ReSearch: a Qwen2.5-7B model for enhanced search reasoning (experimental)

General Introduction
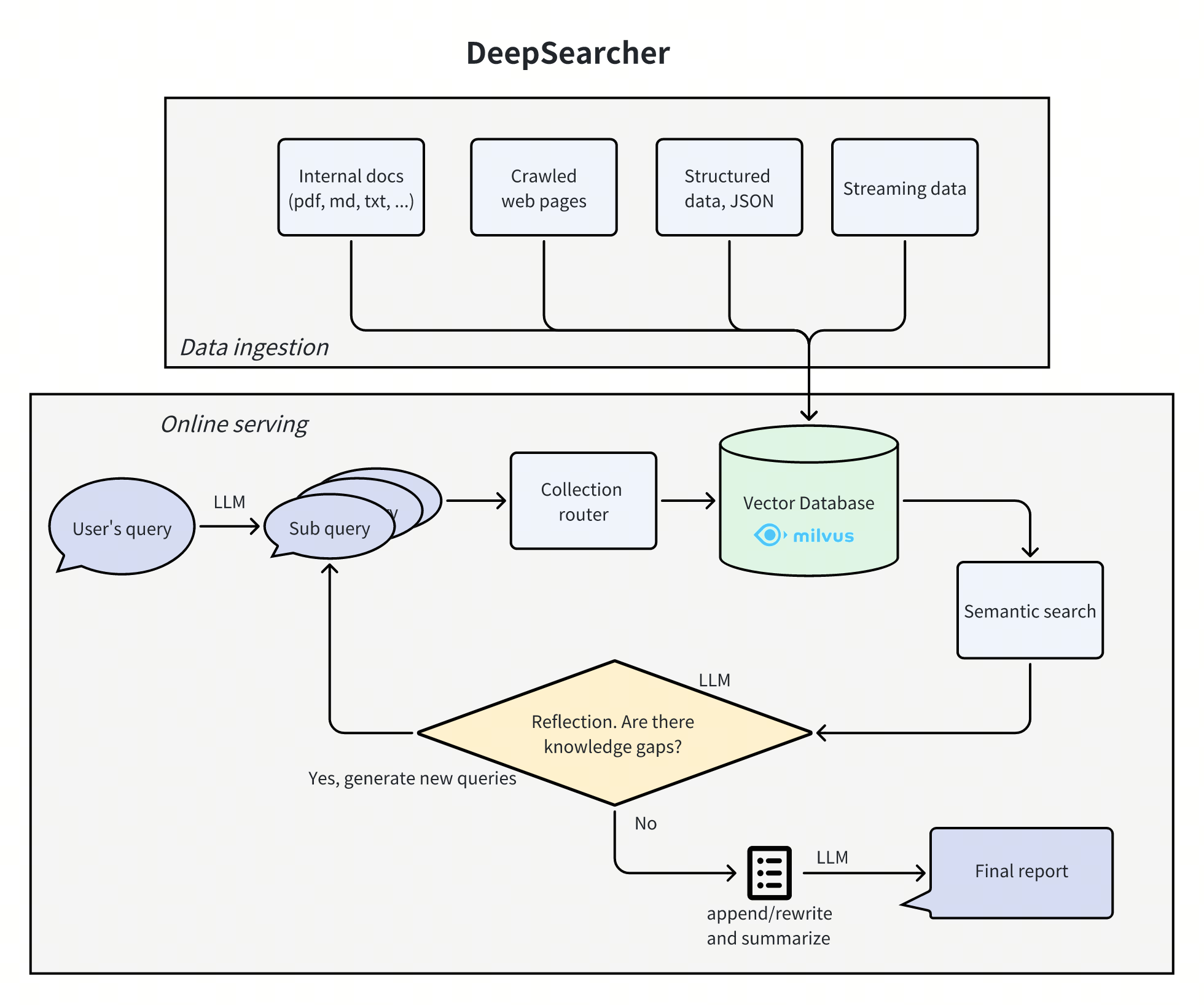
ReSearch is an open source research tool developed by the Agent-RL team to improve the search and inference capabilities of Large Language Models (LLMs) through Reinforcement Learning (RL). Inspired by Deepseek-R1-Zero and OpenAI's Deep Research, ReSearch is based on the Qwen2.5-7B model, trained from scratch using the GRPO (Generalized Reward Policy Optimization) methodology, which allows the model to autonomously invoke the search tool based only on reward signals, without supervised data. ReSearch was validated on the HotpotQA dataset and generalizes to datasets such as Bamboogle and StrategyQA. Hosted on GitHub, the full code and experimental documentation are available for researchers to reproduce or extend the exploration of combining RL and LLM.
-1")
Function List
- Enhanced Learning Training Pipeline: Support for training large models from scratch, complete parameter configuration and reward signal design.
- Search Tool Call: The model can automatically invoke search tools based on the problem to improve the accuracy of complex reasoning tasks.
- Multiple dataset adaptation: After training in HotpotQA, it can be extended to datasets such as Bamboogle, StrategyQA, and so on.
- Performance Evaluation Support: Integrate the FlashRAG environment to quickly test the performance of a model on a development set.
- open source implementation: Provide detailed code and experimental configurations for easy research reproduction and secondary development.
Using Help
Installation process
ReSearch requires a GPU environment and relies on the verl and FlashRAG frameworks. Below are the detailed installation steps:
1. Environmental preparation
- system requirements: Linux (e.g. Ubuntu) is recommended, Windows may have compatibility issues.
- Python version: Requires Python 3.11 or above.
- GPU Configuration: Support for NVIDIA GPUs, install CUDA 12.4 (to match the torch version).
2. Cloning of warehouses
Enter the following command in the terminal:
git clone https://github.com/Agent-RL/ReSearch.git
cd ReSearch
3. Installation of the verl environment
ReSearch is based on verl for reinforcement learning training, the installation steps are as follows:
cd verl
pip3 install -e .
cd ..
- dependency version: torch==2.4.0+cu124, vllm==0.6.3, ray==2.10.0. If there is a conflict, install it manually:
pip install torch==2.4.0+cu124 vllm==0.6.3 ray==2.10.0
4. Installation of the FlashRAG environment
FlashRAG is used to evaluate and RAG Service, installation method:
git clone https://github.com/RUC-AIBox/FlashRAG.git
cd FlashRAG
pip3 install -e .
cd ../ReSearch
5. Downloading pre-trained models
Qwen2.5-7B is used by default, downloaded from Hugging Face:
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-7B
Record the model path and configure it for use later.
Usage
Starting the RAG Service
- Download Pre-Indexed Data: Get the Wikipedia index, corpus, and retrieval model from a FlashRAG document.
- Configuration Services:: Editorial
rag_serving/serving_config.yamlThe GPU IDs are filled in with the retrieval model, index, corpus path, and available GPU IDs. - Operational services::
conda activate flashrag python rag_serving/serving.py --config rag_serving/serving_config.yaml --num_retriever 1 --port 8000Search support is provided once the service is running.
training model
- Prepare data: Download the HotpotQA dataset and run the preprocessing script:
python training/data_preprocess_hpqa.pyThe generated training and development data are saved in parquet format.
- Configuration parameters: Modification
training/run.shThe following are some of the features that you can use to set up the model path, search URL, data path, etc. - priming training::
conda activate verl bash training/run.sh --actor_model_path /path/to/Qwen2.5-7B --search_url http://localhost:8000 --train_data_path data/train.parquet --dev_data_path data/dev.parquet --save_path runs/- Single node 8 GPU training, multiple nodes require ray tuning.
assessment model
- Starting the modeling service: After training, the model is deployed using SGLang:
python3 -m sglang.launch_server --served-model-name research --model-path runs/trained_model --tp 2 --context-length 8192 --port 80 - Operational assessment::
python evaluation/run_eval.py --config_path evaluation/eval_config.yaml --method_name research --split dev --dataset_name hotpotqa- The results are saved to the
evaluation/results/, support for switching datasets (e.g. Bamboogle).
- The results are saved to the
Featured Function Operation
- Search Tool Call::
- After training, the model can automatically determine whether to invoke the search tool. For example, enter "How many moons does Jupiter have?":
python inference.py --model_path runs/trained_model --question "How many moons does Jupiter have?"Example output:
Jupiter has 95 known moons as of 2025.The - Process: The model generates a search query based on the question and calls the RAG service to get the information and then reason about the answer.
- After training, the model can automatically determine whether to invoke the search tool. For example, enter "How many moons does Jupiter have?":
- Cross-dataset generalization::
- Testing model performance on StrategyQA:
python evaluation/run_eval.py --config_path evaluation/eval_config.yaml --method_name research --split dev --dataset_name strategyqaThe output contains the reasoning process and the answer, verifying the generalization ability.
- Testing model performance on StrategyQA:
caveat
- hardware requirement: 24GB of video memory or more for training, 16GB for evaluation.
- Log Monitoring: Use TensorBoard to view training progress:
tensorboard --logdir runs/ - troubleshooting: If you get an error, check the dependency version or check GitHub Issues.
By doing so, users can fully reproduce ReSearch experiments and explore the combination of reinforcement learning and large models.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...