Qwen2.5-1M: An Open Source Qwen Model with Support for 1 Million Tokens Contexts

1. Introduction
Two months ago, the Qwen team upgraded Qwen2.5-Turbo to support context lengths of up to one million Tokens. Today, Qwen officially launched the open source Qwen2.5-1M model and its corresponding inference framework support. Here are the highlights of the release:
Open Source Modeling: Two new open source models were released, namely Qwen2.5-7B-Instruct-1M cap (a poem) Qwen2.5-14B-Instruct-1MThis is the first time Qwen has extended the context of the open-source Qwen model to 1M length.
Reasoning Framework: To help developers deploy the Qwen2.5-1M family of models more efficiently, the Qwen team has completely open-sourced the Qwen2.5-1M model based on the vLLM inference framework with an integrated sparse attention approach, which makes the framework faster in processing 1M labeled inputs by 3x to 7xThe
Technical report: The Qwen team also shared the technical details behind the Qwen2.5-1M series, including the design thinking behind the training and inference frameworks and the results of the ablation experiments.
Model Link:https://www.modelscope.cn/collections/Qwen25-1M-d6cf9fd33f0a40
Technical report:https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen2.5-1M/Qwen2_5_1M_Technical_Report.pdf
Experience Links:https://modelscope.cn/studios/Qwen/Qwen2.5-1M-Demo
2. Model Performance
First, let's take a look at the performance of the Qwen2.5-1M family of models in long context tasks and short text tasks.
long context task
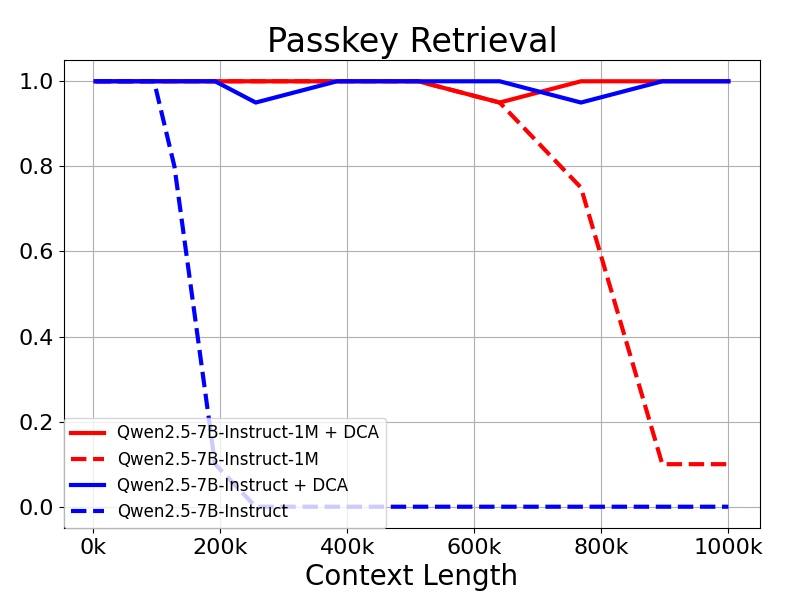
With a context length of 1 million Tokens In the Passkey Retrieval task, the Qwen2.5-1M family of models accurately retrieved hidden information from documents of 1M length, with only a few errors in the 7B model.
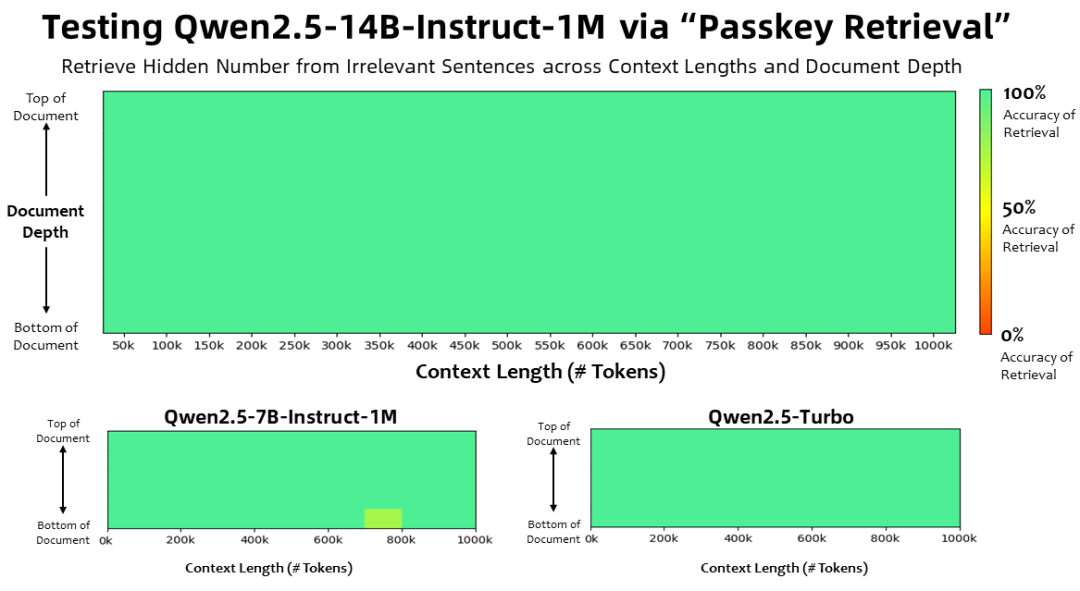
For more complex long context understanding tasks, the RULER, LV-Eval and LongbenchChat test sets were chosen.
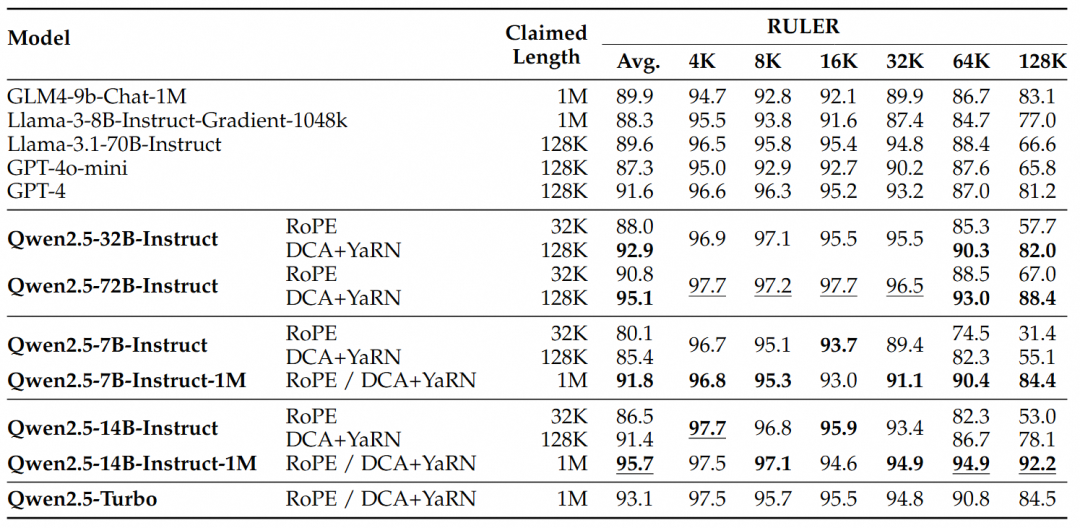
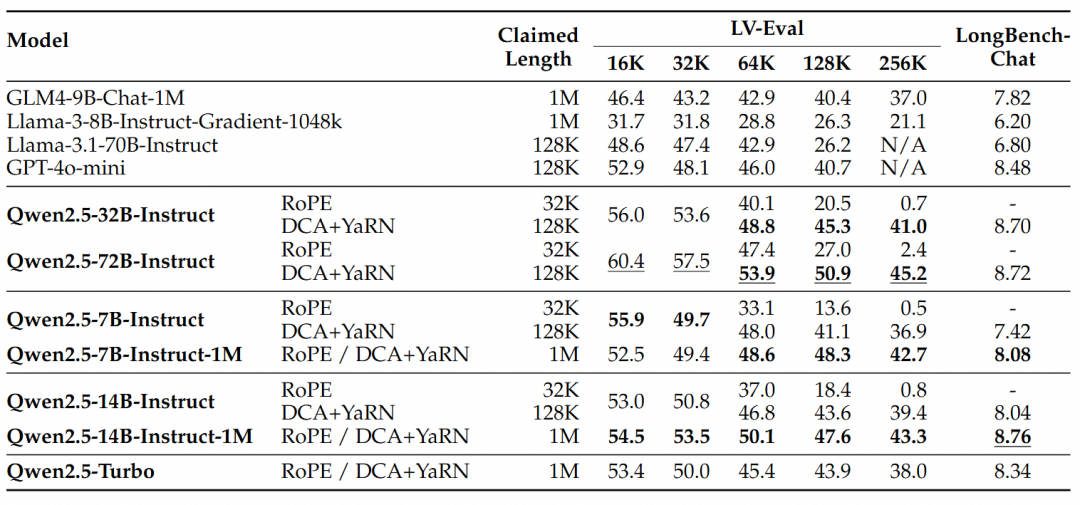
From these results, the following key conclusions can be drawn:
- Significantly outperforms the 128K version:The Qwen2.5-1M family of models significantly outperforms the previous 128K version for most long context tasks, especially when dealing with tasks over 64K in length.
- The performance advantages are obvious:The Qwen2.5-14B-Instruct-1M model not only beats Qwen2.5-Turbo, but also consistently outperforms GPT-4o-mini on multiple datasets, providing an open-source model of choice for long context tasks.
short sequential task
In addition to performance on long sequence tasks, the performance of the model on short sequences is equally important. The Qwen2.5-1M series of models and previous 128K versions were compared in widely used academic benchmarks, and the GPT-4o-mini was added for comparison. 
It can be found:
- The performance of Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M on the short text task is comparable to that of their 128K versions, ensuring that the basic capabilities have not been compromised by the addition of long sequence processing capabilities.
- Compared to GPT-4o-mini, Qwen2.5-14B-Instruct-1M and Qwen2.5-Turbo achieve similar performance on the short text task, while the context length is eight times longer than GPT-4o-mini.
3. Key technologies
Long context training
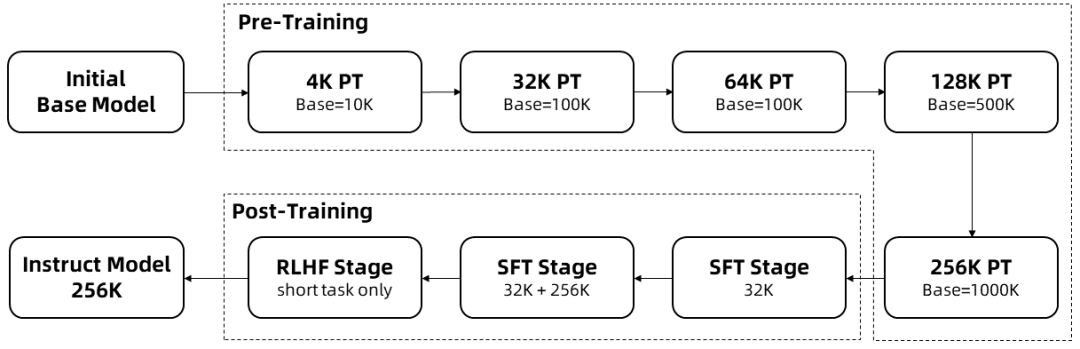
The training of long sequences requires a lot of computational resources, so a gradual expansion of the length was used to extend the context length of Qwen2.5-1M from 4K to 256K in multiple stages:
Starting from an intermediate Checkpoint of the pre-trained Qwen2.5, the context length is 4K at this point.
In the pre-training phaseIn addition, we gradually increased the context length from 4K to 256K, while using the Adjusted Base Frequency scheme to increase the RoPE base frequency from 10,000 to 10,000,000.
During the monitoring fine-tuning phase, in two stages to maintain performance on short sequences:
Phase I: Fine-tuning is done only on short instructions (up to 32K in length), where the same data and number of steps are used as in the 128K version of Qwen2.5.
Phase II: Mixing short instructions (up to 32K) and long instructions (up to 256K) is realized to enhance the performance of long tasks while maintaining the quality of short tasks.
During the intensive learning phasethat trains the model on short text (up to 8K markers). We found that even when trained on short textbooks, the boost in human-preferred alignment generalizes well to long context tasks. With the above training, we end up with an Instruct model that can handle sequences up to 256K Tokens long.
With the above training, an instruction fine-tuning model with 256K context length is obtained.
Length extrapolation
In the above training process, the context length of the model is only 256K Tokens. in order to scale it up to 1M Tokens, a length extrapolation technique is employed.
Currently, large-scale language models based on rotational position encoding produce performance degradation in long context tasks, which is mainly due to the fact that the relative position distance between the Query and the Key is too large when calculating the attention weights, which is unseen during the training process. To solve this problem, Qwen2.5-1M uses the Dual Chunk Attention (DCA) approach, which solves this challenge by taking the excessively large relative positions and remapping them to smaller values.
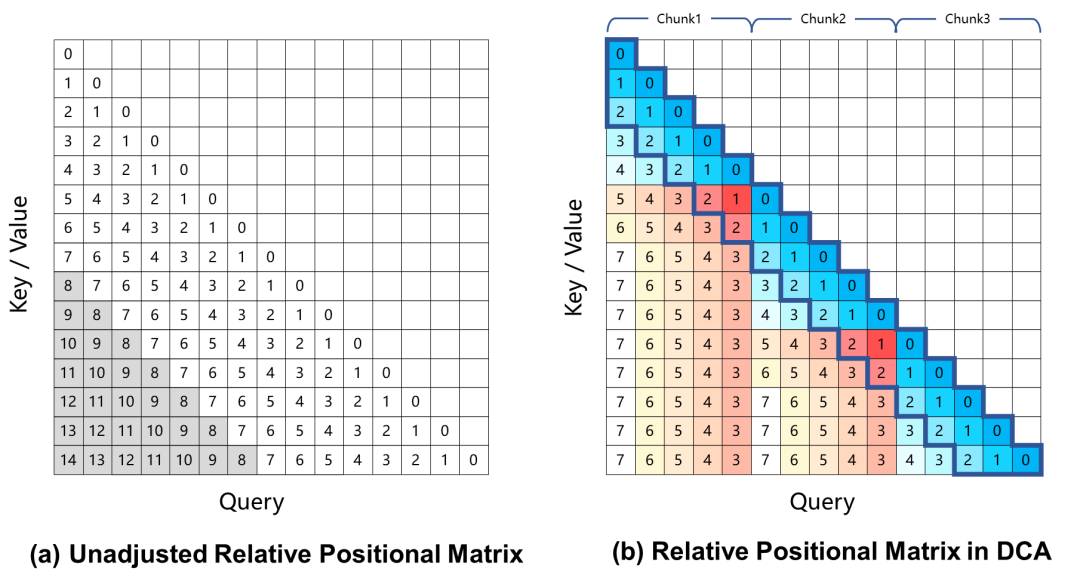
The Qwen2.5-1M model and previous 128K versions were evaluated with and without the length extrapolation method.
The results show that even models trained only on 32K tokens, such as Qwen2.5-7B-Instruct, are not successful in handling 1M-token contexts of Passkey Retrieval The task also achieves near-perfect accuracy. This demonstrates the power of DCA to significantly scale the length of supported contexts without additional training.
Sparse attention mechanism
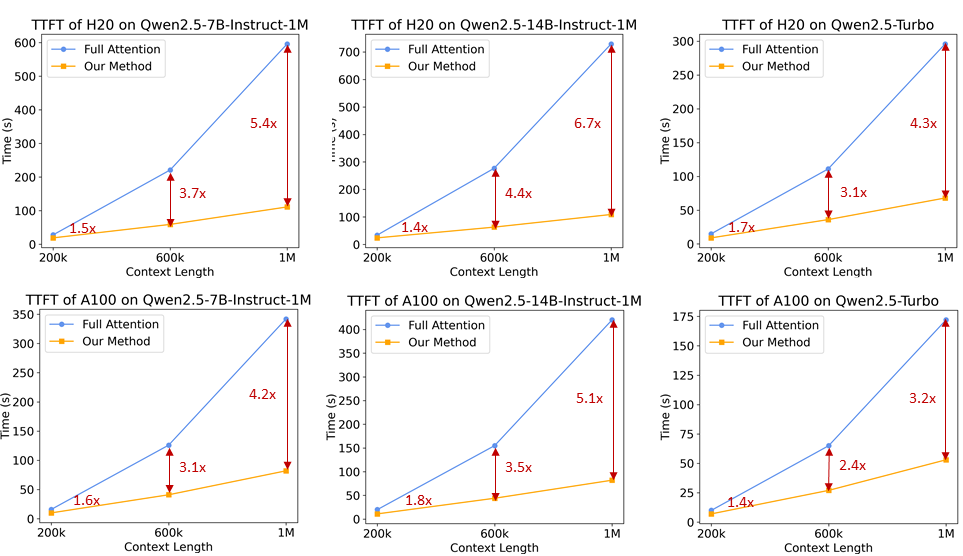
For long context language models, inference speed is crucial for user experience. To speed up the pre-population phase, the research team introduced a sparse attention mechanism based on MInference. In addition, several improvements are proposed:
- Chunked Prefill: If the model is used directly to process sequences up to 1 million in length, the activation weights of the MLP layer incur a significant memory overhead. Taking Qwen2.5-7B as an example, this overhead is as high as 71 GB. By adapting Chunked Prefill with Sparse Attention, the input sequences can be chunked in 32768 lengths and pre-filled one by one, and the memory usage of the activation weights at the MLP layer can be reduced by 96.7%, which can significantly reduce the memory requirement of the device.
- Integrated Length Extrapolation Scheme: We further integrate a DCA-based length extrapolation scheme into the sparse attention mechanism, which enables our inference framework to enjoy both higher inference efficiency and accuracy for long sequence tasks.
- Sparsity Optimization: The original MInference method requires an offline search to determine the optimal sparsification configuration for each attention head. This search is usually performed on short sequences and does not necessarily work well with longer sequences due to the large memory requirements of the full attention weights. We propose a method that can optimize the sparsification configuration on sequences of 1 million length, thus significantly reducing the accuracy loss due to sparse attention.
- Other optimizations: We also introduce other optimizations, such as optimized operator efficiency and dynamic chunking pipeline parallelism, to exploit the full potential of the entire framework.
With these enhancements, the inference framework is able to reduce the number of 1M token The pre-population speed of sequences of length was increased from 3.2-fold to 6.7-fold.
4. Model deployment
System preparation
For best performance, it is recommended to use a GPU with an Ampere or Hopper architecture that supports optimized cores.
Please ensure that the following requirements are met:
- CUDA version: 12.1 or 12.3
- Python version: >=3.9 and <=3.12
Memory requirements, for processing 1M length sequences:
- Qwen2.5-7B-Instruct-1M: Requires at least 120GB of video memory (multi-GPU sum).
- Qwen2.5-14B-Instruct-1M: Requires at least 320GB of video memory (multi-GPU sum).
If the GPU memory does not meet these requirements, you can still use Qwen2.5-1M for shorter tasks.
Installing dependencies
For the time being, you will need to clone the vLLM repository from a custom branch and install it manually. The research team is working on committing that branch to the vLLM project.
git clone -b dev/dual-chunk-attn git@github.com:QwenLM/vllm.git cd vllm pip install -e . -v
Starting an OpenAI-compatible API service
Specifies that the model is downloaded from ModelScope
export VLLM_USE_MODELSCOPE=True
Release of OpenAI-compatible API services
vllm serve Qwen/Qwen2.5-7B-Instruct-1M \ --tensor-parallel-size 4 \ --max-model-len 1010000 \ --enable-chunked-prefill --max-num-batched-tokens 131072 \ --enforce-eager \ --max-num-seqs 1
Parameter Description:
--tensor-parallel-size- Set to the number of GPUs you are using. 7B models support up to 4 GPUs and 14B models support up to 8 GPUs.
--max-model-len- Defines the maximum input sequence length. Reduce this value if you encounter out-of-memory problems.
--max-num-batched-tokens- Sets the block size of the Chunked Prefill. A smaller value reduces activation memory usage, but may slow down reasoning.
- The recommended value is 131072 for optimal performance.
--max-num-seqs- Limit the number of sequences processed concurrently.
Interacting with models
The following methods can be used to interact with the deployed model:
Option 1.
curl http://localhost:8000/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen2.5-7B-Instruct-1M",
"messages": [
{
"role": "user",
"content": "Tell me something about large language models."
}
],
"temperature": 0.7,
"top_p": 0.8,
"repetition_penalty": 1.05,
"max_tokens": 512
}'
Option 2. Use Python
from openai import OpenAI
openai_api_key = "EMPTY"
openai_api_base = "http://localhost:8000/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
prompt = (
"""There is an important info hidden inside a lot of irrelevant text.
Find it and memorize them. I will quiz you about the important information there.\n\n
The pass key is 28884. Remember it. 28884 is the pass key.\n"""
+ "The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again. " * 800
+ "\nWhat is the pass key?"
)
# The prompt is 20k long. You can try a longer prompt by replacing 800 with 40000.
chat_response = client.chat.completions.create(
model="Qwen/Qwen2.5-7B-Instruct-1M",
messages=[
{"role": "user", "content": prompt},
],
temperature=0.7,
top_p=0.8,
max_tokens=512,
extra_body={
"repetition_penalty": 1.05,
},
)
print("Chat response:", chat_response)
You can also explore other frameworks, such as Qwen-Agent, to enable models to read PDF files and so on.
5. Use the Magic Hitch API-Inference to directly call the
The API-Inference of the Magic Match platform also provides support for the Qwen2.5-7B-Instruct-1M and Qwen2.5-14B-Instruct-1M models at the first time. Users of Magic Hitch can use the model directly by means of API calls. Specific API-Inference usage can be described on the model page (e.g. https://modelscope.cn/models/Qwen/Qwen2.5-14B-Instruct-1M ):

Or see the API-Inference documentation: https://www.modelscope.cn/docs/model-service/API-Inference/intro
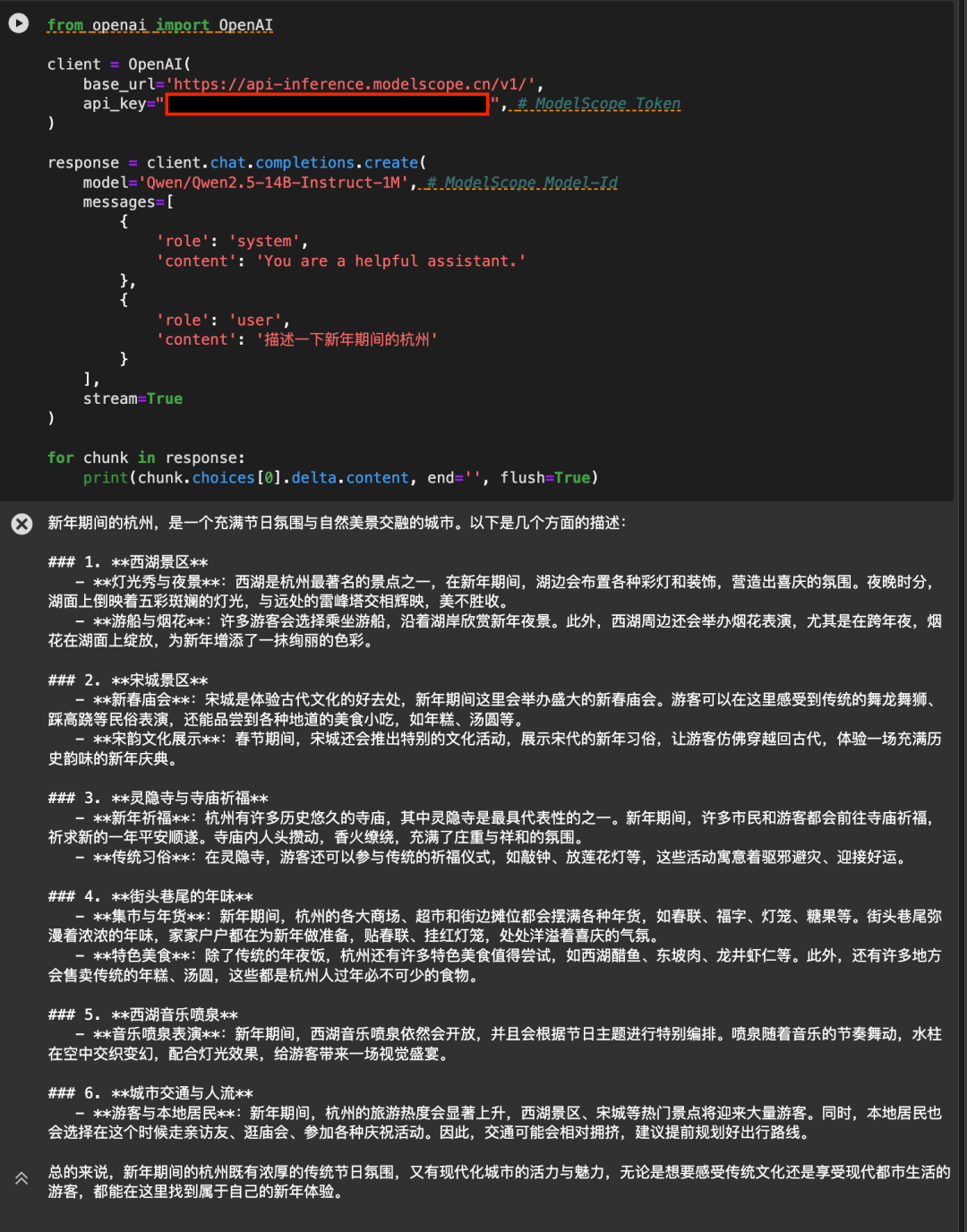
Thanks to AliCloud Hundred Refinement Platform for providing arithmetic support behind the scenes.
Use of Ollama and llamafile
In order to facilitate your local use, Magic Ride has provided the GGUF version and llamafile version of Qwen2.5-7B-Instruct-1M model at the first time. It can be called by Ollama framework, or use pull up llamafile directly.
1. Ollama call
First set up ollama under enable:
ollama serve
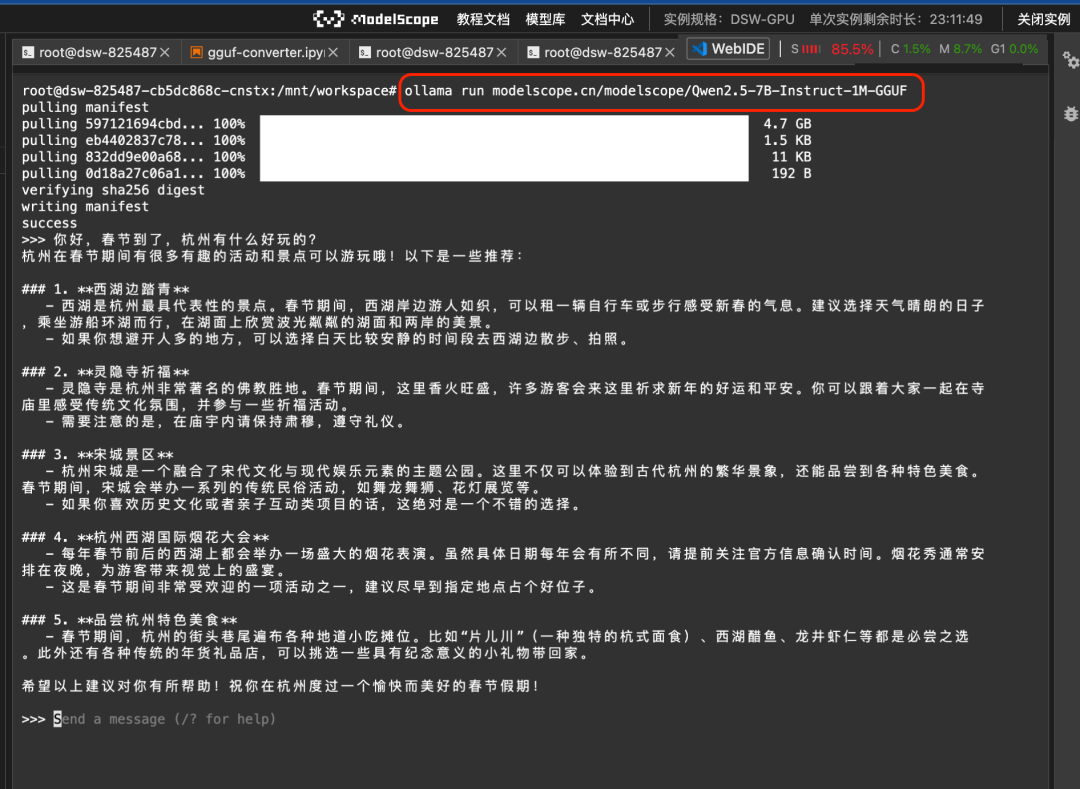
Then you can run the GGUF model on the magic hitch directly using the command ollama run:
ollama run modelscope.cn/modelscope/Qwen2.5-7B-Instruct-1M-GGUFRun results:
2. llamafile models pull up directly
Llamafile Provides a solution where the big model and runtime environment are all encapsulated in one executable file. Through the integration of Magic Ride command line and llamafile, you can really realize to run the big model with one click in different operating system environments such as Linux/Mac/Windows:
modelscope llamafile --model Qwen-Llamafile/Qwen2.5-7B-Instruct-1M-llamafileRun results:
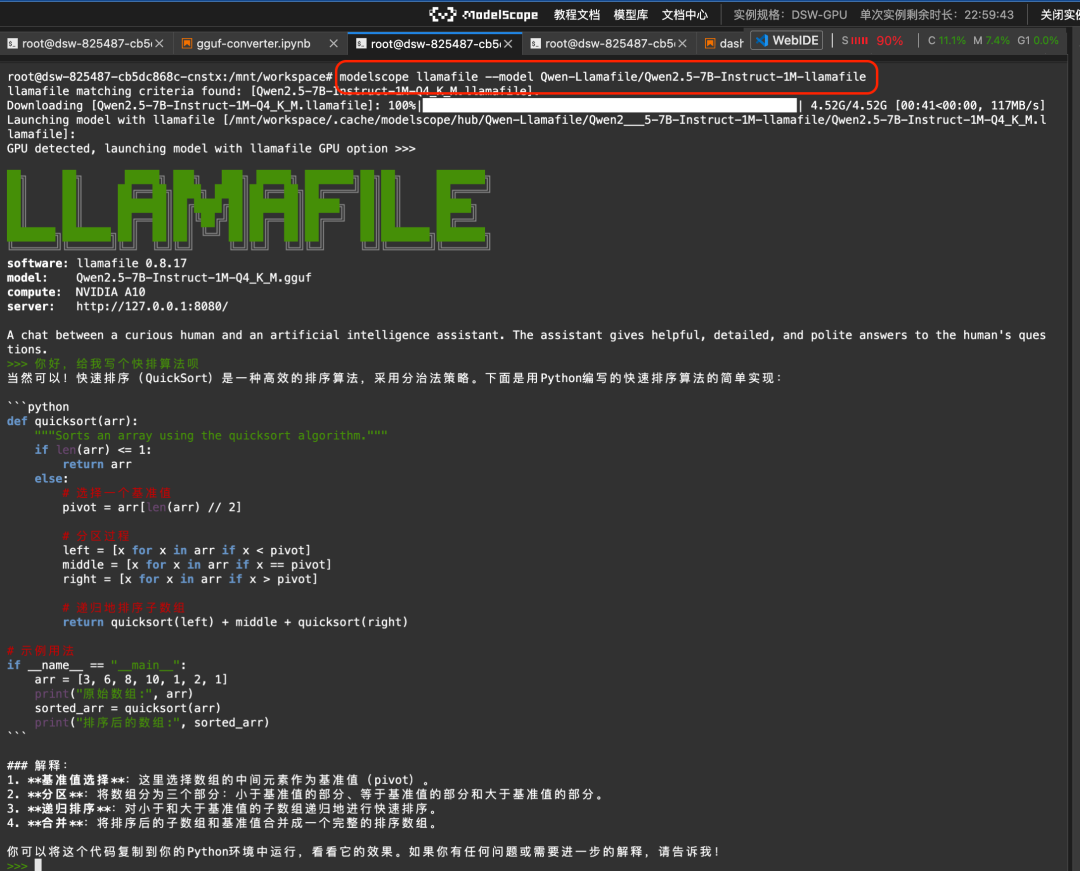
More documentation is available at https://www.modelscope.cn/docs/models/advanced-usage/llamafile
6. Model fine-tuning
Here we present the fine-tuning of Qwen/Qwen2.5-7B-Instruct-1M using ms-swift.
Before you start fine-tuning, make sure your environment is properly installed:
# 安装ms-swift git clone https://github.com/modelscope/ms-swift.git cd ms-swift pip install -e .
We give the runnable fine-tuning demo and the style of the customized dataset, the fine-tuning script is as follows:
CUDA_VISIBLE_DEVICES=0
swift sft \
--model Qwen/Qwen2.5-7B-Instruct-1M \
--train_type lora \
--dataset 'AI-ModelScope/alpaca-gpt4-data-zh#500' \
'AI-ModelScope/alpaca-gpt4-data-en#500' \
'swift/self-cognition#500' \
--torch_dtype bfloat16 \
--num_train_epochs 1 \
--per_device_train_batch_size 1 \
--per_device_eval_batch_size 1 \
--learning_rate 1e-4 \
--lora_rank 8 \
--lora_alpha 32 \
--target_modules all-linear \
--gradient_accumulation_steps 16 \
--eval_steps 50 \
--save_steps 50 \
--save_total_limit 5 \
--logging_steps 5 \
--max_length 2048 \
--output_dir output \
--warmup_ratio 0.05 \
--dataloader_num_workers 4 \
--model_author swift \
--model_name swift-robot
Training video memory usage:

Custom dataset format: (just specify it directly using `--dataset `)
{"messages": [{"role": "user", "content": "<query>"}, {"role": "assistant", "content": "<response>"}, {"role": "user", "content": "<query2>"}, {"role": "assistant", "content": "<response2>"}]}
Reasoning Script:
CUDA_VISIBLE_DEVICES=0 \
swift infer \
--adapters output/vx-xxx/checkpoint-xxx \
--stream true \
--max_new_tokens 2048
Push the model to ModelScope:
CUDA_VISIBLE_DEVICES=0 swift export \
--adapters output/vx-xxx/checkpoint-xxx \
--push_to_hub true \
--hub_model_id '' \
--hub_token ''
7. What's next?
While the Qwen2.5-1M family brings excellent open-source options for long sequence processing tasks, the research team fully recognizes that there is still a lot of room for improvement in long context models. Our goal is to build models that excel in both long and short tasks to ensure that they are truly useful in real-world application scenarios. To this end, the team is working on more efficient training methods, model architectures, and reasoning approaches to enable efficient deployment and optimal performance of these models even in resource-limited environments. The team is confident that these efforts will open up new possibilities for long context models, significantly expanding their application scope and continuing to push the boundaries of the field, so stay tuned!
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...