New Qwen2.5-VL-32B-Instruct Multi-Modal Model Released with Super 72B Performance!

Recently, the much-anticipated Qwen2.5-VL Qwen2.5-VL-32B-Instruct, a new member of the Qwen2.5-VL series, has been officially released. This 32-billion-parameter-scale multimodal visual language model inherits the advantages of the Qwen2.5-VL series, and is further optimized by reinforcement learning and other technologies to achieve significant performance improvements, especially in complex reasoning and user experience.
At the end of January this year, the Qwen team launched the Qwen2.5-VL series of models, and quickly gained widespread attention and positive feedback from the community. In order to respond to the community's expectations and continue to promote the development of multimodal modeling technology, the team spent several months carefully polishing the Qwen2.5-VL series and finally launched this new Qwen2.5-VL-32B-Instruct model, which is open-sourced using the Apache 2.0 protocol, aiming at benefiting a wider range of developers and researchers.
A leap in performance, with many metrics surpassing the previous generation and similar models
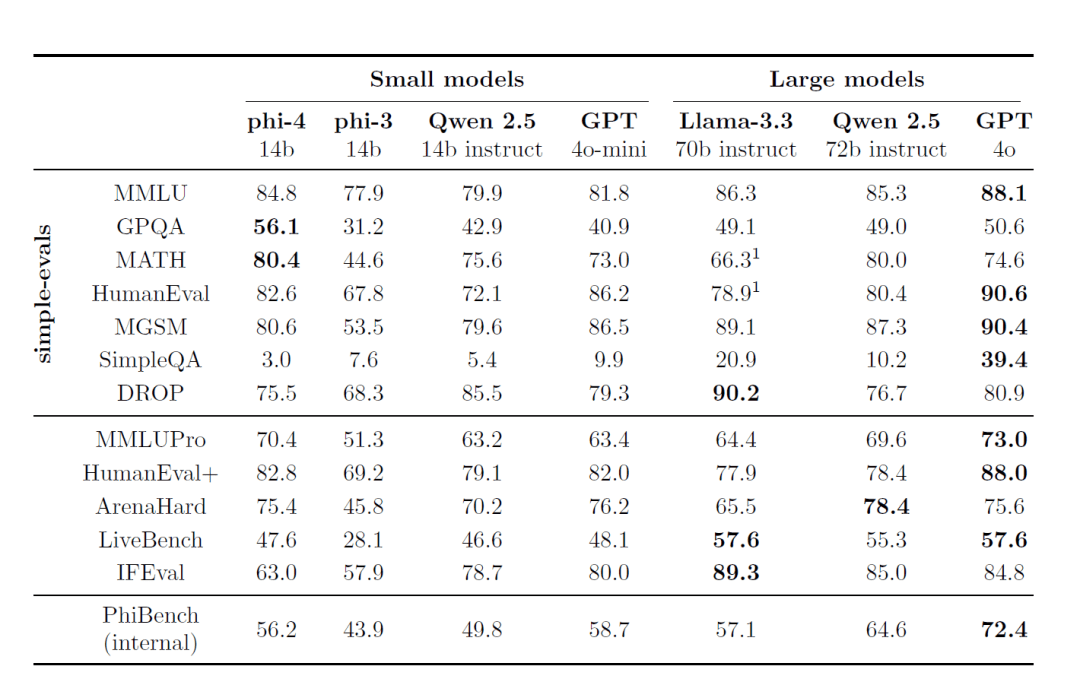
Official data shows that the Qwen2.5-VL-32B-Instruct model achieves significant improvements in a number of key performance indicators compared to the previously released Qwen2.5-VL series.
First of all, in terms of subjective user preferences, the new model, by adjusting the output style, makes the replies more detailed, more standardized in format, and more in line with human reading habits and preferences. This means that users will get a smoother and more natural interaction experience during use.
Second, in terms of mathematical reasoning ability, the Qwen2.5-VL-32B-Instruct model has made significant progress in the accuracy of solving complex mathematical problems. This indicates that the model has been effectively enhanced in terms of logical reasoning and computational ability, and is better able to cope with tasks that require in-depth thinking and precise computation.
In addition, the Qwen2.5-VL-32B-Instruct model shows stronger strength in image fine-grained understanding and reasoning. Whether it is in the precision of image parsing, the breadth of content recognition, or the depth of visual logic inference, the new model shows a higher level, and is able to analyze the image information more accurately and meticulously.
In order to visualize the performance advantages of the Qwen2.5-VL-32B-Instruct model, it was also tested against industry-leading models of the same size, including Mistral-Small-3.1-24B and Gemma-3-27B-IT. The results show that the Qwen2.5-VL-32B-Instruct model shows obvious advantages in many multimodal tasks, and some of the indexes even surpass the larger Qwen2-VL-72B-Instruct model. In particular, the outstanding performance of the Qwen2.5-VL-32B-Instruct model is impressive in tasks emphasizing complex multi-step reasoning such as MMMU, MMMU-Pro and MathVista. In the MM-MT-Bench benchmark, which emphasizes the subjective user experience, the model has also made significant progress compared to its predecessor, Qwen2-VL-72B-Instruct.

It is worth mentioning that the Qwen2.5-VL-32B-Instruct model not only excels in visual capability, but also achieves the optimal level of the same scale model in terms of text-only capability.

Technology highlights: dynamic resolution, efficient visual encoder
The Qwen2.5-VL series of models also features a series of innovations and upgrades in its technical architecture.
For video understanding, the model employs a dynamic resolution and frame rate training technique, which enables the model to understand video content with different sampling rates by introducing dynamic FPS sampling. At the same time, mRoPE (Multiple Relative Position Encoding) is updated in the temporal dimension and combined with IDs and absolute time alignment to enable the model to learn time-series and velocity information, which gives it the ability to capture key moments in the video.

For the vision encoder, the Qwen2.5-VL series models utilize a streamlined and efficient Vision Encoder, which can be used in the ViT (Vision) encoder. Transformer) strategically introduces the windowed attention mechanism in Qwen2.5 LLM, and combines it with optimizations such as SwiGLU and RMSNorm to make the ViT architecture more consistent with the structure of Qwen2.5 LLM, thus effectively improving the speed of model training and inference.
Open Source Inclusion for Multimodal Application Innovation
The open source release of the Qwen2.5-VL-32B-Instruct model will undoubtedly inject new vitality into the field of multimodal visual language. Based on the model, developers and researchers can conduct more in-depth research and develop more extensive applications, such as image and video content understanding, intelligent agents, cross-modal content generation, etc.
The Qwen2.5-VL-32B-Instruct model is now available on Hugging Face Transformers and ModelScope, with detailed code samples and instructions for users to quickly get started, and the Qwen team has indicated that it will continue to pay attention to the community's feedback to optimize and improve the Qwen2.5-VL series. Qwen2.5-VL series models will continue to pay attention to community feedback, optimize and improve, and contribute to the development of multimodal technology.
For those wishing to experience the Qwen2.5-VL-32B-Instruct model, a quick start can be made in the following way:
Environment Configuration
It is recommended that users build the transformers library from source to ensure compatibility:
pip install git+https://github.com/huggingface/transformers accelerateQuick start code example (using 🤗 Transformers).
from transformers import Qwen2_5_VLForConditionalGeneration, AutoTokenizer, AutoProcessor
from qwen_vl_utils import process_vision_info
# 加载模型
model = Qwen2_5_VLForConditionalGeneration.from_pretrained(
"Qwen/Qwen2.5-VL-32B-Instruct", torch_dtype="auto", device_map="auto"
)
# 加载 processor
processor = AutoProcessor.from_pretrained("Qwen/Qwen2.5-VL-32B-Instruct")
# 构建 messages
messages = [
{
"role": "user",
"content": [
{
"type": "image",
"image": "https://qianwen-res.oss-cn-beijing.aliyuncs.com/Qwen-VL/assets/demo.jpeg",
},
{"type": "text", "text": "Describe this image."},
],
}
]
# 预处理
text = processor.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
image_inputs, video_inputs = process_vision_info(messages)
inputs = processor(
text=[text],
images=image_inputs,
videos=video_inputs,
padding=True,
return_tensors="pt",
)
inputs = inputs.to("cuda")
# 模型推理
generated_ids = model.generate(**inputs, max_new_tokens=128)
generated_ids_trimmed = [
out_ids[len(in_ids) :] for in_ids, out_ids in zip(inputs.input_ids, generated_ids)
]
output_text = processor.batch_decode(
generated_ids_trimmed, skip_special_tokens=True, clean_up_tokenization_spaces=False
)
print(output_text)
The release of the Qwen2.5-VL-32B-Instruct model undoubtedly brings new breakthroughs in the field of multimodal visual language models, and its advantages in performance, technology and open source are expected to accelerate the popularization and application of multimodal technology, which deserves the industry's continued attention.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...