Reader API: Web page content extraction tool, HTML to Markdown format conversion

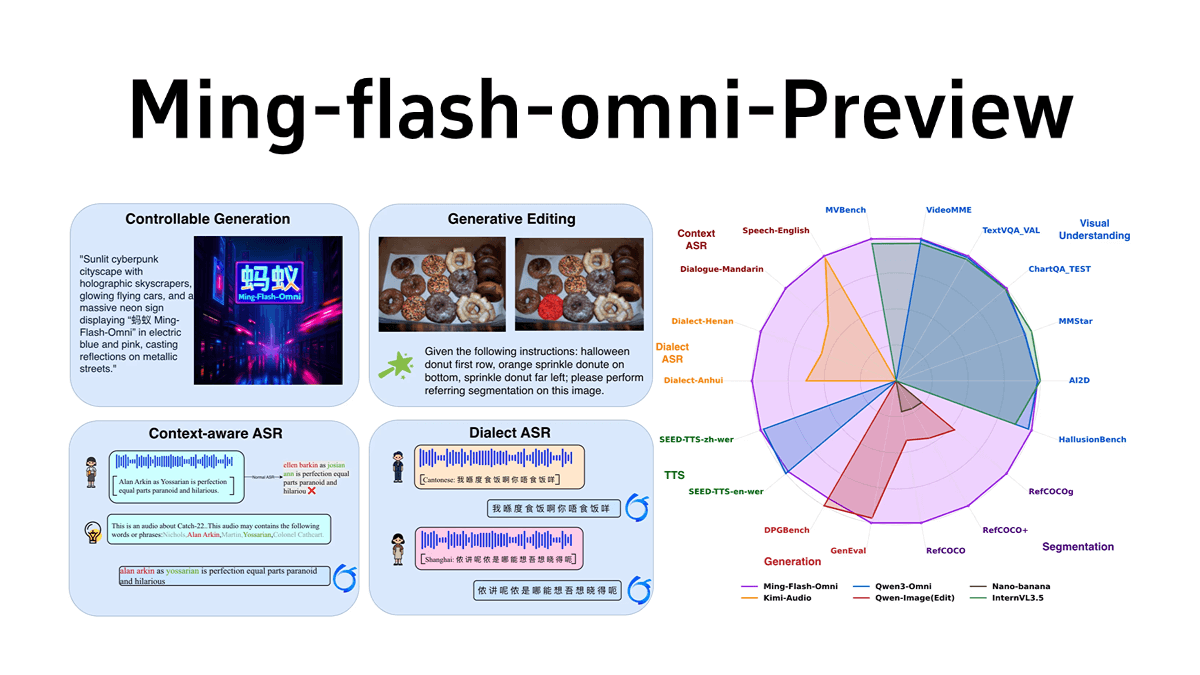
General Introduction
Jina AI's Reader project is an open source tool (Reader open source address), which can take any URL by adding the prefix https://r.jina.ai/转换成适合大型语言模型(Large Language Models, LLM) to the input format, supporting features such as dynamic streaming mode and image reading.
Users can easily capture the core content of web pages and convert it into clean, suitable text for LLM processing. The tool not only supports web page text, but also handles images and PDF files, automatically adding the necessary tags and formatting so that LLM can understand and process the content more efficiently. The project runs with Node v18 and Firebase CLI and is available under the Apache 2.0 license.

Function List
- Web Content Extraction: Convert any URL to LLM-friendly text format.
- image recognition: Automatically generates descriptive tags for images in web pages.
- PDF reading: Supports reading PDF files from any URL and converting them to text suitable for LLM.
- search function: Get the latest information from the web and convert it into LLM-friendly format by prefixing the query with "s.jina.ai".
- High concurrency and reliability: Provides high accessibility and reliability to support large numbers of concurrent requests.
Using Help
Installation and use
Jina AI Reader does not require installation, users just need to prefix the URL with "r.jina.ai". For example, to convert the URL "https://en.wikipedia.org/wiki/Artificial_intelligence" to an LLM-friendly input format, simply use the following URL:
https://r.jina.ai/https://en.wikipedia.org/wiki/Artificial_intelligence
Similarly, to perform a web search and get LLM-friendly results, prefix the query with "s.jina.ai", for example:
https://s.jina.ai/Who%20will%20win%202024%20US%20presidential%20election%3F
Functional operation flow
- Web Content Extraction::
- Enter the URL in your browser with a prefix, such as "https://r.jina.ai/https://example.com".
- Press the Enter key and Jina AI Reader will automatically extract the web page content and convert it to LLM-friendly text format.
- The extracted content will be displayed in the browser and the user can copy it directly or process it further.
- image recognition::
- Jina AI Reader automatically generates descriptive tags for the images in a web page when extracting its content.
- These tags will be used as alt attributes of the image to facilitate LLM's understanding of the image content during processing.
- PDF reading::
- Enter the PDF URL with a prefix, such as "https://r.jina.ai/https://example.com/document.pdf".
- Jina AI Reader will automatically read PDF content and convert it to LLM-friendly text format.
- The converted content will be displayed in the browser and the user can copy it directly or process it further.
- search function::
- Add the prefix "s.jina.ai" to the query, e.g. "https://s.jina.ai/your+query".
- Press the Enter key and Jina AI Reader will fetch the latest information from the web and convert it into LLM-friendly text format.
- The search results will be displayed in the browser and the user can copy them directly or process them further.
Advanced Settings
- Image description tags: By default, the image description tag feature is turned off. Users can enable it by setting "x-with-generated-alt: true" in the request header.
- Proxies and Cookies: Users can set proxies and cookies in the request header to use Jina AI Reader in a specific context.
streaming mode
To process content as it becomes available, set the request header to stream mode. This minimizes the time it takes to receive the first byte. example in curl:
curl -H "Accept: text/event-stream" https://r.jina.ai/https://example.com
Recommend another html to markdown tool
https://markdowndown.vercel.app/
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...