
RAGFlow: an open source RAG engine based on deep document understanding, providing efficient retrieval-enhanced generation workflows

General Introduction
RAGFlow is an open source Retrieval Augmented Generation (RAG) engine based on deep document understanding technology. It provides organizations of all sizes with an efficient RAG Workflows, incorporating Large Language Modeling (LLM), are capable of delivering real-world question and answer capabilities based on complex formatted data.RAGFlow supports a wide range of data sources, including documents, slides, spreadsheets, text, images, and structured data, to ensure that valuable information can be extracted from massive amounts of data. Its key features include templated chunking, reduced phantom referencing, and compatibility with heterogeneous data sources.

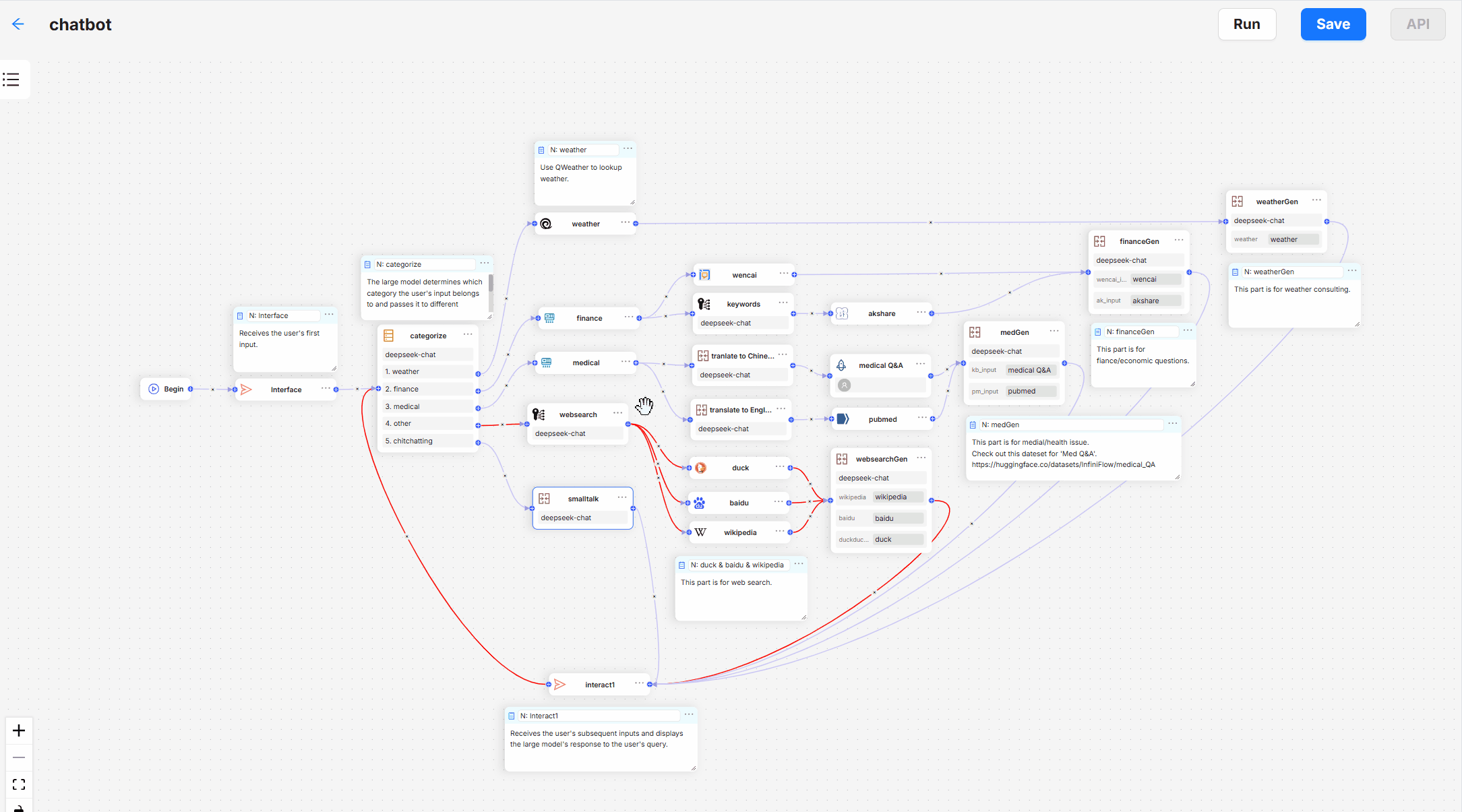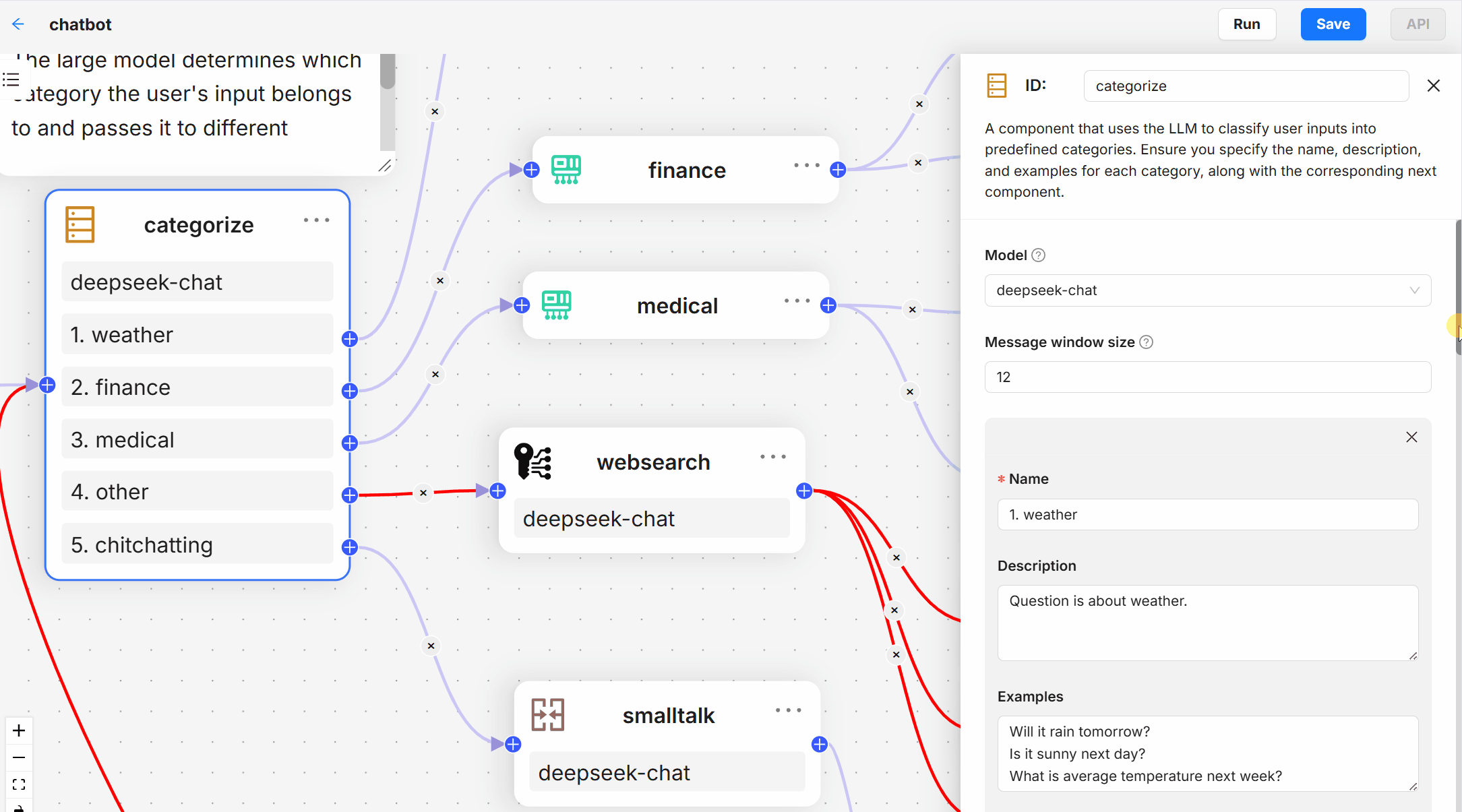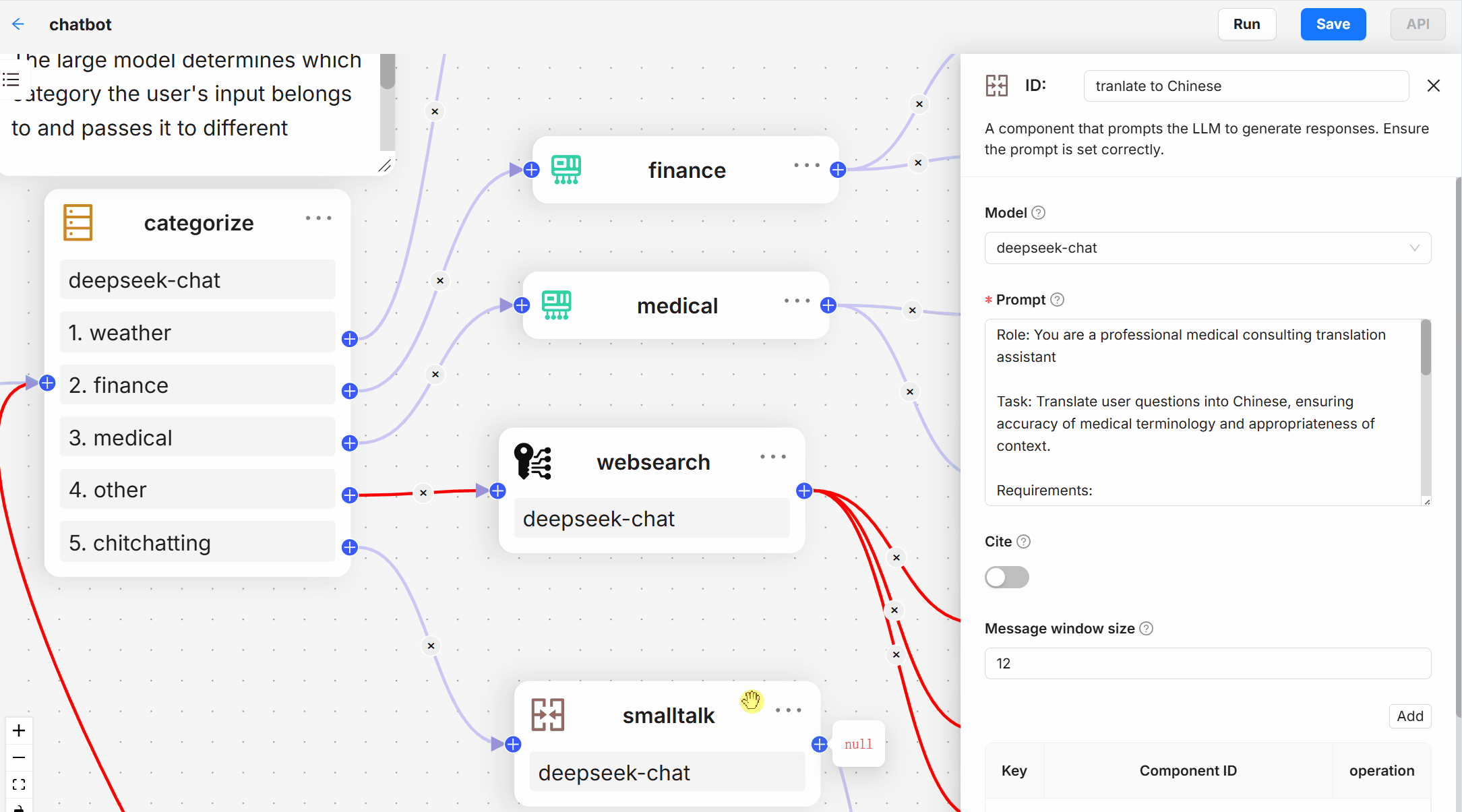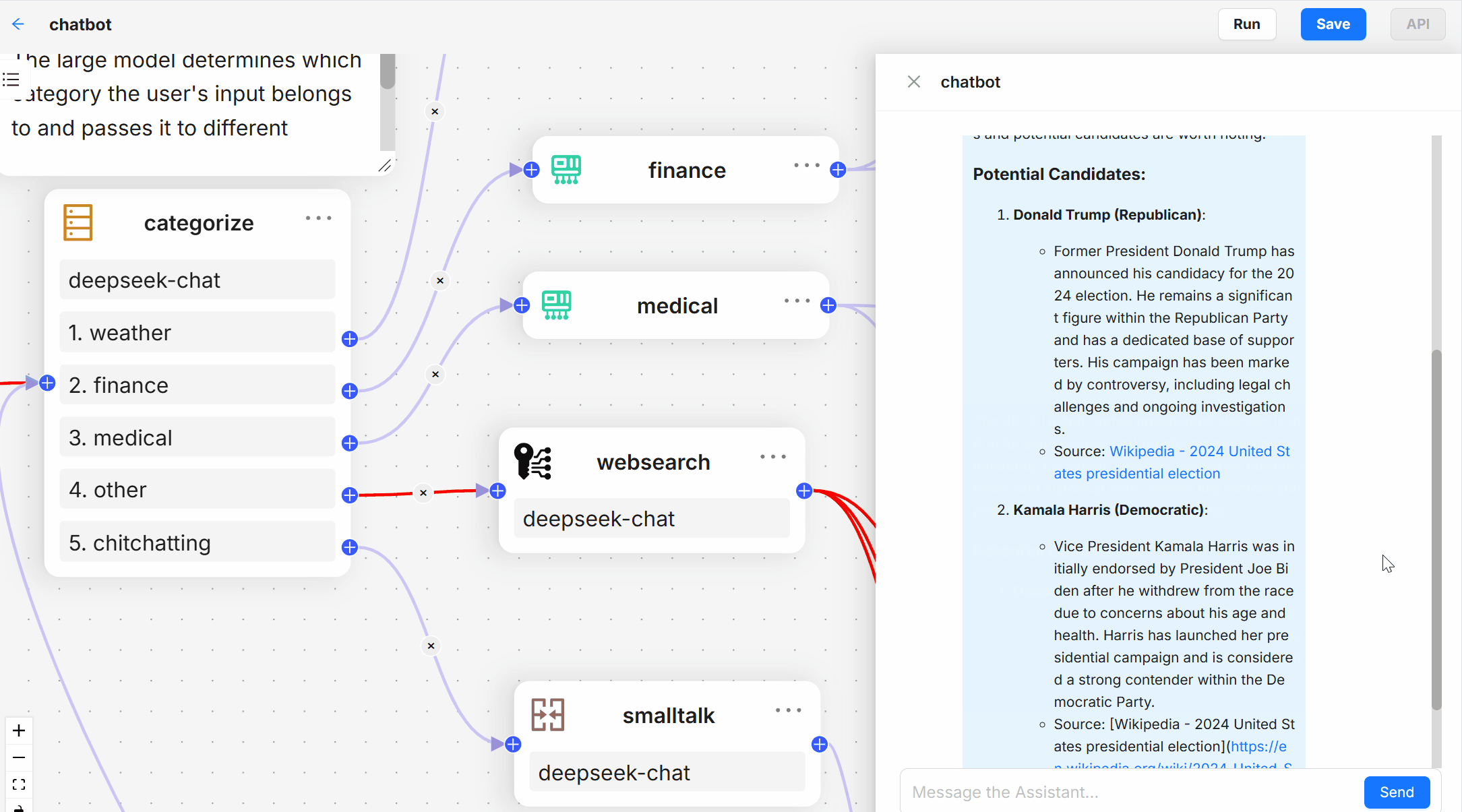
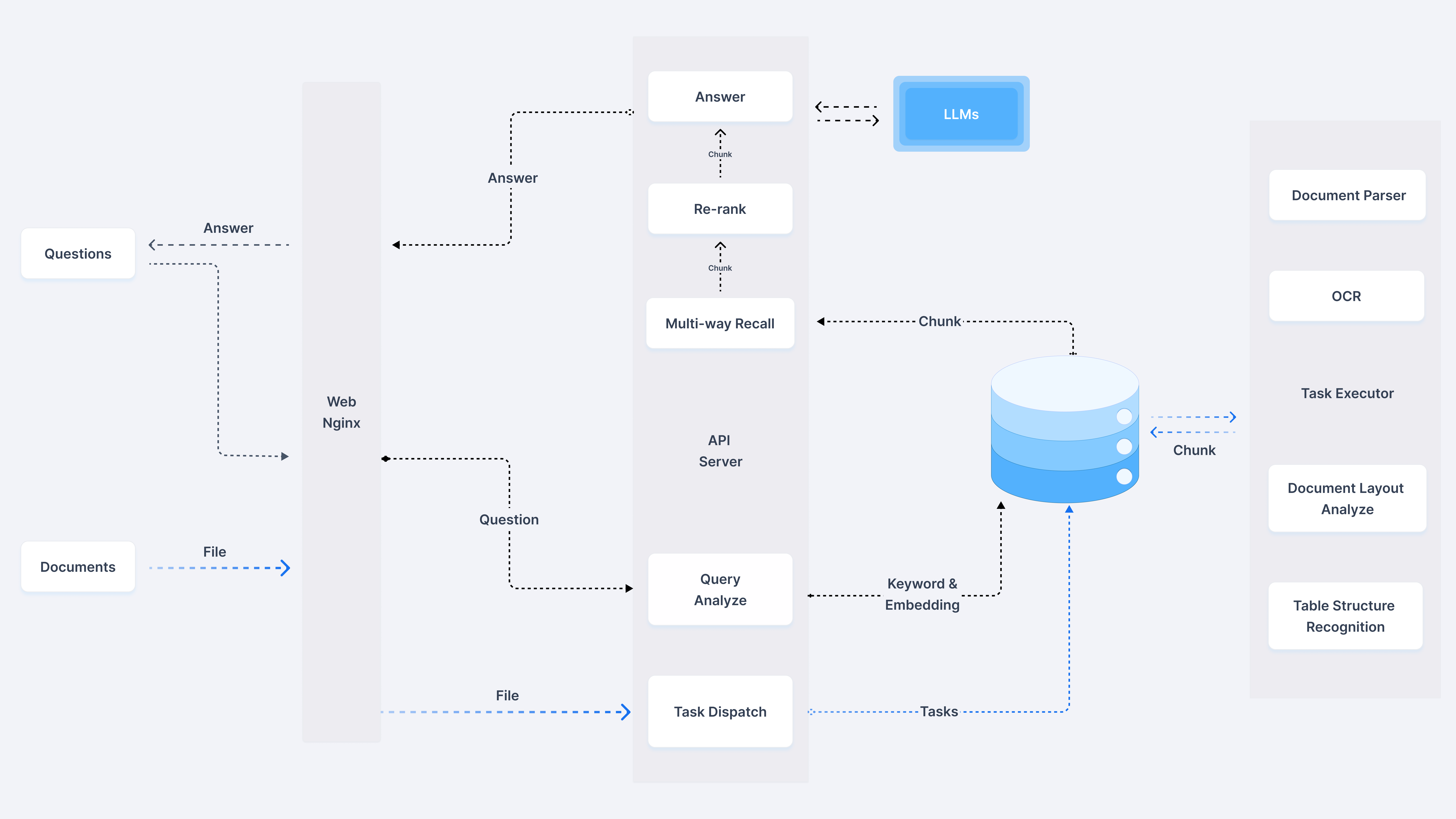
Function List
- Deep Documentation Understanding: Knowledge extraction based on unstructured data in complex formats.
- Templated chunking: A wide range of template options are available, intelligent and open to interpretation.
- Citation Visualization: Supports text chunking visualization for easy manual intervention and quick viewing of key citations.
- Compatible with multiple data sources: Supports Word, slides, Excel, text, images, scanned documents, structured data, web pages, etc.
- Automating RAG workflows: Smooth RAG orchestration for individuals and large organizations, with support for multiple recalls and reordering.
- Intuitive API: Facilitate seamless integration with business systems.
Using Help
Installation process
- system requirements::
- CPU: at least 4 cores
- Memory: at least 16GB
- Hard disk: at least 50GB
- Docker: version 24.0.0 and above
- Docker Compose: version v2.26.1 and above
- Installing Docker::
- Windows, Mac or Linux users can refer to the Docker installation guide.
- Cloning the RAGFlow repository::
git clone https://github.com/infiniflow/ragflow.git
cd ragflow
- Building a Docker image::
- Does not contain a mirror of the embedded model:
docker build -t ragflow .- Contains a mirror image of the embedded model:
docker build -f Dockerfile.deps -t ragflow . - Starting services::
docker-compose up
Guidelines for use
- configure::
- exist
confdirectory to modify the configuration file, set the data source path, model parameters, etc.
- exist
- Starting services::
- After starting the service using the above command, you can interact with it through the API.
- Main Functions::
- Document Upload: Uploads documents to be processed to a specified directory.
- data processing: The system automatically chunks, parses and extracts knowledge from documents.
- question and answer system: Send a question through the API and the system generates an answer based on the content of the document and provides a citation.
- sample operation (computing)::
- Upload a Word document:
bash
curl -F "file=@/path/to/document.docx" http://localhost:8000/upload - Question:
bash
curl -X POST -H "Content-Type: application/json" -d '{"question": "文档的主要内容是什么?"}' http://localhost:8000/ask
- Upload a Word document:
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...