
SiliconCloud x FastGPT: Enabling 200,000 Users to Build an Exclusive AI Knowledge Base


FastGPT is a knowledge base Q&A system based on the LLM model, developed by the Circle Cloud team, providing out-of-the-box data processing, model invocation and other capabilities. FastGPT can also be used for workflow orchestration through Flow visualization to realize complex Q&A scenarios.FastGPT has gained 19.4k stars on Github.
SiliconCloud of Silicon Flow is a big model cloud service platform and has its own acceleration engine.SiliconCloud can help users to test and use open source models in a low-cost and fast way. The actual experience is that the speed and stability of their models are very good, and they are rich in variety, covering dozens of models such as languages, vectors, reordering, TTS, STT, mapping, video generation, etc., which can satisfy all the modeling needs in FastGPT.
This article is a tutorial written by the FastGPT team that will present a solution for deploying FastGPT in local development using exclusively SiliconCloud models.
1 Obtaining the SiliconCloud Platform API Key
- Open the SiliconCloud website and register/sign in for an account.
- After completing the registration, open API Key , create a new API Key and click on the key to copy it for future use.

2 Modifying FastGPT Environment Variables
OPENAI_BASE_URL=https://api.siliconflow.cn/v1 # 填写 SiliconCloud 控制台提供的 Api Key CHAT_API_KEY=sk-xxxxxx
FastGPT development and deployment documentation: https://doc.fastgpt.cn
3 Modifying the FastGPT Configuration File
The models in SiliconCloud were selected as FastGPT configurations. Here Qwen2.5 72b is configured with pure language and vision models; bge-m3 is selected as the vector model; bge-reranker-v2-m3 is selected as the rearrangement model. Choose fish-speech-1.5 as the speech model; choose SenseVoiceSmall as the speech input model.
Note: The ReRank model still needs to be configured with the API Key once.
{
"llmModels": [
{
"provider": "Other", // 模型提供商,主要用于分类展示,目前已经内置提供商包括:https://github.com/labring/FastGPT/blob/main/packages/global/core/ai/provider.ts, 可 pr 提供新的提供商,或直接填写 Other
"model": "Qwen/Qwen2.5-72B-Instruct", // 模型名(对应OneAPI中渠道的模型名)
"name": "Qwen2.5-72B-Instruct", // 模型别名
"maxContext": 32000, // 最大上下文
"maxResponse": 4000, // 最大回复
"quoteMaxToken": 30000, // 最大引用内容
"maxTemperature": 1, // 最大温度
"charsPointsPrice": 0, // n积分/1k token(商业版)
"censor": false, // 是否开启敏感校验(商业版)
"vision": false, // 是否支持图片输入
"datasetProcess": true, // 是否设置为文本理解模型(QA),务必保证至少有一个为true,否则知识库会报错
"usedInClassify": true, // 是否用于问题分类(务必保证至少有一个为true)
"usedInExtractFields": true, // 是否用于内容提取(务必保证至少有一个为true)
"usedInToolCall": true, // 是否用于工具调用(务必保证至少有一个为true)
"usedInQueryExtension": true, // 是否用于问题优化(务必保证至少有一个为true)
"toolChoice": true, // 是否支持工具选择(分类,内容提取,工具调用会用到。)
"functionCall": false, // 是否支持函数调用(分类,内容提取,工具调用会用到。会优先使用 toolChoice,如果为false,则使用 functionCall,如果仍为 false,则使用提示词模式)
"customCQPrompt": "", // 自定义文本分类提示词(不支持工具和函数调用的模型
"customExtractPrompt": "", // 自定义内容提取提示词
"defaultSystemChatPrompt": "", // 对话默认携带的系统提示词
"defaultConfig": {}, // 请求API时,挟带一些默认配置(比如 GLM4 的 top_p)
"fieldMap": {} // 字段映射(o1 模型需要把 max_tokens 映射为 max_completion_tokens)
},
{
"provider": "Other",
"model": "Qwen/Qwen2-VL-72B-Instruct",
"name": "Qwen2-VL-72B-Instruct",
"maxContext": 32000,
"maxResponse": 4000,
"quoteMaxToken": 30000,
"maxTemperature": 1,
"charsPointsPrice": 0,
"censor": false,
"vision": true,
"datasetProcess": false,
"usedInClassify": false,
"usedInExtractFields": false,
"usedInToolCall": false,
"usedInQueryExtension": false,
"toolChoice": false,
"functionCall": false,
"customCQPrompt": "",
"customExtractPrompt": "",
"defaultSystemChatPrompt": "",
"defaultConfig": {}
}
],
"vectorModels": [
{
"provider": "Other",
"model": "Pro/BAAI/bge-m3",
"name": "Pro/BAAI/bge-m3",
"charsPointsPrice": 0,
"defaultToken": 512,
"maxToken": 5000,
"weight": 100
}
],
"reRankModels": [
{
"model": "BAAI/bge-reranker-v2-m3", // 这里的model需要对应 siliconflow 的模型名
"name": "BAAI/bge-reranker-v2-m3",
"requestUrl": "https://api.siliconflow.cn/v1/rerank",
"requestAuth": "siliconflow 上申请的 key"
}
],
"audioSpeechModels": [
{
"model": "fishaudio/fish-speech-1.5",
"name": "fish-speech-1.5",
"voices": [
{
"label": "fish-alex",
"value": "fishaudio/fish-speech-1.5:alex",
"bufferId": "fish-alex"
},
{
"label": "fish-anna",
"value": "fishaudio/fish-speech-1.5:anna",
"bufferId": "fish-anna"
},
{
"label": "fish-bella",
"value": "fishaudio/fish-speech-1.5:bella",
"bufferId": "fish-bella"
},
{
"label": "fish-benjamin",
"value": "fishaudio/fish-speech-1.5:benjamin",
"bufferId": "fish-benjamin"
},
{
"label": "fish-charles",
"value": "fishaudio/fish-speech-1.5:charles",
"bufferId": "fish-charles"
},
{
"label": "fish-claire",
"value": "fishaudio/fish-speech-1.5:claire",
"bufferId": "fish-claire"
},
{
"label": "fish-david",
"value": "fishaudio/fish-speech-1.5:david",
"bufferId": "fish-david"
},
{
"label": "fish-diana",
"value": "fishaudio/fish-speech-1.5:diana",
"bufferId": "fish-diana"
}
]
}
],
"whisperModel": {
"model": "FunAudioLLM/SenseVoiceSmall",
"name": "SenseVoiceSmall",
"charsPointsPrice": 0
}
}
4 Reboot FastGPT
5 Experience Test
Testing dialog and picture recognition
Just create a new simple application, select the corresponding model, and test it with image upload turned on.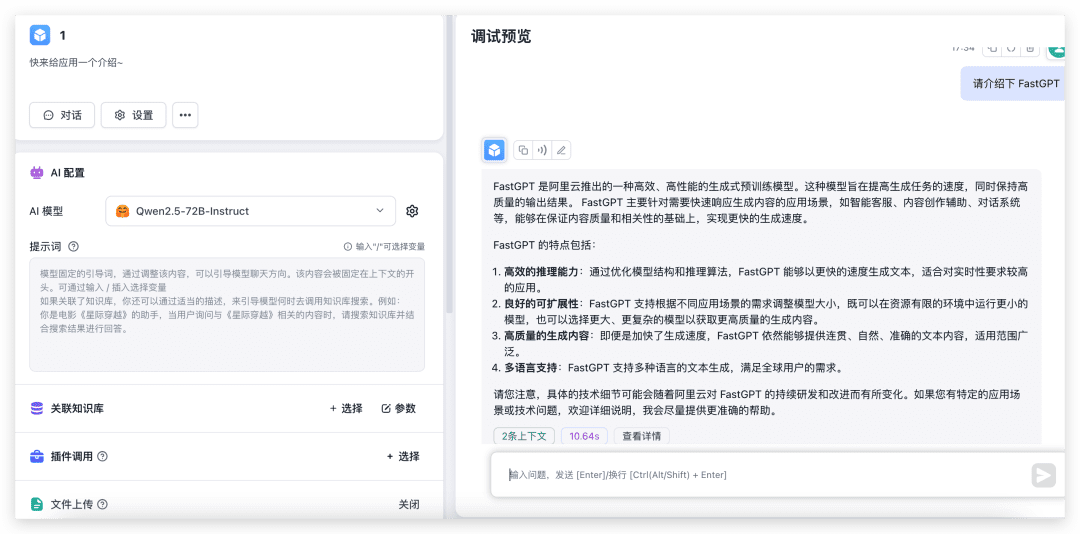
As you can see, the 72B model, the performance is very fast, which if there are not a few local 4090, not to mention the configuration of the environment, I am afraid that the output will take 30s.
Testing Knowledge Base Import and Knowledge Base Q&A
Create a new knowledge base (since only one vector model is configured, the vector model selection will not be displayed on the page).
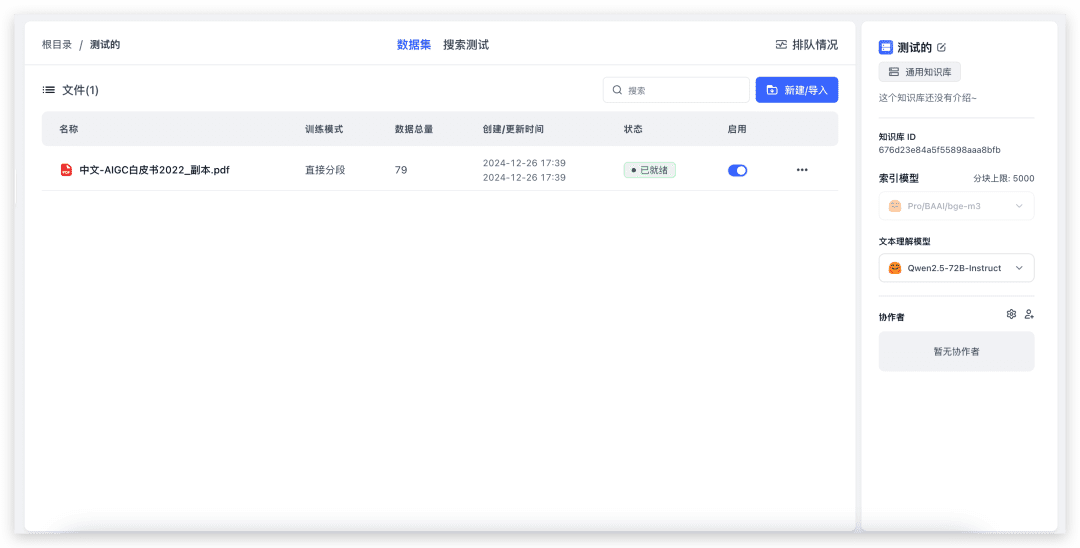
To import a local file, just select the file and go all the way to next. 79 indexes and it took about 20s to complete. Now let's go test the Knowledge Base quiz.
First go back to the application we just created, select Knowledge Base, adjust the parameters and start the conversation.
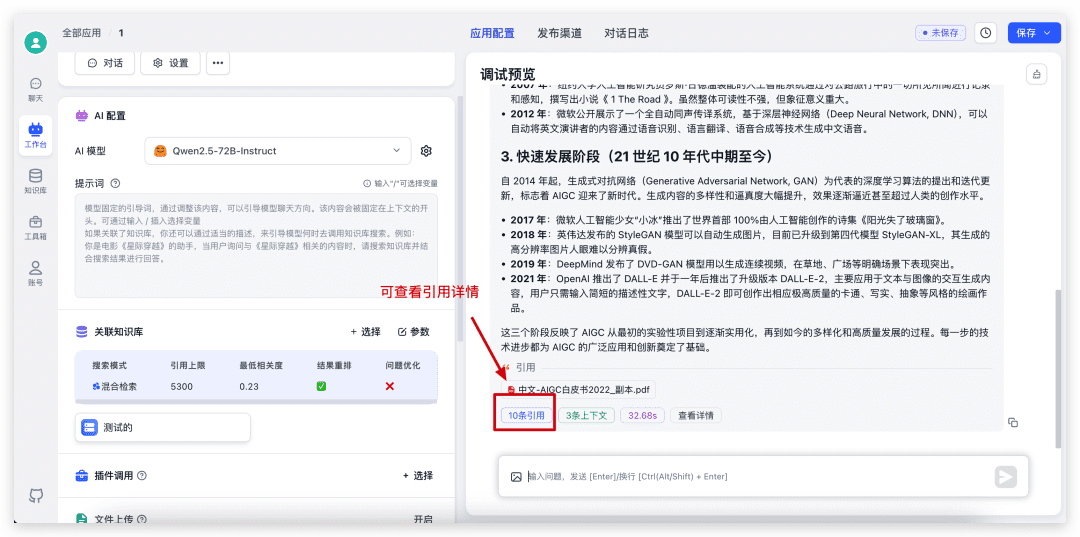
Once the dialog is complete, click on the citation at the bottom to view the citation details, as well as to see the specific retrieval and reordering scores.
Test voice playback
Continuing in the app just now, find Voice Play on the left side of the configuration and click on it to select a voice model from the pop-up window and try it out.
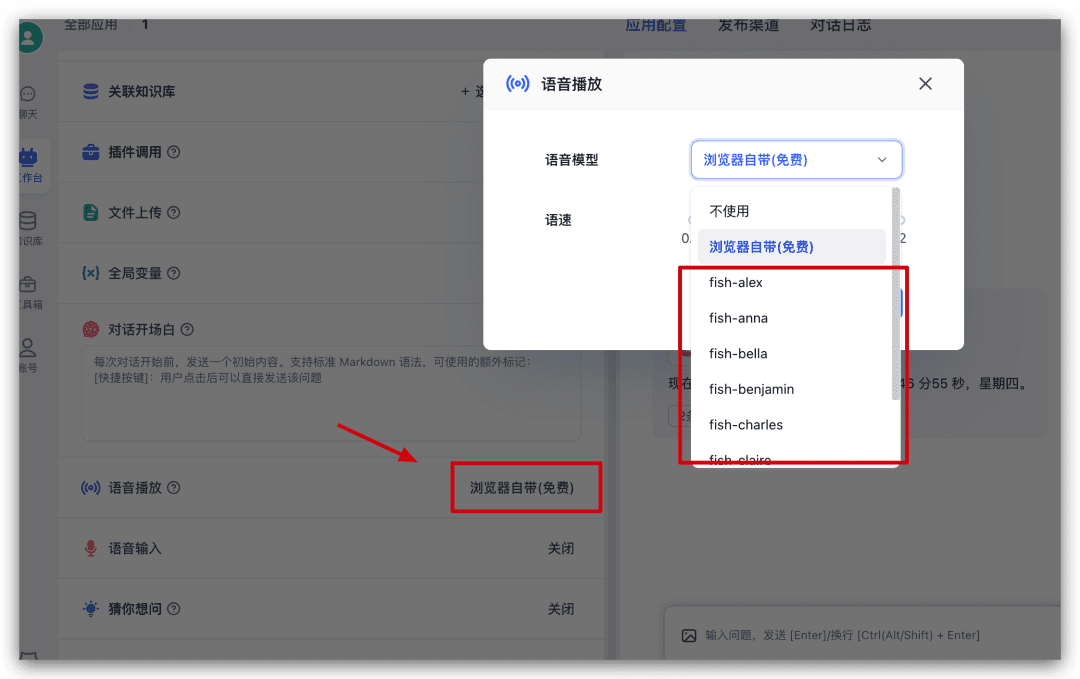
Test Language Input
Go ahead and find the voice input in the left side configuration in the app just now and click on it to enable language input from the pop-up window.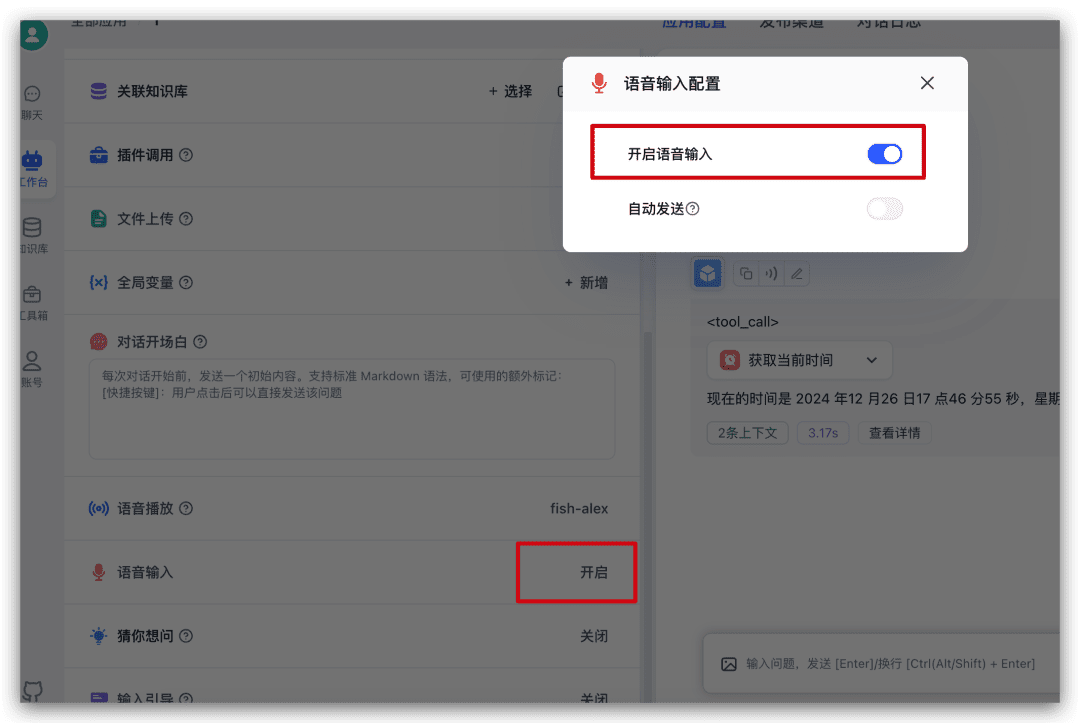
When you turn it on, a microphone icon will be added to the dialog input box, and you can click it for voice input.
summarize
If you want to quickly experience the open source model or quickly use FastGPT, and don't want to apply for all kinds of API keys at different service providers, then you can choose SiliconCloud's model for a quick experience.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...