challenge. 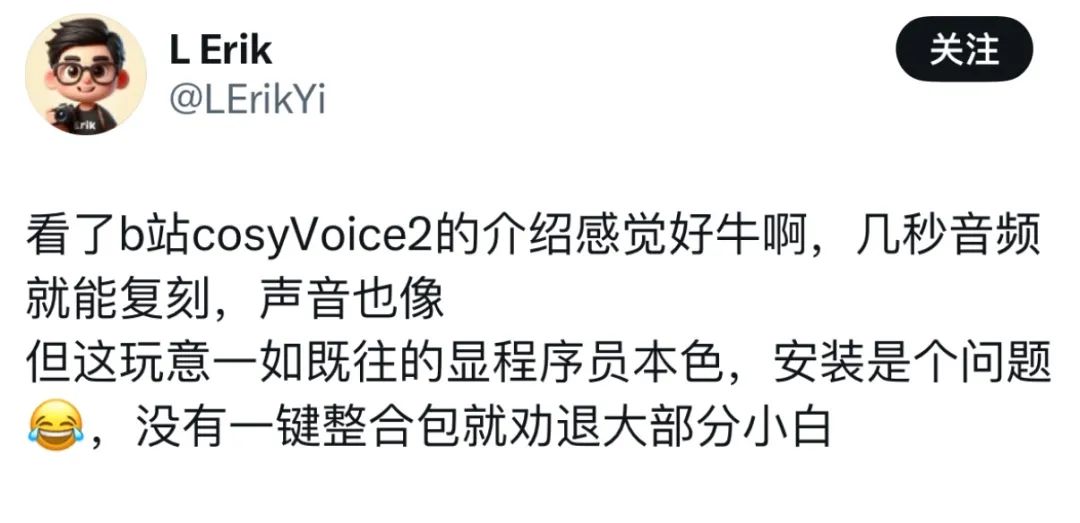 Now that Siliconcloud has gone live with CosyVoice 2.0, eliminating the need for complex deployments, you can just easily call the API and access your own apps.
Now that Siliconcloud has gone live with CosyVoice 2.0, eliminating the need for complex deployments, you can just easily call the API and access your own apps.
Token Factory SiliconCloud Qwen 2.5 (7B) and 20+ other models for free!
As a one-stop big model cloud service platform, SiliconCloud is committed to providing developers with extremely fast response, affordable, complete categories, and silky smooth experience of model API. In addition to CosyVoice2, SiliconCloud has already shelved the model APIs including QVQ-72B-Preview, DeepSeek-VL2, DeepSeek- V2.5-1210, mochi-1-preview, Llama-3.3-70B-Instruct, HunyuanVideo, fish-speech-1.5, QwQ-32B-Preview, Qwen2.5-Coder-32B-Instruct, InternVL2 Qwen2.5-7B/14B/32B/72B, FLUX.1, InternLM2.5-20B-Chat, BCE, BGE, SenseVoice-Small, GLM-4-9B-Chat, and dozens of open source large language models, picture/video generation models, speech models, code/mathematics models, and vector and reordering models. 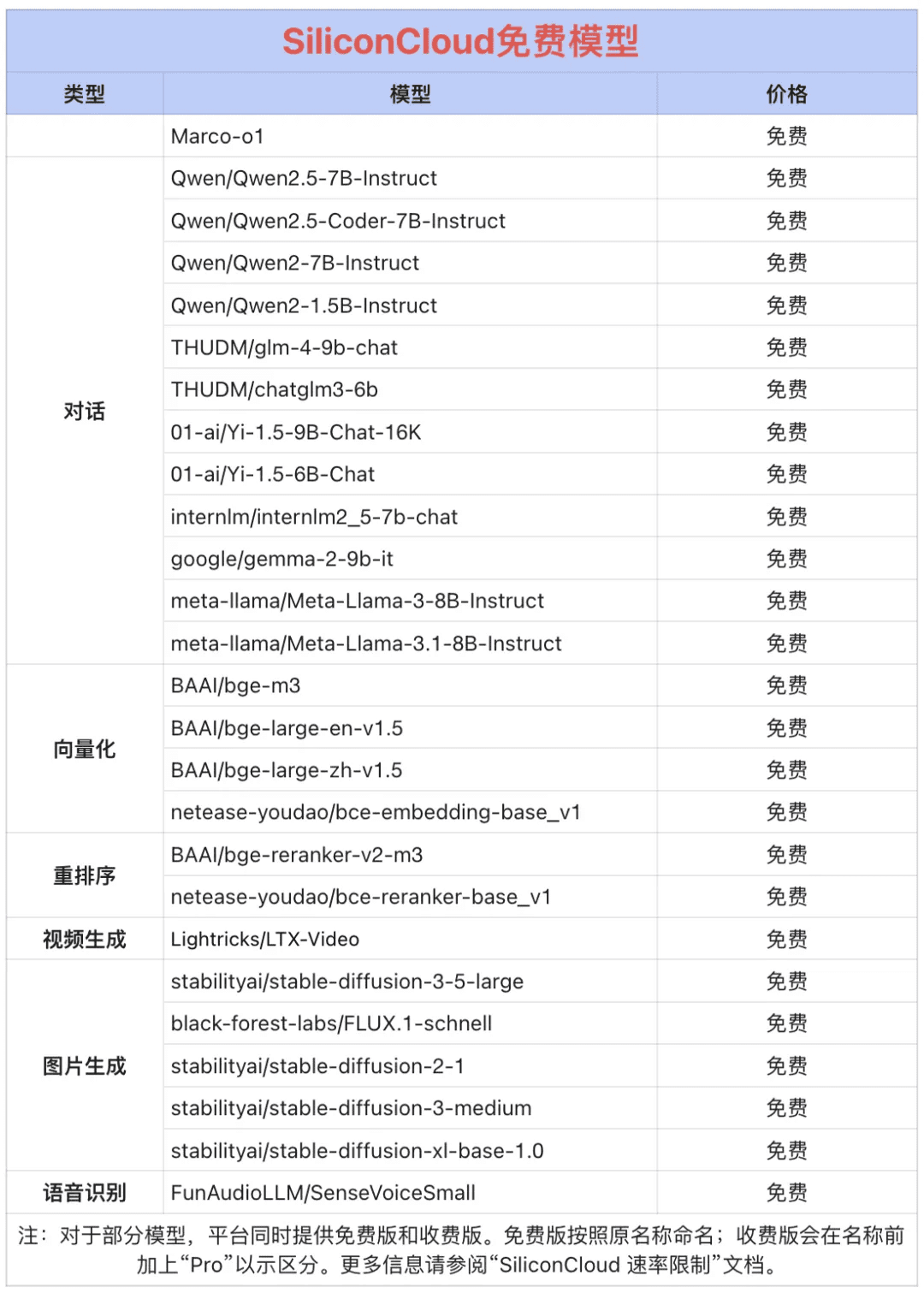 Among them, Qwen2.5 (7B), Llama3.1 (8B) and other 20+ big model APIs are free to use, so that developers and product managers do not need to worry about the arithmetic cost of the research and development phase and large-scale promotion, and realize the "Token Freedom".
Among them, Qwen2.5 (7B), Llama3.1 (8B) and other 20+ big model APIs are free to use, so that developers and product managers do not need to worry about the arithmetic cost of the research and development phase and large-scale promotion, and realize the "Token Freedom".
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts




No comments...