
Evaluating creativity in large language models: beyond the multiple-choice LoTbench paradigm

In the large language model ( LLM ) research area, the modeling of Leap-of-Thought competence, i.e., creativity, is as important as the ability to Chain-of-Thought for the logical reasoning skills represented. However, there is currently a significant increase in the number of students targeting LLM In-depth discussions of creativity and effective assessment methods are still relatively scarce, which to some extent constrains LLM Development potential in creative applications.
The main reason for this is that it is extremely difficult to construct an objective, automated and reliable assessment process for the abstract concept of "creativity".
In the past, many of the responses to LLM Attempts to measure creativity, as shown in Figure 1, continue to use multiple-choice and sequencing questions, which are commonly used to assess logical thinking skills. These methods are good at examining whether the model recognizes the "optimal" or "most logical" option, but they are not good at assessing true creativity - the ability to generate new and unique content. But they are not as good at assessing true creativity - the ability to generate new and unique content.
For example, consider the task in Figure 2: Based on the picture and the existing text, fill in the "? The content should be creative and humorous.
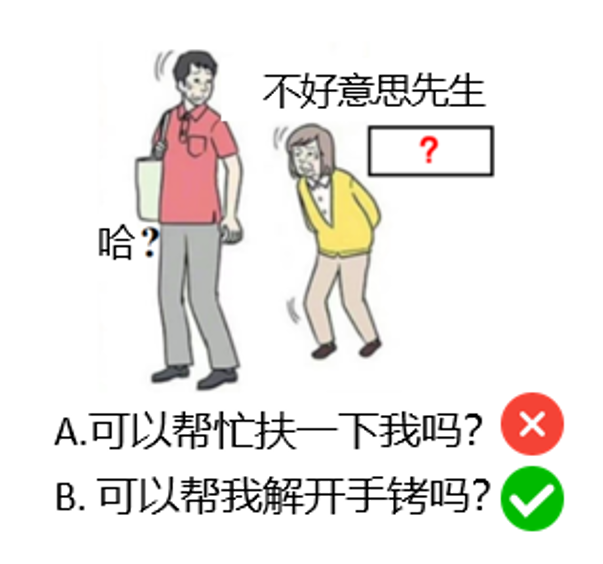
If this is a multiple choice question, provide options "A. Can you help me?" and "B. Can you help me out of my handcuffs?" and "B. Can you uncuff me?" and "B. Can you help me get out of my cuffs? LLM B is likely to be chosen, not because it shows creativity, but simply because option B is more "special" or "unusual" than option A, and the model is able to make the choice through pattern recognition rather than creative thinking.
valuation LLM of creativity, the core should be examined for itsgeneratingThe ability to innovate content rather thanjudgmentThe ability of the content to be innovative or not. Traditional assessment methods, such as multiple choice, are more focused on the latter and therefore have limitations. Currently, the main methods that can directly assess generative capacity are manual assessment and LLM-as-a-judge (Use LLM (as a review). Manual assessments, while accurate and consistent with human values, are costly and difficult to scale. While LLM-as-a-judge The performance of the method on creativity assessment tasks is still immature and the stability of the results needs to be improved.
In the face of these challenges, researchers from Sun Yat-sen University, Harvard University, Pengcheng Laboratory and Singapore Management University have come up with a new way of thinking. Instead of directly judging the "goodness" of the generated content, they are looking at the "goodness" of the content by studying LLM The "cost" of generating a response comparable to the content of high-quality human innovations(which can be interpreted as the effort or interaction cost required), constructed a program named LoTbench of a multi-round interactive automated creativity assessment paradigm. The approach aims to provide a more credible and scalable measure of creativity. Related research results have been published in IEEE TPAMI Journal.

- Dissertation Title: A Causality-aware Paradigm for Evaluating Creativity of Multimodal Large Language Models
- Link to paper: https://arxiv.org/abs/2501.15147
- Project home page: https://lotbench.github.io
Mission Scene: Japanese Cold Spit
LoTbench The study is based on CVPR'24 A journal extension of the work presented at the conference Let's Think Outside the Box: Exploring Leap-of-Thought in Large Language Models with Creative Humor Generation. Generation). The researchers chose a task form derived from the traditional Japanese game Oogiri, which is known as "Japanese Cold Trolling" on the Chinese Internet, as shown in Figure 2.
This type of task requires participants to view pictures and complete the text, making the combination of pictures and text innovative and humorous. This task was chosen as the basis for the assessment based on the following considerations:
- High creativity requirements: The task is a direct request to generate creative humor content, a typical creativity challenge.
- Fitting the multimodal model: Input is graphic, output is text-completion, fully compliant with current multimodal
LLMThe scope of competence of the - Rich data resources: The popularity of "Japanese Cold Trolling" in the online community has accumulated a large amount of high-quality examples of human creations and data with evaluation information, making it easy to construct evaluation datasets.
Thus, "Japanese cold spit" provides a useful tool for evaluating multimodal LLM of creativity provides an ideal and unique platform.
LoTbench Assessment Methodology

Unlike traditional assessment paradigms (e.g., selection, ranking), the LoTbench The core idea is:Measuring a LLM How many rounds of interactions are required to generate a human quality innovation response that matches the preset ( HHCR The answer is "different". This required "number of rounds" reflects the LLM The "distance" or "cost" of reaching a particular creative goal.
As shown on the right-hand side of Figure 3, for a given HHCR (math.) genus LoTbench Not a requirement LLM Reproduce it exactly, but rather look at the LLM Is it possible to generate, in multiple rounds of attempts, an idea that, although expressed differently, has a similar creative core and effect (i.e., the DAESO - Different Approach but Equally Satisfactory Outcome) response.
LoTbench The specific flow of the process is shown in Figure 4:
- Task Construction: Selected from the "Japanese Cold Tweets" data.
HHCRSample. For each round, it is required that the test to beLLMGenerate a response based on the graphic informationRtto fill in text gaps. - DAESO Judgment: Judge the generated
RtRelevance to the objectiveHHCR(Denoted asR) reached theDAESO. If yes, record the current number of rounds for subsequent score calculations; if no, go to step 3. - Interactive questioning: If not
DAESOIf the test is to be performed on the same sample, it is required that the sample is to be measured on the same sample.LLMA general question based on the current history of the interactionQt(e.g., asking for clues about the target creative direction). - System Feedback: The evaluation system is based on
HHCRThe internal logic of theLLMIssues raisedQtAnswer "Yes" or "No". - Information integration and iteration: Put all the interaction information for this round (including the
LLMgeneration, questioning, and feedback from the system) and the integration of the prompts provided by the system to form the next round of thehistory promptIf you are not sure what to do, go back to step 1 and start a new round of attempts.
This process continues until LLM generated DAESO response, or the preset maximum round limit has been reached.
Final Creativity Score Sc based on a review of n classifier for individual things or people, general, catch-all classifier HHCR Sample, conduct m The results were calculated from the results of several repetitions of the experiment. The calculations are roughly as follows (in HTML formulas):
Sc = ( 1 / n ) ∑i=1n [ ( 1 / m ) ∑j=1m ( 1 / ( 1 + kij ) ) ]
Among them.k_ij is the model in the first j The second repetition of the experiment was performed for the first i classifier for individual things or people, general, catch-all classifier HHCR samples, successfully generating DAESO The number of rounds used for the response.
This creativity score Sc With the following characteristics:
- Inverse relationship: Score and number of rounds required
kInversely proportional. Fewer rounds indicateLLMThe faster you reach your target level of creativity, the higher your score and the more creative you are. - Zero points lower limit: in the event that
LLMConsistently fails to generate within the maximum number of rounds limitDAESOresponse (equivalent to the number of rounds tending to infinity), its score for this sample tends to 0, indicating insufficient creativity on this task. - Robustness: This is accomplished through the use of multiple
HHCRSamples were averaged over multiple repetitions of the experiment, and the scores took into account the diversity and difficulty of the ideas, reducing the randomization effects of a single experiment.
How to determine "similarities and differences" ( DAESO (___)?
DAESO The determination of the LoTbench One of the central difficulties of the methodology.
Why do you need DAESO Judgment? One of the key features of creativity tasks is their openness and variety. Humans can come up with many different, but equally creative and humorous, answers to the same "Japanese cold troll" scenario. As shown in Figure 5, both "vibrant alarm clock" and "vibrant cell phone" are centered on the core idea that "the object beats and makes sounds due to its vibrancy", and both achieve similar humorous effects. The humor effect is similar.
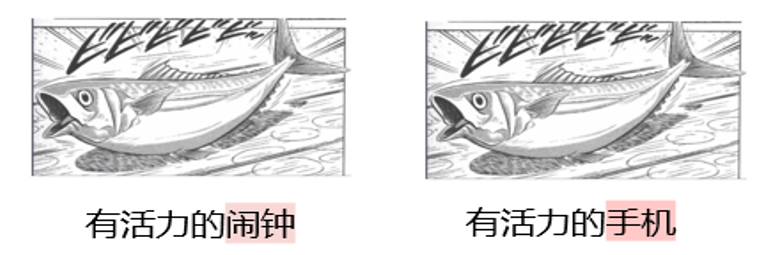
Simply matching the surface of words or regular semantic similarity calculations cannot accurately capture this deep creative similarity. For example, although "energetic flea" also has the word "energetic", it lacks the functional association of "sound reminder" implied by "alarm clock" or "cell phone". The functional association of "sound reminding" implied by "alarm clock" or "cell phone" is missing. It is therefore important to introduce a mechanism for determining "similarity and difference".
How to realize DAESO Judgment?
In the paper, the researcher suggests that two responses that are to satisfy the DAESO , two conditions need to be met at the same time:
- Same core innovation explained: The creative logic or humor behind both responses is essentially the same.
- Same functional similarity: The two responses are similar in their "function" or "scene role" in eliciting humor.
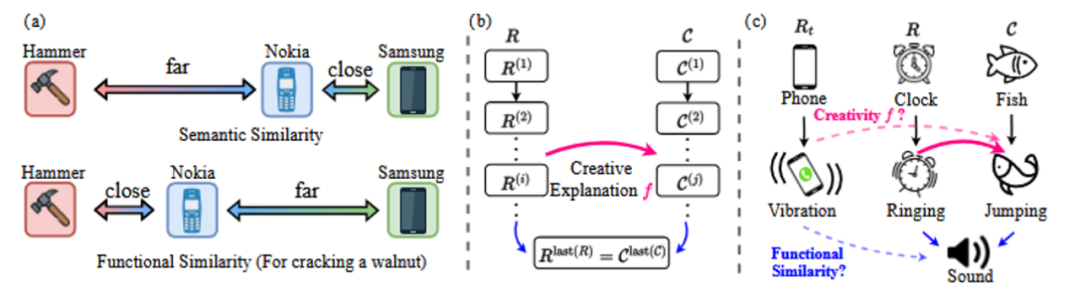
Functional similarity is different from pure semantic similarity. As the example in Fig. 6(a) shows, in the specific functional scenario of "smashing walnuts", the functional similarity between "Nokia cell phone" and "hammer" may be higher than the semantic similarity between "Samsung cell phone" and "Samsung cell phone". The semantic similarity between "Nokia cell phone" and "hammer" may be higher than the semantic similarity between "Samsung cell phone" and "Samsung cell phone".
Only meeting the same interpretation of the core innovation may result in a response that deviates from the theme (e.g., the example of the "Energetic Flea" in Figure 5, which lacks the function of "vocal reminder"); only meeting the same functional similarity may fail to capture the core of the idea (e.g., the example of the "Energetic Drum" in Figure 5, which is also a vocal object, but lacks the feeling of beating due to its own "energy"). The "Energetic Drum" in the example in Fig. 5 is also a sounding object, but it lacks the feeling of beating due to its own "energy").
in concrete terms DAESO In the judgmental realization, the researcher first provides a new judgment for each HHCR The samples were labeled with a detailed explanation of the source of their humor and creativity. Then, the title (caption) information of the image was combined and utilized with the LLM itself in text space for the ability to HHCR Construct a causal chain (as shown in Fig. 6(c)) to parse its creative composition. Finally, design specific instructions (instruction) for another LLM (e.g. GPT-4o mini ) Based on this information, the response to be measured is determined in text space Rt integration with the target HHCR Whether both of the above DAESO Condition.
Studies have shown that the use of GPT-4o mini carry out DAESO judgment, the accuracy of 80%-90% can be achieved at a lower computational cost. Considering the LoTbench Multiple repetitions of the experiment will be performed, with a single DAESO The effect of minor errors in judgment on the final average score is further minimized, thus ensuring the reliability of the overall assessment.
Evaluation results
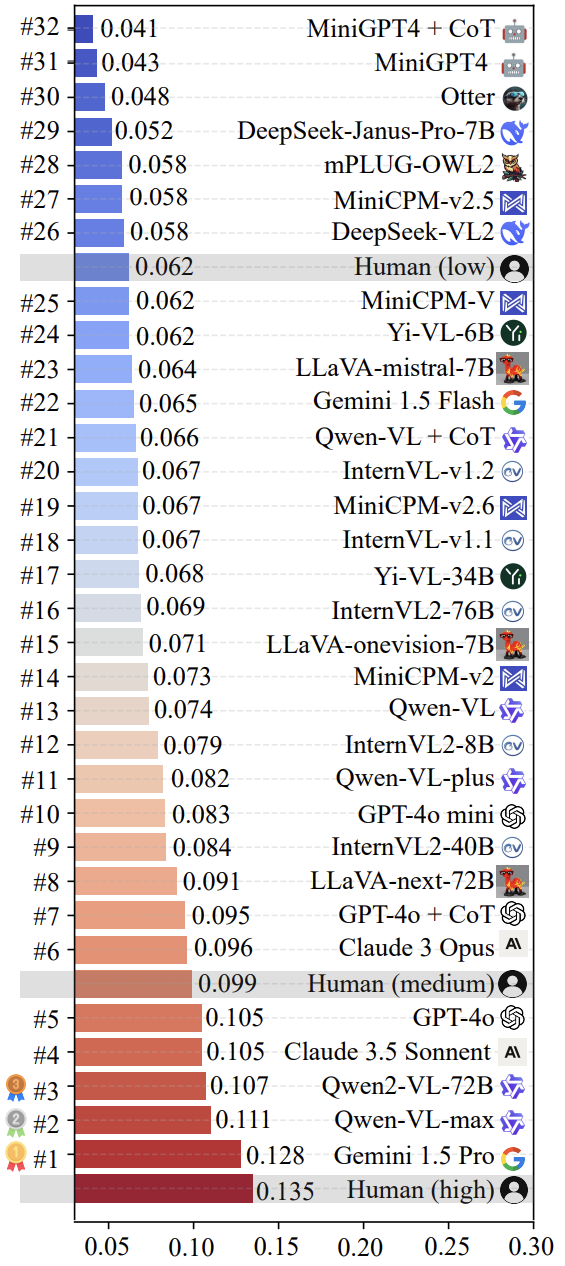
The research team used LoTbench For some of the current mainstream multimodal LLM The measurements were conducted. As shown in Fig. 7, the results show that the results are based on the LoTbench existing LLM of creativity is generally not considered to be strong, compared to high quality human creative response ( HHCR ) still fall short in comparison. However, compared to the general human level (not explicitly labeled in the figure, but inferred) or the primary human level, some of the top LLM (e.g. Gemini 1.5 Pro cap (a poem) Qwen-VL-max ) has shown some competitiveness and also hints at the LLM Possesses the potential to surpass humans in terms of creativity.
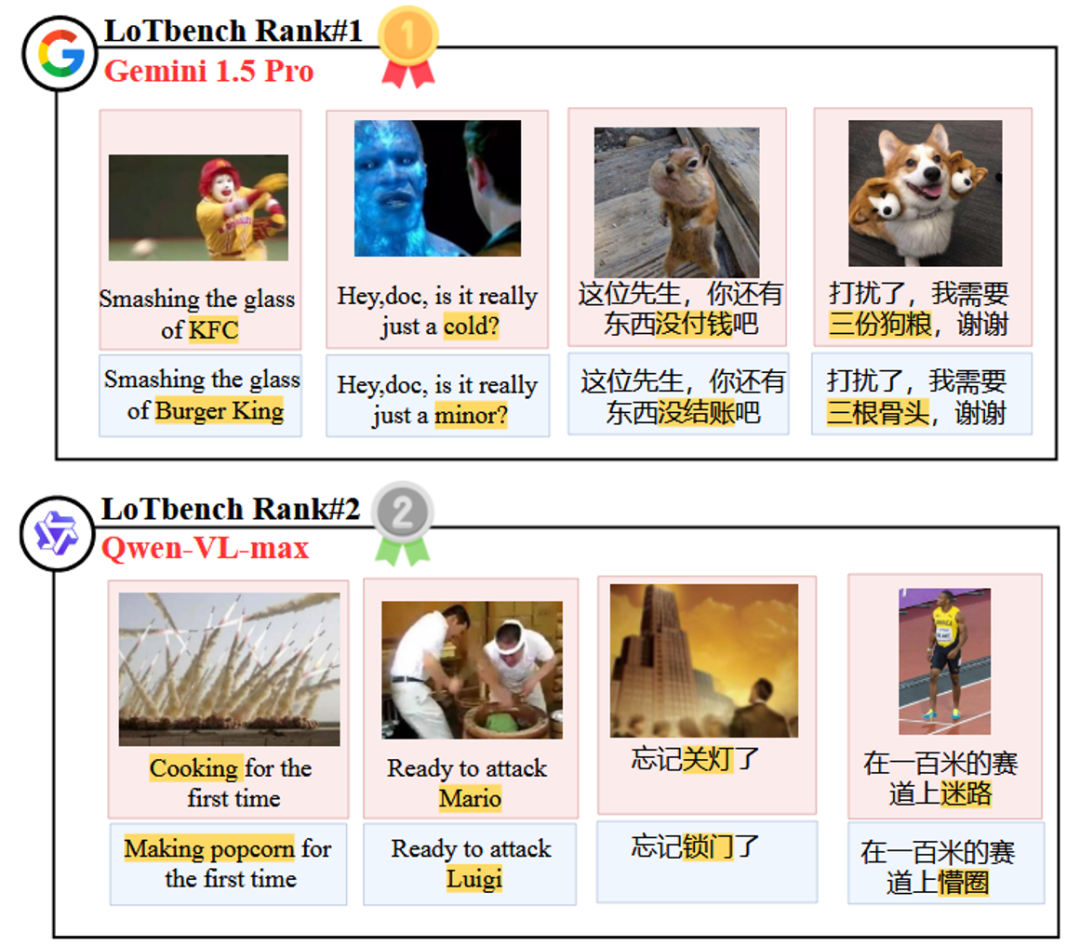
Figure 8 visualizes the top two rankings in the list of Gemini 1.5 Pro cap (a poem) Qwen-VL-max model-specific component HHCR (highlighted in red) generated DAESO Response (labeled in blue).
It is worth noting that the recent highly publicized DeepSeek-VL2 cap (a poem) Janus-Pro-7B Series models were also evaluated. The results showed that their creativity in LoTbench framework is roughly at the level of the human primary. This suggests that in enhancing multimodal LLM There is still considerable room for exploration in terms of the deep creativity of the
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...