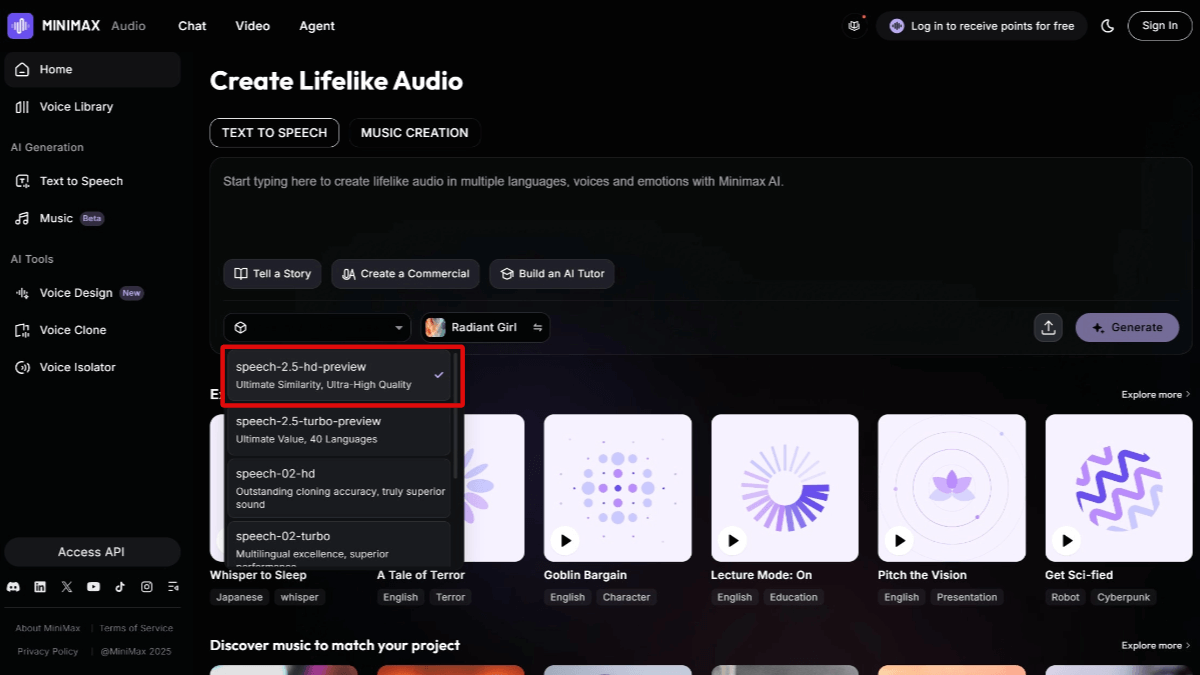
OpenAI.fm: an interactive demo tool showcasing the OpenAI speech APIs

General Introduction
openai-fm is an open source project hosted on GitHub dedicated to demonstrating the capabilities of the OpenAI Text-to-Speech (TTS) API. This project allows developers to visualize OpenAI's speech generation capabilities through an interactive web application. It was developed using the NextJS framework, combined with TailwindCSS and ShadcnUI to create a clean and modern interface. Users can enter text , select different voice and emotional style to generate high-quality voice output. The project code is completely open source , follow the MIT license , developers are encouraged to clone , modify and contribute to the code . openai-fm is suitable for developers to quickly understand and test the OpenAI speech API , especially suitable for application development scenarios that require speech functions .
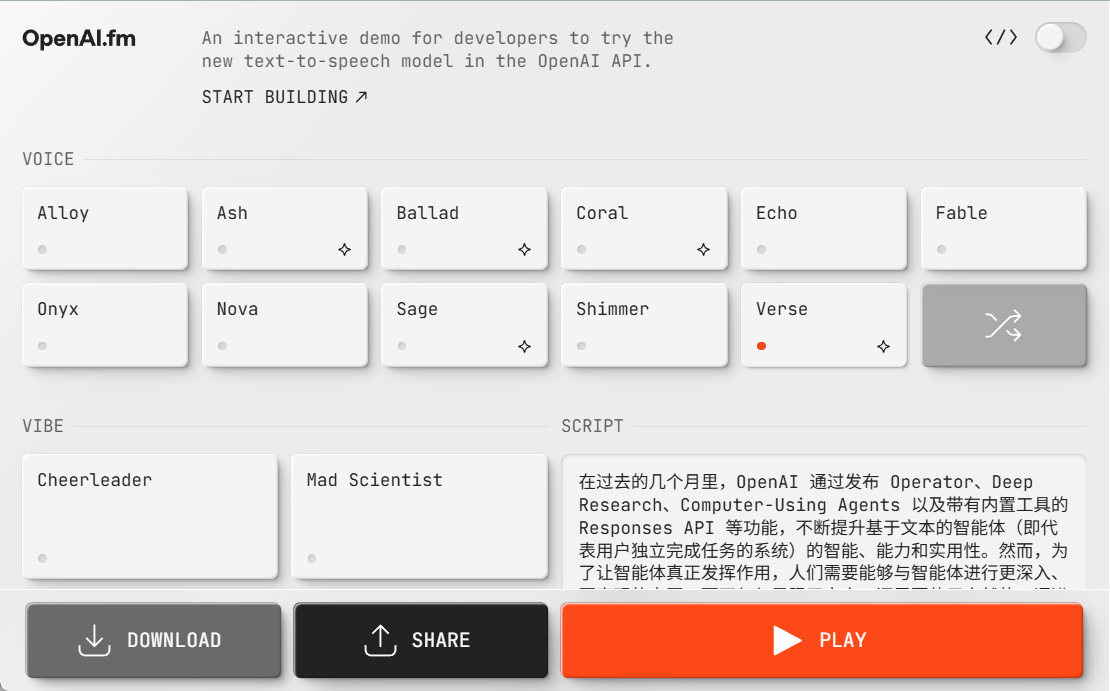
Demo address: https://www.openai.fm/
Function List
- Text-to-Speech Conversion: Convert the input text into natural and smooth speech.
- Multiple Voice Options: Provides multiple voice options to meet the needs of different scenarios.
- Emotional style control: supports adjusting the emotional tone of the voice, such as friendly, serious, etc.
- Real-time Interactive Presentation: Generate and playback voice in real time through a web interface.
- Database Sharing Function: Supports connecting to PostgreSQL database to save and share the generated speech.
- Open Source Support: Provides full source code, allowing developers to customize and extend functionality.
Using Help
Installation process
To use openai-fm, you first need to clone the project and configure the environment. Here are the detailed steps:
- Getting the API key
Visit the OpenAI website and register or login to your account. In your account dashboard, navigate to the API Key Management page and click on "Create a new key" to generate and save yourOPENAI_API_KEYThis key is used to call the OpenAI Speech API. This key is used to call OpenAI's speech API. note: the key needs to be kept secret to avoid disclosure. - clone warehouse
Open a terminal and run the following command to clone the openai-fm repository:git clone https://github.com/openai/openai-fm.git
Go to the project catalog:
cd openai-fm
- Setting environment variables
You can set it up in two waysOPENAI_API_KEY::- global setting: Add the following to your system environment variables
OPENAI_API_KEYThe- Linux/MacOS Example:
export OPENAI_API_KEY=<你的API密钥> - Windows users can add environment variables in the system settings.
- Linux/MacOS Example:
- Setting within the project: Create the
.envDocumentation, reference.env.example, add the following:OPENAI_API_KEY=<你的API密钥>
- global setting: Add the following to your system environment variables
- Installation of dependencies
The project uses Node.js and npm to manage dependencies. Make sure you have Node.js installed (recommended version 16 or higher). Run it from the project root directory:npm installThis will install the necessary dependencies such as NextJS, TailwindCSS, ShadcnUI and so on.
- (Optional) Configuration database
If you need to use the sharing feature, you need to connect to the PostgreSQL database. You can find a link to the PostgreSQL database in the.envfile to add database connection information, refer to the.env.example::POSTGRES_URL="postgresql://用户名:密码@主机:端口/数据库名"Ensure that the PostgreSQL service is running and that the appropriate databases are created. If you are not using the sharing feature, you can skip this step.
- Running Projects
After the installation is complete, run the following command to start the development server:npm run devOpen your browser and visit
http://localhost:3000You can see the interactive interface of openai-fm.
Main Functions
The core of openai-fm is the interactive text-to-speech demo. Below is the detailed operation flow:
- input text
Enter the text you want to convert to speech in the text box of the web interface. Multi-line text is supported, suitable for long dialogs or scripts. Example:你好!这是一个测试,展示如何将文本转为自然语音。 - Selecting Voice and Emotion
The interface provides drop-down menus that list the available voice options (e.g., male, female) and emotional styles (e.g., friendly, serious). These options are based on thedata/voices.jsoncap (a poem)data/vibes.jsonFile Configuration. After selecting it, click the "Generate" button and the system will call the OpenAI Speech API to generate the audio. - Playback and download
The generated audio is automatically played on the page. You can also download the audio file, which is saved in WAV format by default and stored in the project directory in theoutput/folder, with file names starting withopenaifm_Beginning and timestamped. - Share function
If a PostgreSQL database is configured, the generated voice can be saved to the database and a sharing link can be generated. Clicking the "Share" button will return an accessible URL where other users can view and play your voice.
Developer Customization
openai-fm is an open source project , developers can modify the code as needed . For example:
- Add new voice:: Editorial
data/voices.json, adding new voice configurations. - Adjustment of the interface: Modify NextJS components (e.g.
pages/index.js) or TailwindCSS styles. - Extended functionality: Add new API calls or integrate other services.
To contribute code, fork the repository, create a branch, and submit a pull request; read the project's contribution guidelines before committing to make sure the code is compliant. [](https://github.com/openai/openai-fm)[](https://github.com/fairy-root/ComfyUI-OpenAI-FM)
caveat
- API fees: Use of the OpenAI Speech API incurs a fee, depending on usage. Please monitor your API quota in the OpenAI dashboard.
- safety: If deployed to a public server, ensure that
.envfile is not made public to prevent API key leakage. - Community Support: If you encounter problems, you can submit an issue on GitHub and the community will help.
application scenario
- Developers test the Voice API
Developers can use openai-fm to quickly test the effectiveness of the OpenAI Speech API, verify the performance of different speech and emotion styles, and optimize application integration solutions. - Education and training content production
Teachers or trainers can convert course scripts to speech to generate natural and smooth audio for online courses or instructional videos. - Accessibility aids
openai-fm generates voice readings for visually impaired users to help them access text information. - Creative Content Creation
Podcast producers or content creators can use openai-fm to generate personalized voices and quickly create demo samples.
QA
- Do I need to pay for openai-fm?
The project itself is free, but using the OpenAI Speech API requires a valid API key and a fee based on usage. We recommend checking the official OpenAI website for pricing details. - How do I add a new voice option?
Edit the project directory under thedata/voices.jsonfile to add the new voice configuration. After restarting the server, the new voice appears in the drop-down menu. - Do I have to use a database for the sharing function?
Yes, the sharing feature requires PostgreSQL database support. If you don't configure the database, you can still generate and play speech normally. - Is it possible to use openai-fm on mobile?
The web interface of openai-fm supports responsive design and can be accessed in mobile browsers, provided that you have a stable internet connection.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles

No comments...