
How to choose the best Embedding model for a RAG application


Vector Embedding is the core of current Retrieval Augmented Generation (RAG) applications. They capture semantic information of data objects (e.g., text, images, etc.) and represent them as arrays of numbers. In current generative AI applications, these vector Embedding are usually generated by Embedding models. How to choose the right Embedding model for a RAG application? Overall, it depends on the specific use case as well as the specific requirements. Next, let's break down the steps to look at each one individually.
01. Identify specific use cases
We consider the following questions based on RAG application requirements:
First, is the generic model sufficient for the needs?
Second, are there specific needs? For example, modality (e.g., text or image only, for multimodal Embedding choices see theHow to choose the right Embedding model"), specific fields (e.g., law, medicine, etc.)
In most cases, a generic model is usually chosen for the desired modes.
02. Selection of generic models
How to choose a generalized model?The Massive Text Embedding Benchmark (MTEB) leaderboard in HuggingFace lists a variety of current proprietary and open-source text Embedding models, and for each Embedding model, the MTEB lists a variety of metrics, including model parameters, memory, Embedding dimensions, maximum number of tokens, and its score in tasks such as retrieval and summarization.
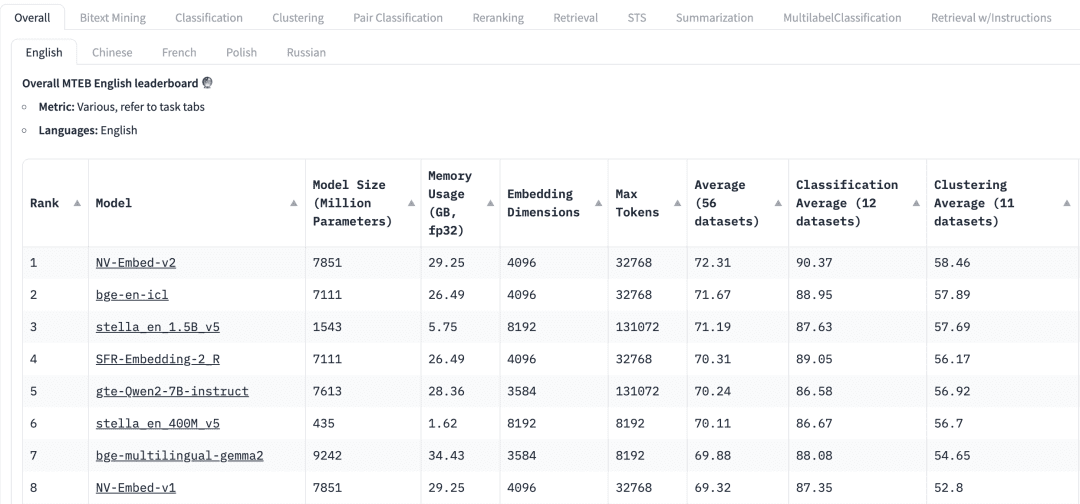
The following factors need to be considered when selecting an Embedding model for a RAG application:
mandatesAt the top of the MTEB Leaderboard, we will see various task tabs. For a RAG application, we may need to focus more on the "Retrieve" task, where we can choose to Retrial This tab.
multilingualism: Based on the language of the dataset in which the RAG is applied to select the Embedding model for the corresponding language.
score: Indicates the performance of the model on a specific benchmark dataset or multiple benchmark datasets. Depending on the task, different evaluation metrics are used. Typically, these metrics take values ranging from 0 to 1, with higher values indicating better performance.
Model size and memory usage: These metrics give us an idea of the computational resources required to run the model. While retrieval performance improves with model size, it is important to note that model size also directly affects latency. In addition, larger models may be overfitted with low generalization performance and thus perform poorly in production. Therefore, we need to seek a balance between performance and latency in a production environment. In general, we can start with a small, lightweight model and build the RAG application quickly first. After the underlying process of the application is working properly, we can switch to a larger, higher-performance model to further optimize the application.
Embedding dimensions: This is the length of the Embedding vector. While larger Embedding dimensions can capture finer details in the data, the results are not necessarily optimal. For example, do we really need 8192 dimensions for document data? Probably not. On the other hand, smaller Embedding dimensions provide faster inference and are more efficient in terms of storage and memory. Therefore, we need to find a good balance between capturing data content and execution efficiency.
Maximum number of tokens: indicates the maximum number of tokens for a single Embedding. For common RAG applications, the better chunk size for Embedding is usually a single paragraph, in which case an Embedding model with a maximum token of 512 should be sufficient. However, in some special cases, we may need a model with a larger number of tokens to handle longer texts.
03. Evaluating models in RAG applications
While we can find generic models from the MTEB leaderboards, we need to treat their results with caution. Keeping in mind that these results are self-reported by the models, it is possible that some models produce scores that inflate their performance because they may have included the MTEB datasets in their training data, which are, after all, publicly available datasets. Also, the datasets that the models use for benchmarking may not accurately represent the data used in our application. Therefore, we need to evaluate Embedding models on our own datasets.
3.1 Data sets
We can generate a small tagged dataset from the data used by the RAG application. Let's take the following dataset as an example.
| Language | Description |
|---|---|
| C/C++ | A general-purpose programming language known for its performance and efficiency. It provides low-level memory manipulation capabilities and is widely used in system/software development, game development, and applications requiring high performance. |
| Java | A versatile, object-oriented programming language designed to have as few implementation dependencies as possible. It is widely used for building It is widely used for building enterprise-scale applications, mobile applications (especially Android), and web applications due to its portability and robustness. |
| Python | It supports multiple programming paradigms and is widely used in web development, data analysis, artificial intelligence, scientific computing, and automation. It supports multiple programming paradigms and is widely used in web development, data analysis, artificial intelligence, scientific computing, and automation. |
| JavaScript | A high-level, dynamic programming language primarily used for creating interactive and dynamic content on the web. It is an essential technology for front-end web development and is increasingly used on the server-side with environments like Node.js. |
| C# | It is used for developing a wide range of applications, including web, desktop, mobile, and games, particularly within the Microsoft ecosystem. It is used for developing a wide range of applications, including web, desktop, mobile, and games, particularly within the Microsoft ecosystem. |
| SQL | It is essential for querying, updating, and managing data in databases, and is widely used in data analysis and business intelligence. It is essential for querying, updating, and managing data in databases, and is widely used in data analysis and business intelligence. |
| PHP | It is embedded into HTML and is widely used for building dynamic web pages and applications, with a strong presence in content management systems like WordPress. applications, with a strong presence in content management systems like WordPress. |
| Golang | A statically typed, compiled programming language designed by Google. Known for its simplicity and efficiency, it is used for building scalable and high -performance applications, particularly in cloud services and distributed systems. |
| Rust | A systems programming language focused on safety and concurrency. It provides memory safety without using a garbage collector and is used for building It provides memory safety without using a garbage collector and is used for building reliable and efficient software, particularly in systems programming and web assembly. |
3.2 Creating Embedding
Next, we use thepymilvus[model]For the above dataset generate the corresponding vector Embedding. about the pymilvus[model] For use, see https://milvus.io/blog/introducing-pymilvus-integrations-with-embedding-models.md
def gen_embedding(model_name): openai_ef = model.dense.OpenAIEmbeddingFunction( model_name=model_name, api_key=os.environ["OPENAI_API_KEY"] ) docs_embeddings = openai_ef.encode_documents(df['description'].tolist()) return docs_embeddings, openai_ef
Then, the generated Embedding is deposited into the collection of Milvus.
def save_embedding(docs_embeddings, collection_name, dim):
data = [
{"id": i, "vector": docs_embeddings[i].data, "text": row.language}
for i, row in df.iterrows()
]
if milvus_client.has_collection(collection_name=collection_name):
milvus_client.drop_collection(collection_name=collection_name)
milvus_client.create_collection(collection_name=collection_name, dimension=dim)
res = milvus_client.insert(collection_name=collection_name, data=data)
3.3 Queries
We define query functions to facilitate the recall for vector Embedding.
def query_results(query, collection_name, openai_ef):
query_embeddings = openai_ef.encode_queries(query)
res = milvus_client.search(
collection_name=collection_name,
data=query_embeddings,
limit=4,
output_fields=["text"],
)
result = {}
for items in res:
for item in items:
result[item.get("entity").get("text")] = item.get('distance')
return result
3.4 Evaluating Embedding Model Performance
We use two Embedding models from OpenAI.text-embedding-3-small cap (a poem) text-embedding-3-large, for the following two queries are compared. There are many evaluation metrics such as accuracy, recall, MRR, MAP, etc. Here, we use accuracy and recall.
Precision Evaluates the percentage of truly relevant content in the search results, i.e., how many of the returned results are relevant to the search query.
Precision = TP / (TP + FP)
In this case, the True Positives (TP) are those that are truly relevant to the query, while the False Positives (FP) are those that are not relevant in the search results.
Recall evaluates the amount of relevant content successfully retrieved from the entire dataset.
Recall = TP / (TP + FN)
False Negatives (FN) refers to all relevant items that are not included in the final result set.
For a more detailed explanation of these two concepts
Query 1::auto garbage collection
Related items: Java, Python, JavaScript, Golang
| Rank | text-embedding-3-small | text-embedding-3-large |
|---|---|---|
| 1 | ❎ Rust | ❎ Rust |
| 2 | ❎ C/C++ | ❎ C/C++ |
| 3 | ✅ Golang | ✅ Java |
| 4 | ✅ Java | ✅ Golang |
| Precision | 0.50 | 0.50 |
| Recall | 0.50 | 0.50 |
Query 2::suite for web backend server development
Related items: Java, JavaScript, PHP, Python (Answers include subjective judgment)
| Rank | text-embedding-3-small | text-embedding-3-large |
|---|---|---|
| 1 | ✅ PHP | ✅ JavaScript |
| 2 | ✅ Java | ✅ Java |
| 3 | ✅ JavaScript | ✅ PHP |
| 4 | ❎ C# | ✅Python |
| Precision | 0.75 | 1.0 |
| Recall | 0.75 | 1.0 |
In both queries, we compared the two Embedding models by accuracy and recall text-embedding-3-small cap (a poem) text-embedding-3-large The first step is to increase the number of data objects in the dataset and the number of queries. We can use this as a starting point to increase the number of data objects in the dataset as well as the number of queries so that the Embedding model can be evaluated more effectively.
04. Summary
In Retrieval Augmented Generation (RAG) applications, the selection of appropriate vector Embedding models is crucial. In this paper, we illustrate that after selecting a generic model from MTEB from the actual business requirements, the accuracy and recall are used to test the model based on a business-specific dataset, so as to select the most suitable Embedding model, which in turn effectively improves the recall accuracy of RAG applications.
The full code is available via download
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...