
Sesame Releases Conversational Speech Model CSM: Making AI Voice Interaction More Natural

A recent blog post by Brendan Iribe, Ankit Kumar, and the Sesame team describes the company's latest research in the field of conversational speech generation, the Conversational Speech Model (CSM). CSM). The model is designed to address the lack of emotion and naturalness in current voice assistants, bringing AI voice interactions closer to the human level.
Crossing the "Valley of Terror" in the quest for "voice immersion."
The Sesame team believes that voice is the most intimate communication medium for humans, and contains a wealth of information that goes far beyond the literal meaning. However, existing voice assistants often lack emotional expression and have a flat tone, making it difficult to establish a deep connection with users. When using such voice assistants for a long period of time, users will not only feel disappointed, but even tired.
To solve this problem, Sesame has developed the concept of "voice presence", which means that voice interactions feel real, understood and valued, and the CSM model is a key step towards this goal. Sesame team emphasizes that they are not just creating a tool, they are building a conversation partner that builds a trusting relationship with the user.
Realizing "voice presence" is not an easy task, and requires a combination of the following key elements:
- Emotional Intelligence: Recognize and respond to changes in user's mood.
- Dialogue Dynamics: Grasp natural conversational rhythms, including rate of speech, pauses, interruptions, and emphasis.
- Situational Awareness: Adjust tone and expression to different conversational scenarios.
- Consistent personality: Maintain the consistency and reliability of the AI assistant's personality.
CSM model: single-stage, multimodal, more efficient
To achieve these goals, Sesame's team proposed a new conversational speech model, CSM, which uses an end-to-end multimodal learning framework to generate more natural and coherent speech using conversational history.
Unlike traditional text-to-speech (TTS) models, the CSM model operates directly on RVQ (residual vector quantization) tokens. This design avoids the information bottleneck that may be caused by semantic tokens in traditional TTS models, thus better capturing the nuances in speech.
CSM The architectural design of the model is also quite impressive. It employs two autoregressive Transformers:
- Multimodal backbone: Processing interleaved text and audio information to predict layer zero of the RVQ codebook.
- Audio decoder: Using a different linear header for each codebook, the remaining N-1 layers are predicted to reconstruct the speech.
This design allows the decoder to be much smaller than the trunk, thus enabling low-latency speech generation while keeping the model end-to-end.

CSM model inference process
In addition, in order to solve the memory bottleneck problem during the training process, the Sesame team proposed a computational apportionment scheme. This scheme trains the audio decoder only on a random subset of audio frames, which significantly reduces the memory consumption without affecting the model performance.

Apportionment of the training process
Experimental results: close to human level, but still a gap
The Sesame team trained the CSM model on a dataset containing about 1 million hours of English audio and used a variety of metrics to thoroughly evaluate the model performance.
The evaluation results show that the CSM model is close to the human level in the traditional metrics of Word Error Rate (WER) and Speaker Similarity (SIM).
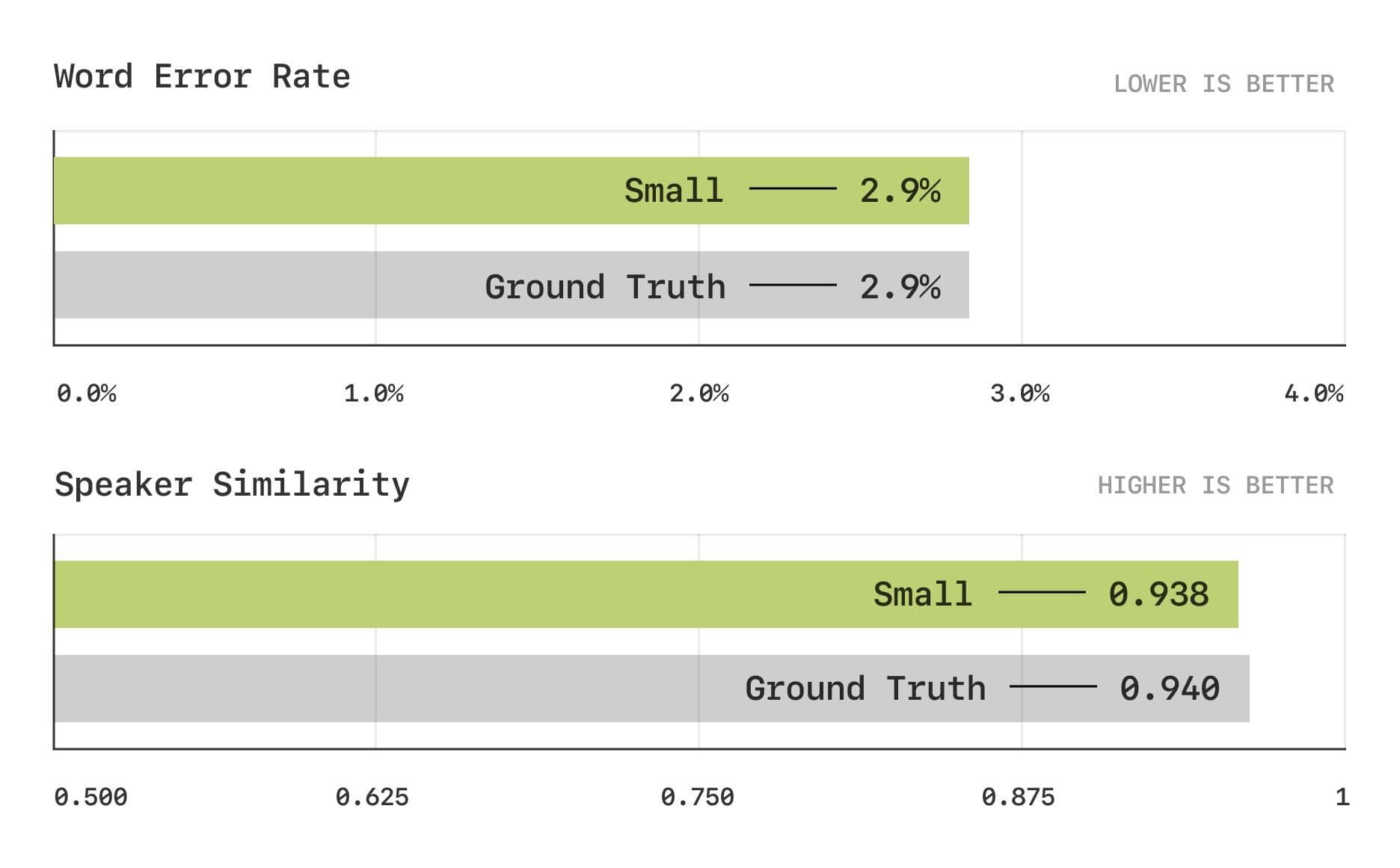
Word error rate and speaker similarity test
In order to more deeply evaluate the model's capabilities in pronunciation and context understanding, the Sesame team also introduced a new set of speech transcription-based benchmark tests, including homophone disambiguation and pronunciation consistency tests. The results show that the CSM model performs well in these areas as well, and that performance improves as model size increases.
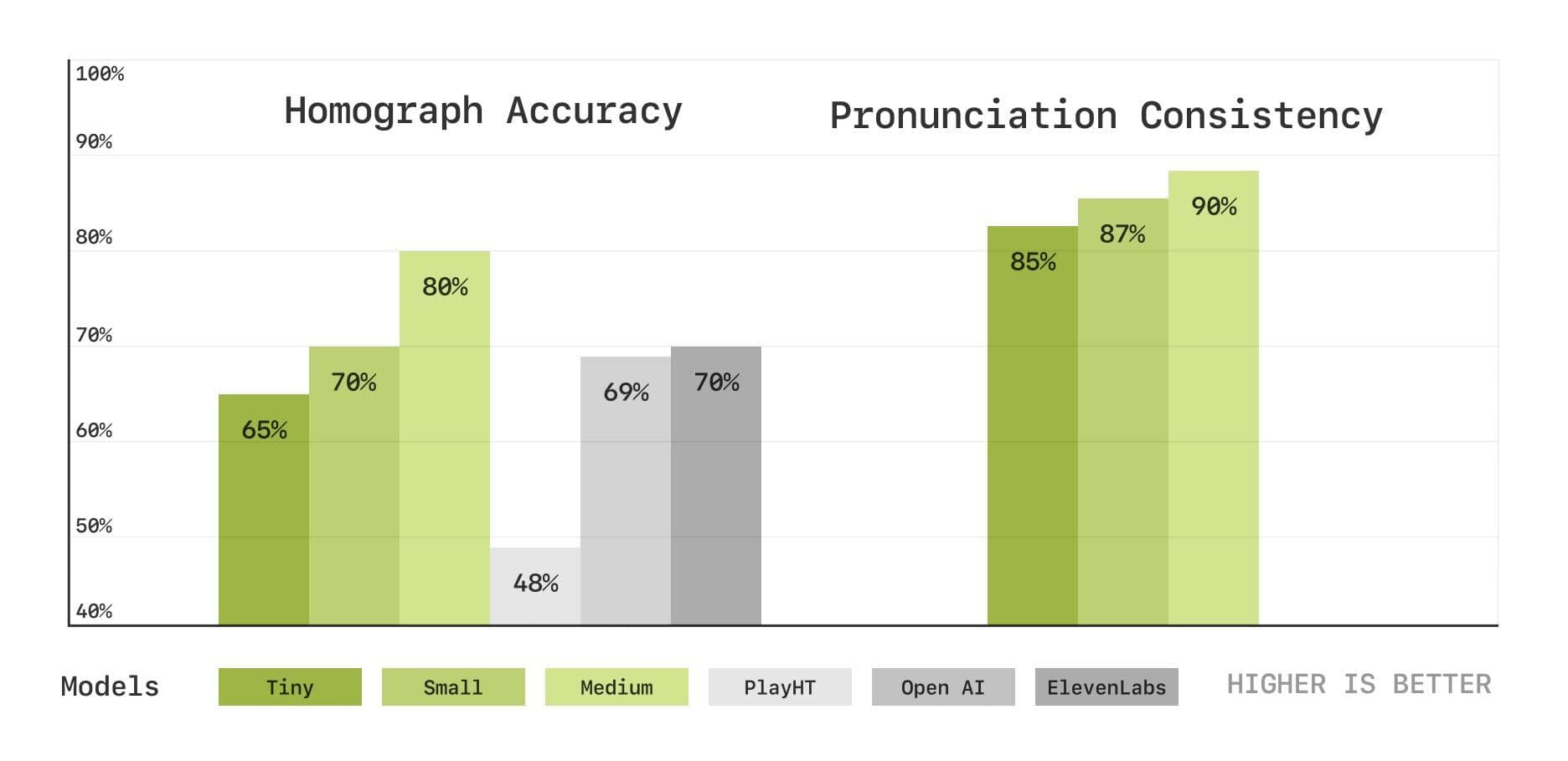
Homophone Disambiguation and Pronunciation Consistency Tests
However, there is still a gap between the CSM model and real human speech in terms of subjective assessment.The Sesame team conducted two Comparative Mean Opinion Score (CMOS) studies using the Expresso dataset. The results showed that without context, listeners had comparable preferences for CSM-generated speech and real human speech. However, when provided with contextual information, listeners significantly preferred real human speech. This suggests that there is still room for improvement in the CSM model in capturing subtle rhythmic changes in dialog.
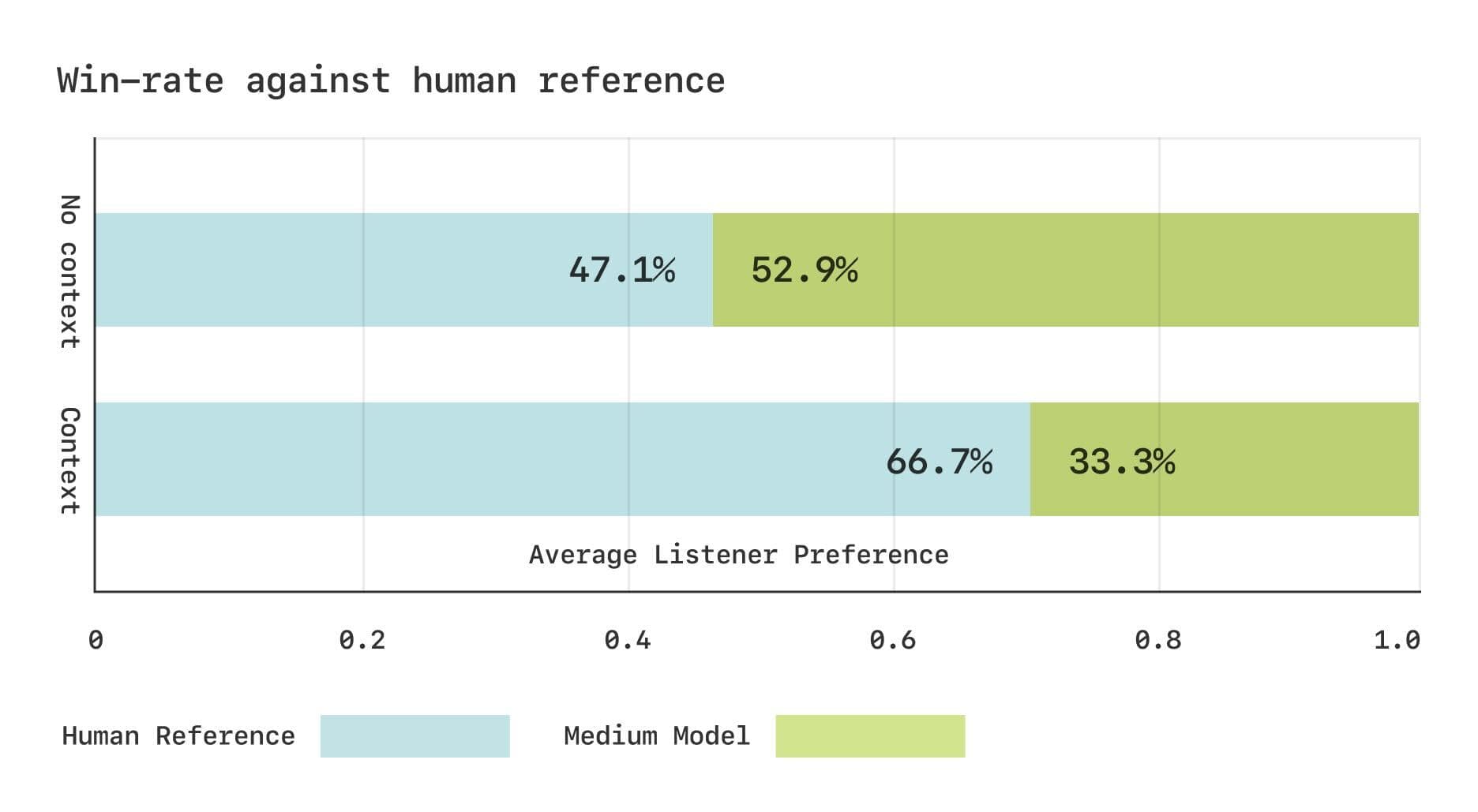
Subjective assessment results for the Expresso dataset
Open Source Sharing, Future Prospects
In the spirit of open source, the Sesame team plans to open-source key components of the CSM model to foster mutual community development.
https://github.com/SesameAILabs/csm
Although the CSM model has made significant progress, there are still some limitations, such as supporting mainly English, and the multilingual capability needs to be improved. the Sesame team said that in the future, they will continue to expand the model size, increase the capacity of the dataset, expand the language support, and explore the use of pre-training language modeling to further improve the performance of the CSM model. the Sesame team is confident in the future direction of their research. The Sesame team is confident that the future of AI dialog lies in full duplex models, i.e., models that can implicitly learn dialog dynamics from data.
Overall, the CSM model released by Sesame is an important step forward in the field of conversational speech generation, providing new ideas for building more natural and emotional AI voice interactions. Although there is still room for improvement, the Sesame team's open source spirit and plans for the future are worth looking forward to.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...