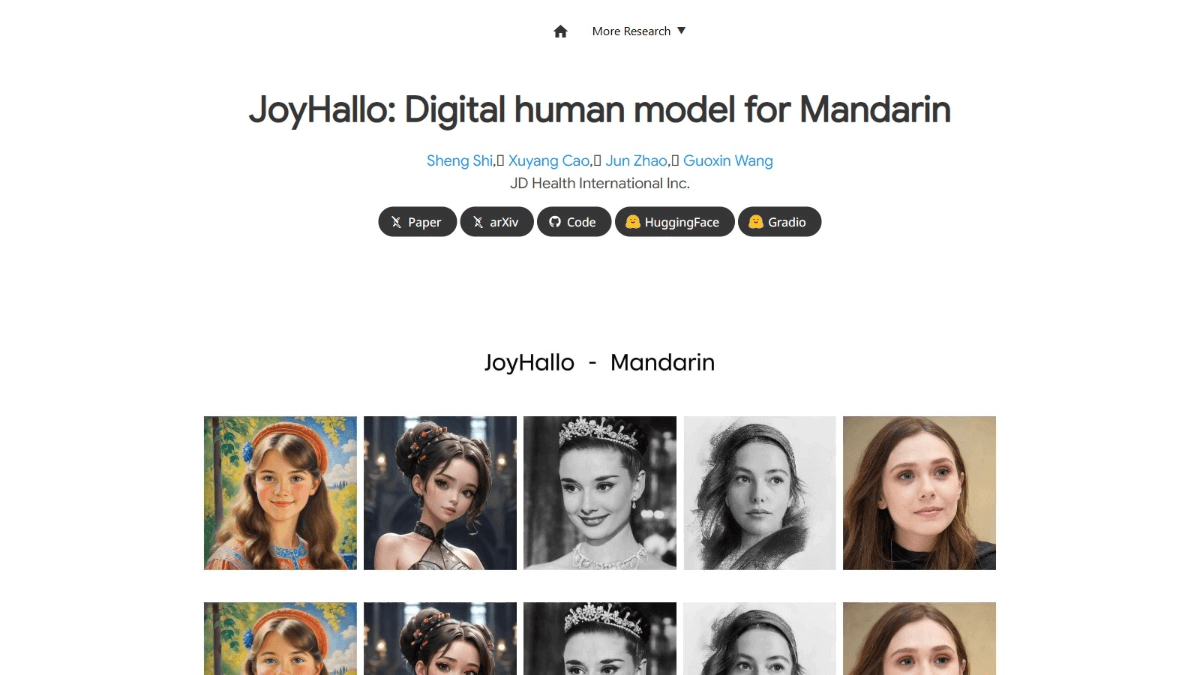
RolmOCR: Document OCR Model for Recognizing Handwritten and Slanted Characters

General Introduction
RolmOCR is an open source Optical Character Recognition (OCR) tool developed by the Reducto AI team, based on the Qwen2.5-VL-7B visual language model. It can extract text from images and PDF files faster than similar tools. olmOCR Faster and with a lower memory footprint.RolmOCR does not rely on PDF metadata, simplifying processing while supporting a wide range of document types, including handwritten notes and academic papers. It is released under the Apache 2.0 license and is free for individuals and developers to use, modify, or integrate.The Reducto team built this tool by updating the model and optimizing the training data with the goal of making document digitization more efficient.


Function List
- Fast Text Extraction: Extract text from images and PDFs with fast processing speed for large number of documents.
- Supports a wide range of documents: recognizes handwritten notes, printed documents and complex forms.
- Open source and free: open under the Apache 2.0 license, the code can be freely downloaded and adapted.
- Low memory footprint: compared to olmOCR More resource-efficient and low computer requirements when running.
- No metadata required: process the original document directly without relying on additional information from the PDF.
- Enhanced Skewed Document Recognition: 15% in the training data is rotated to improve the adaptation to non-positively angled documents.
- Based on the latest model: adopts Qwen2.5-VL-7B to improve recognition accuracy and efficiency.
Using Help
RolmOCR is an open source tool that runs mainly through code and is suitable for users with a basic knowledge of programming. The following is a detailed installation and usage guide.
Installation process
- Checking the Python Environment
RolmOCR requires Python 3.8 or higher. Open the command line and typepython --versionCheck the version. If you don't have it installed, go to the Python website and download and install it. - Installing the vLLM Framework
RolmOCR Usage vLLM Run the model. Enter at the command line:
pip install vllm
After the installation is complete, set the environment variables:
export VLLM_USE_V1=1
This ensures that vLLM works properly.
- Download RolmOCR model
The model files are hosted on Hugging Face. Go to https://huggingface.co/reducto/RolmOCR and click on "Files and versions" to download. Or pull it from the command line:
git clone https://huggingface.co/reducto/RolmOCR
- Starting Local Services
Go to the downloaded model folder and run it:
vllm serve reducto/RolmOCR
When the service starts, the default address is http://localhost:8000/v1. Keep the command line window open.
Usage
RolmOCR extracts text via API calls. Here are the steps.
Prepare the document
Prepare the file to be recognized, e.g. an image (PNG/JPG) or a PDF, assuming the file path is test_doc.pngThe
Calling the API to extract text
Write a script in Python to convert the file to base64 encoding and send it to RolmOCR. the sample code is as follows:
from openai import OpenAI
import base64
# 连接本地服务
client = OpenAI(api_key="123", base_url="http://localhost:8000/v1")
model = "reducto/RolmOCR-7b"
# 图片转 base64
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode("utf-8")
# 调用 RolmOCR 提取文字
def ocr_page_with_rolm(img_base64):
response = client.chat.completions.create(
model=model,
messages=[
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{img_base64}"}},
{"type": "text", "text": "把这张图片里的文字提取出来,像人读的那样自然返回。"}
]
}
],
temperature=0.2,
max_tokens=4096
)
return response.choices[0].message.content
# 运行示例
test_img_path = "test_doc.png"
img_base64 = encode_image(test_img_path)
result = ocr_page_with_rolm(img_base64)
print(result)
save as (a file) ocr_test.py, and then run:
python ocr_test.py
The program returns the extracted text, for example:
会议记录
2025年4月7日
- 项目计划讨论
- 准备相关资料
batch file
To handle multiple files, rewrite the code. Put the file paths into a list and call it in a loop:
file_paths = ["doc1.png", "doc2.png", "doc3.png"]
for path in file_paths:
img_base64 = encode_image(path)
result = ocr_page_with_rolm(img_base64)
print(f"{path} 的结果:\n{result}\n")
Featured Function Operation
- handwriting recognition
RolmOCR recognizes handwriting. For example, a note that says "Deepseek Coder" is accurately output without being mistaken for "OCLM". After uploading the image, the results are sorted in natural order. - Skewed Document Processing
The training data 15% is rotated so that it is more adaptive to skewed documents. For example, a skewed scan, the text is still extracted correctly. - Low memory operation
No dependency on metadata, shorter hint lengths, and less graphics memory (VRAM) used for processing. Suitable for computers with lower configurations.
caveat
- service interruption: Do not close the command line window after starting the service or the API will stop.
- lack of memory: If your computer does not have enough memory, you can adjust the vLLM parameter, such as
per_device_train_batch_size, reducing resource requirements. - limitations: RolmOCR may miss small text with low contrast or incomplete recognition of complex tables without metadata. It is recommended to optimize the image quality and try again.
- Layout boxes are not supported: Unlike Reducto's commercial API, RolmOCR cannot output bounding boxes for text.
With these steps, users can easily install and use RolmOCR to extract text from documents quickly.
application scenario
- academic research
Students and researchers can use RolmOCR to scan handwritten notes or older documents into electronic text for easy organization and searching. - Enterprise Document Processing
Companies can use it to extract text from contracts and envelopes, enter it into the system, and reduce manual work. - Multi-language support
Handle mixed documents in English and Chinese or handwritten letters in French, extracting information quickly and suitable for cross-border communication.
QA
- What is the difference between RolmOCR and olmOCR?
RolmOCR is based on the updated Qwen2.5-VL-7B model, which is faster, has a lower memory footprint, uses no metadata, and is morerobust for skewed documents. - Can it be used offline?
Can. Just download the model and start the local service, no internet connection required. - Does it support form recognition?
Supported, but may miss parts of complex tables without metadata, such as subheadings in academic papers.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...