
Molmo: a series of multimodal open language models built by Ai2

General Introduction
Molmo is a multimodal open language model developed by the Allen Institute for AI (Ai2). The model combines textual and visual data processing capabilities to recognize objects in images and generate accurate descriptions.Molmo performs well in several benchmarks, demonstrating its power especially in complex tasks such as document reading and visual reasoning.Ai2 has posted these on Hugging FaceModels and datasetsand plans to release additional models and extended technical reports in the coming months, aimed at providing more resources for researchers, learn more details at Technical ReportThe
The key innovation of Molmo is its use of a new image description dataset, with models trained on PixMo, a dataset of one million highly selected image-text pairs. These datasets were collected exclusively by human annotators through voice descriptions. In addition, Molmo introduces a diverse mix of datasets for fine-tuning, including innovative two-dimensional pointing data that enables Molmo to answer questions not only in natural language, but also using non-verbal cues.

Molmo is based on Qwen2-72B and uses OpenAI's CLIP as a visual backbone to enhance the model's ability to process images and text.
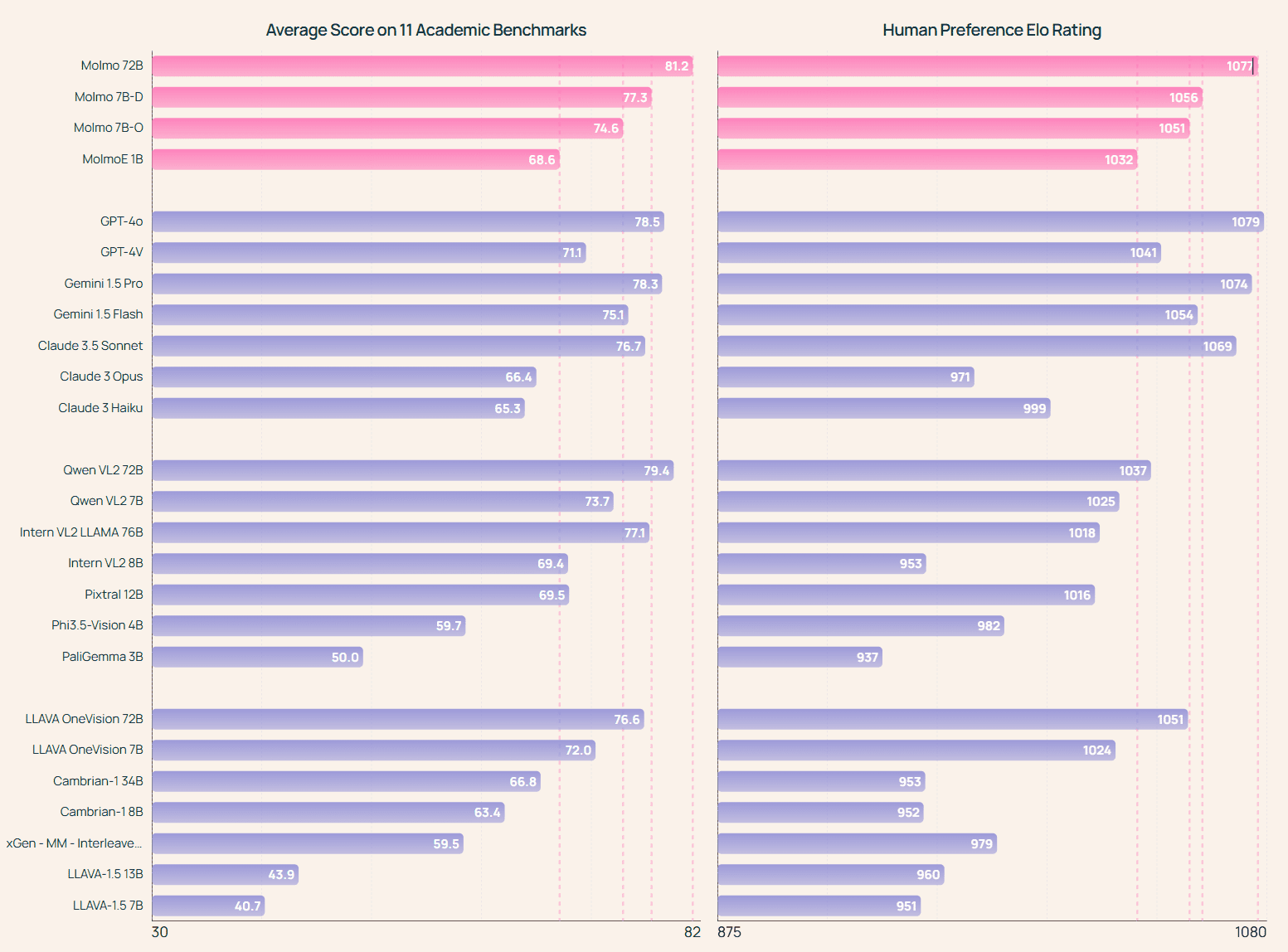
Molmo-72B: achieved the highest score on the Academic Benchmarking Test and ranked second on the Manual Assessment, only slightly below GPT-4o. also outperformed several state-of-the-art proprietary systems, including Gemini 1.5 Pro, Flash and Claude 3.5 Sonnet: MolmoE-1B: the most efficient Molmo model, based on our fully open OLMoE-1B-7B hybrid expert LLM, which performs almost as well as GPT-4V in both academic benchmarks and manual evaluations. Two Molmo-7B models: perform between GPT-4V and GPT-4o in both academic benchmarks and manual evaluations, and significantly outperform the recently released Pixtral 12B model in both benchmarks.
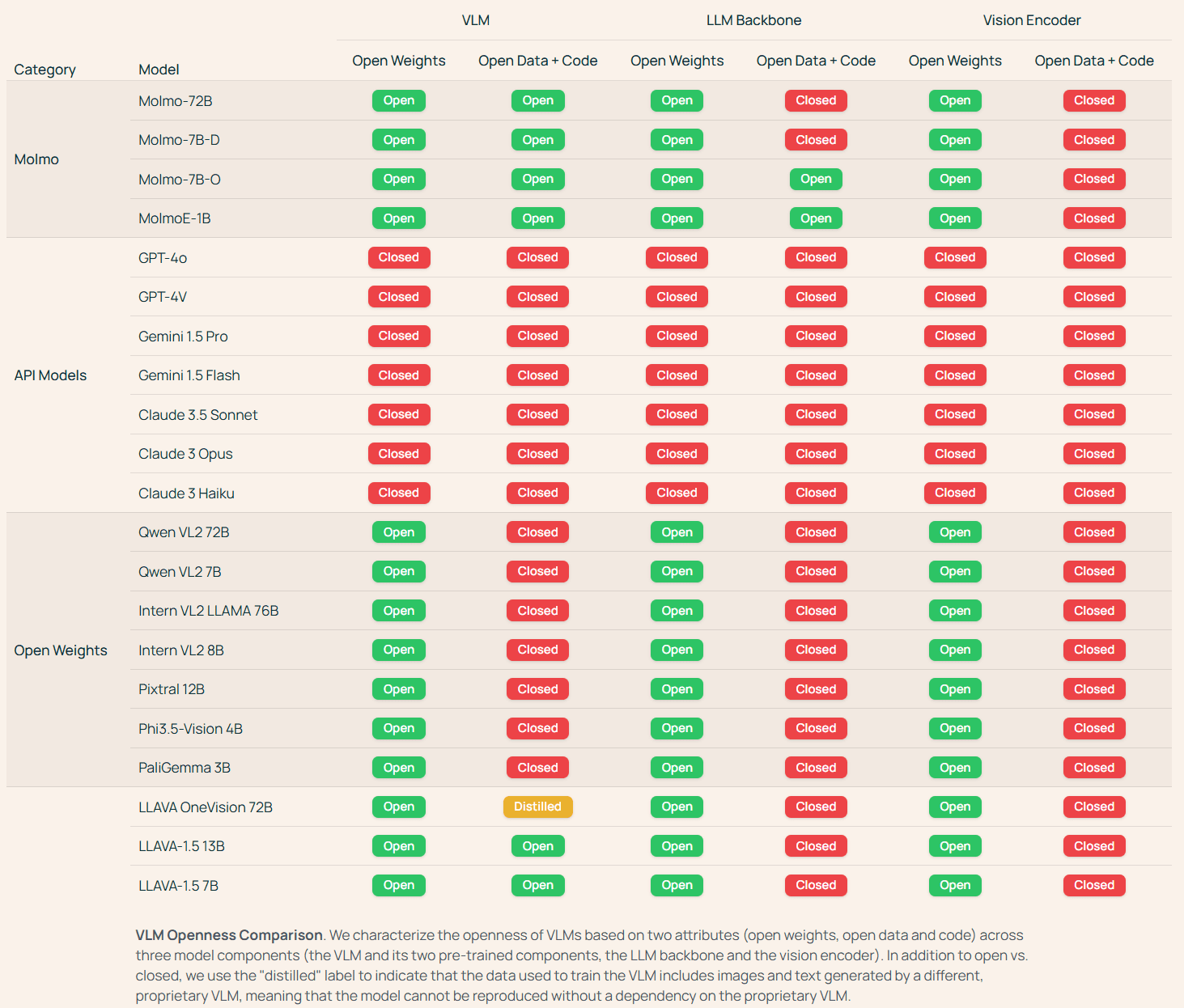
Open up more weights and data models
Function List
- Image recognition: the ability to recognize objects in an image and generate a description.
- Text Generation: Generate relevant text descriptions based on input text or images.
- Multimodal data processing: combining textual and visual data for complex tasks.
- Open source resources: open source resources for models and datasets are available for researchers.
- Online Demo: Provides an online demo function where users can upload images and generate descriptions.
Using Help
Guidelines for use
- image recognition: Click on the "Upload Image" button on the home page of the website and select the image file to be recognized. After uploading, the system will automatically generate an image description.
- Text Generation: Enter the text or question you want to generate a description for in the text box, click the "Generate" button, and the system will generate the relevant text description according to the input content.
- Multimodal data processing: Users can upload both images and text, and the system will combine both and generate a comprehensive description.
- open source resource: Visit the Hugging Face platform, search for Molmo models, and download and use the open source resources provided.
- Online Demo: Click on the "Online Demo" button on the home page of the website to access the demo page. Users can upload images or enter text to experience Molmo's features in real time.
Functional operation flow
- image recognition::
- Open the Molmo website and click on the "Upload Image" button.
- Select the image file to be recognized and click "Upload".
- Wait for the system to process and generate an image description.
- View and save the generated description.
- Text Generation::
- In the text box, enter the text or question for which you want to generate a description.
- Click the "Generate" button and wait for the system to process.
- View the generated text description and edit or save it as needed.
- Multimodal data processing::
- Upload the image and text at the same time and click the "Process" button.
- The system combines images and text for processing to generate a comprehensive description.
- View and save the generated synthesized description.
- Use of open source resources::
- Visit the Hugging Face platform and search for Molmo models.
- Download the model and dataset, follow the instructions for installation and use.
- Use the sample code and documentation provided for secondary development or research.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts

No comments...