
The first financial industry reasoning big model Regulus-FinX1 open source! Du Xiaoman heavy production, focusing on financial complex analysis and decision-making

Du Xiaoman open-sources the world's first big model of financial industry reasoning - Regulus-FinX1!
The model is the first GPT-O1-like inference macromodel in the financial field, using an innovative"Chain of Thought + Process Rewards + Reinforcement Learning"The training paradigm significantly improves logical reasoning and can demonstrate the complete thought process not disclosed by the O1 model, providing deeper insights for financial decision-making. Regulus-FinX1 targetsAnalytics, decision-making and data processing tasks in financial scenariosDeep optimization was performed.
Xuanyuan-FinX1 is developed by Du Xiaoman AI-Lab, and this release is a preview version, which is now open in the open source communityFree Download. Subsequent optimized versions will also continue to be open-sourced for download and use.
Github address: https://github.com/Duxiaoman-DI/XuanYuan
Benchmarking results
The first-generation Regulus-FinX1 demonstrated excellent performance on FinanceIQ, a financial review benchmark. On theCPA, Banking Qualification10 types of authoritative financial qualifications, such as qualification, securities qualification, etc.In the category of Actuaries, the scores of all previous large models are generally low, while XuanYuan-FinX1 has significantly improved its score from 37.5 to 65.7, which shows that it can be used for financial logical reasoning and mathematical reasoning, and it can be used for financial logical reasoning and mathematical reasoning. Especially in the actuary category, the scores of all previous large models were generally low, while XuanYuan-FinX1 improved its score from 37.5 to 65.7, which significantly demonstrated its strong advantage in financial logical reasoning and mathematical computation. 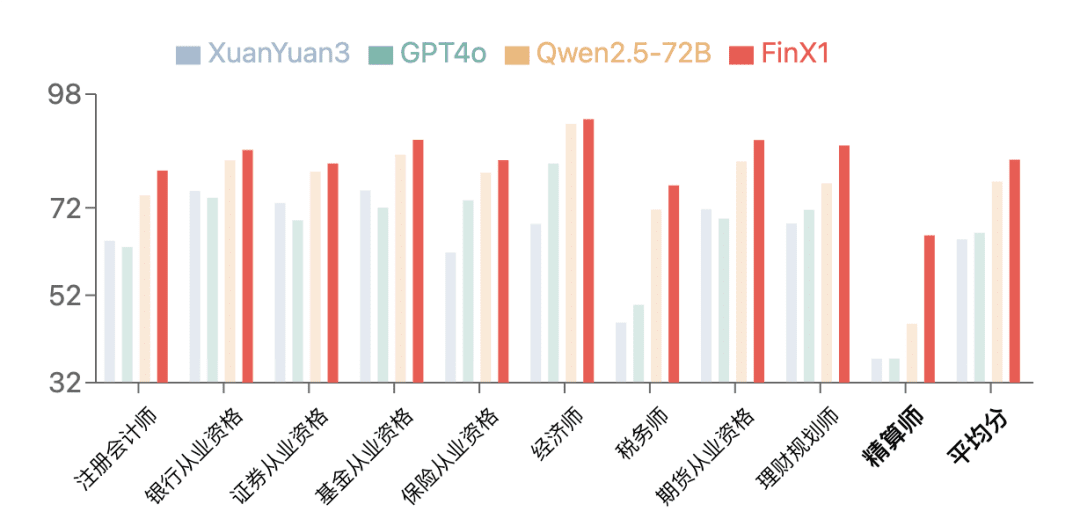
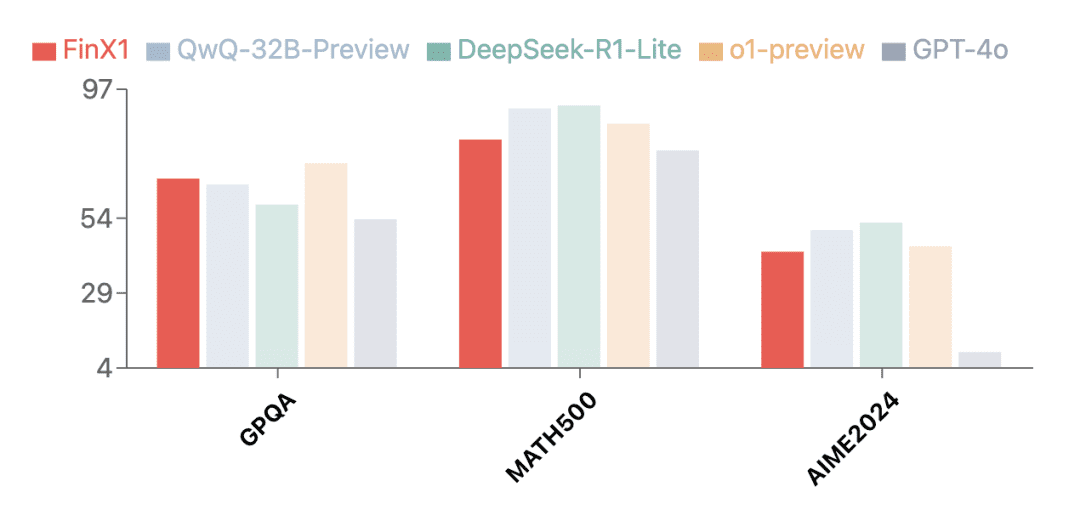
In addition to the financial field, the first-generation Regulus-FinX1 also demonstrated outstanding general-purpose capabilities. Test results on several authoritative evaluation sets show that Regulus-FinX1 is not only in theGPQA (Scientific Reasoning),MATH-500 (Mathematics)cap (a poem)AIME2024 (math competition)It has also surpassed GPT-4o, ranking in the top echelon together with O1 and the newly released inference version of Big Model in China, verifying its strong basic inference capability.
Breaking the "black box": presenting the full chain of thought
One of the features of Regulus FinX1 is that it can present the complete thinking process before generating the answer, and build a fully transparent thinking chain from problem disassembly to final conclusion. Through this mechanism, Regulus FinX1 not only improves the interpretability of reasoning, but also solves the "black box" problem of traditional large models, providing financial institutions with a more credible decision support tool.

Regulus Example of thought chain generation for FinX1
Specialized in financial complexity analysis and decision making
When OpenAI's GPT-O1 caught the industry's attention with its superior "thinking power," a key proposition emerged:How can we make this deep reasoning capability create substantial value in financial professional scenarios?Regulus FinX1 gives an innovative answer--For the first time, the deep reasoning capability of big models has been injected into the financial field, thus driving the big model applicationUse to go deeper from generic scenarios to core business levels such as risk control decisions.
In the wave of digital and intellectual transformation of the financial industry, the"Decision-making and risk control capabilities", "research and analysis capabilities" and "data intelligence capabilities"constitute the key dimensions that drive business innovation and value enhancement. These capabilities bring sustained value growth to institutions through accurate risk identification and control, in-depth market research and value discovery, and efficient data modeling and analysis, respectively.
Regulus FinX1 deeply integrates deep reasoning capabilities with financial expertise through an innovative training paradigm, allowing these three capabilities to be fully unleashed in specific scenarios and bringing new intelligent solutions to the financial industry.

01 Decision-making and risk control capacity
Decision-making and risk control capability is the lifeline of financial institutions, which is related to their sound operation and sustainable development. In the core tasks of risk identification and prediction, risk control model construction, and strategy formulation, Regulus FinX1 can systematically analyze the correlation and conduction paths between risk factors with its powerful reasoning ability and complete chain-of-mind mechanism, providing comprehensive and in-depth risk insights for the institution. For example, based on the bank water uploaded by the user's authorization, Regulus FinX1 is able to accurately identify risk signals such as high-frequency lottery consumption and game consumption from thousands of transaction records, and scientifically assess the user's repayment ability and credit risk by combining the income level and debt burden.

Regulus FinX1 replied to the clip
02 Research and analytical capacity
Research and analysis capability is the basic support for financial decision-making, which enhances the science of capital allocation through in-depth insights on macro, industry and company levels. Regulus FinX1 is able to analyze macroeconomic data, market sentiment, policy impacts, etc. in multiple dimensions, and gradually dismantle complex issues through a clear logic chain. For example, when predicting the Fed's interest rate cut in 2025 based on economic data, the model explores a wide range of possibilities by analyzing various economic factors and based on different hypothetical scenarios, comprehensively and objectively demonstrating the prospect of the Fed's interest rate cut in 2025, which is currently in line with the predictive analytical views of a number of institutions. 
03 Data intelligence capabilities
Data intelligence capability is an important support for financial institutions to realize accurate decision-making, the core of which is efficient data processing capability and in-depth analysis capability. Regulus FinX1 can help financial institutions quickly explore the business logic and value behind the data. For example, if a company's quarterly financial data is input into Regulus FinX1, the model can accurately extract the core information and visualize the asset quality, liquidity and business dynamics. By analyzing key indicators such as "liquidity pressure" and "asset expansion drive", Regulus FinX1 adds qualitative explanations based on quantitative comparisons, revealing potential risks and growth opportunities behind the financial data and helping companies optimize their decision-making. 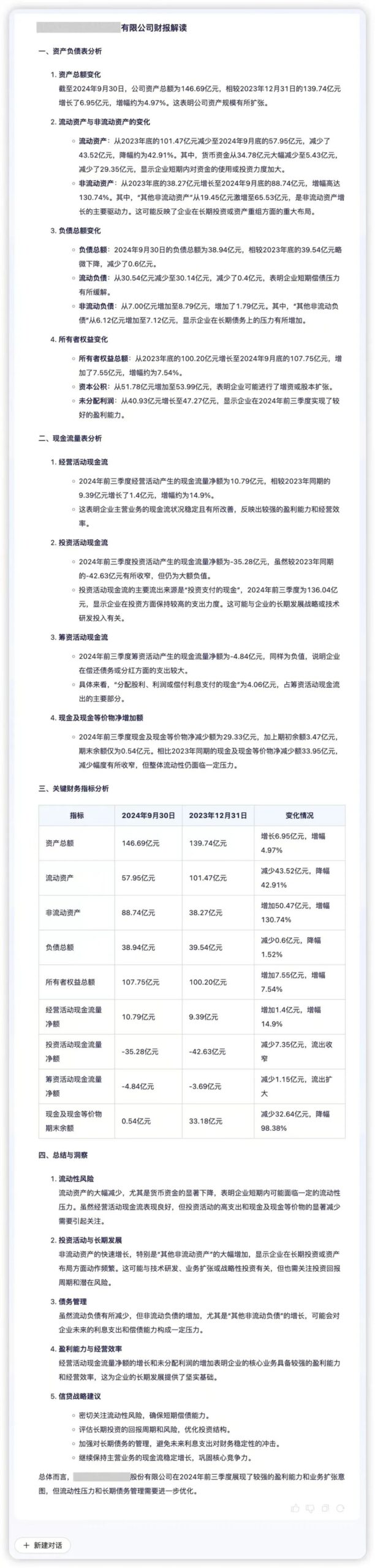
Technical realization of Regulus-FinX1
In order to realize the large model with O1-like reasoning capability, especially in the complex decision analysis scenarios in the financial domain, we propose a technical scheme containing three key steps after a lot of exploration and validation:Toward a stable thought chain generation model, a dual-reward model for financial decision enhancement, and fine-tuning of reinforcement learning under dual guidance of PRM and ORM.
01 Initial construction of a stable generative model of the chain of thought
For the complex decision analysis scenarios in the financial domain, we have constructed a basic model with stable thought chain generation capability. The first is the data synthesis of high-quality COT/Answer, which first generates the thinking process based on the question, and then generates the final answer based on the question and the thinking process. With this strategy, the model is able to focus on each stage of the task and generate more coherent reasoning chains and answers.
For different domains (e.g., mathematics, logical reasoning, financial analysis, etc.), we designed specialized data synthesis methods, for example, for financial analysis tasks, we designed an iterative synthesis method to ensure that the analytical process is comprehensive, and then trained based on the XuanYuan 3.0 model using command fine-tuning, using a unified thinking process answer output format (we will also disclose the coarse-grained thinking nodes this time), and at the same time focus on constructing a larger number of long text data to enhance the model's ability to process long contexts, so that it can "first generate a detailed thinking process, and then generate the answer", which provides a good basis for subsequent process-supervised training. This lays a solid foundation for subsequent process-supervised training and reinforcement learning optimization.
02 A dual-reward model for financial decision enhancement
In order to evaluate the performance of the model in financial decision-making scenarios, we designed theTwo complementary reward models, outcome-oriented (ORM) and process-level (PRM). Among them, ORM continues the technical solution of XuanYuan 3.0, which is trained by contrast learning and inverse reinforcement learning; PRM is our innovation for the reasoning process, which focuses on solving the difficulty of evaluating open-ended financial problems (e.g., market analysis, investment decisions, etc.).
For the training data construction of PRM, we adopt different strategies for different scenarios: for questions with definite answers such as risk ratings, we use MCTS-based reverse validation methods; for open-ended financial analysis questions, we annotate them from the dimensions of correctness, necessity, and logic through multiple large models, and we solve the data imbalance problem through downsampling and active learning. During training, PRM uses supervised fine-tuning to optimize the model by scoring each thinking step.03 Reinforcement Learning Fine-Tuning with Dual-Guidance of PRM and ORMIn the reinforcement learning phase, we use the PPO algorithm for model optimization, which uses PRM and ORM as the reward signals. For the thinking process between and , PRM is used to score each thinking step, so that errors in the thinking path can be detected and corrected in a timely manner; for the answer part, different evaluation strategies are used for different types of questions: rule matching is used to compute rewards for financial questions with definite answers (e.g., risk level assessment), and ORM is used to compute rewards for open-ended questions ( e.g., market analysis) are scored overall using ORM. Techniques such as dynamic KL coefficients and dominance function normalization are simultaneously introduced to stabilize the training process. ThisTraining mechanisms based on double rewards, which not only overcomes the limitations of single-reward models, but also significantly improves the model's reasoning ability in financial decision-making scenarios through stable reinforcement learning training.
As can be seen, the key in the above route is the construction of thought chain data and evaluation of reward models for open problems in financial analysis that are different from mathematics or logic, and we are still still optimizing and iterating, and will continue to explore more effective technical routes.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts




No comments...