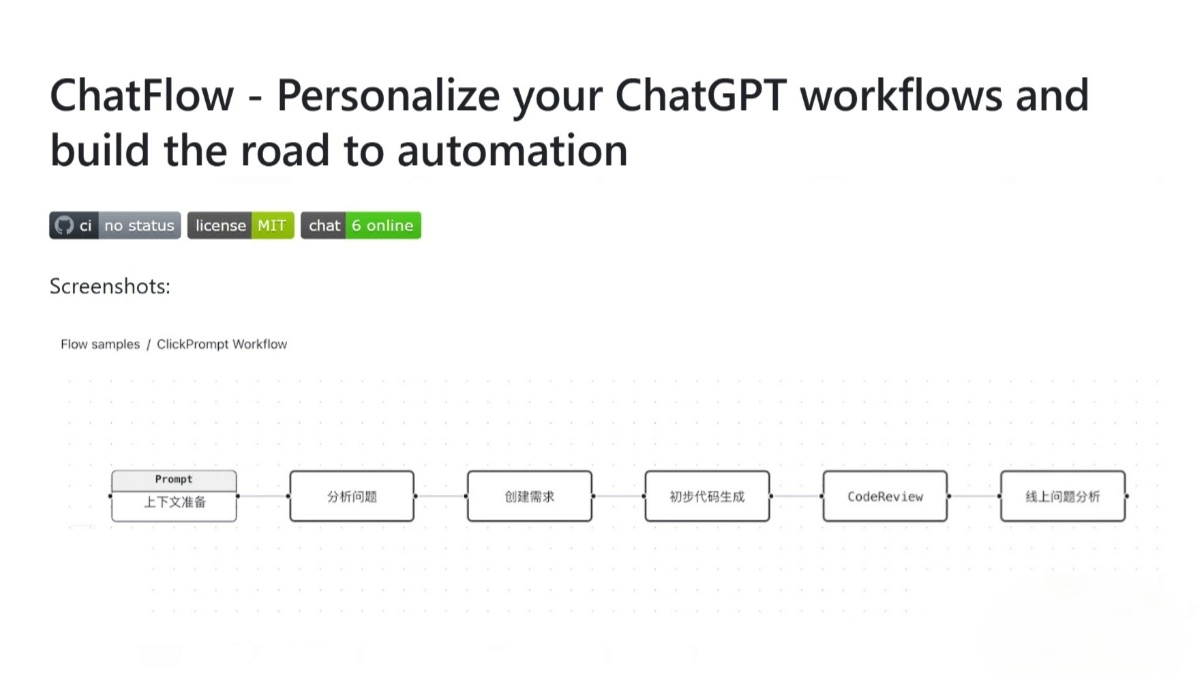
MM-EUREKA: A Multimodal Reinforcement Learning Tool for Exploring Visual Reasoning

General Introduction
MM-EUREKA is an open source project developed by Shanghai Artificial Intelligence Laboratory, Shanghai Jiao Tong University and other parties. It extends textual reasoning capabilities to multimodal scenarios through rule-based reinforcement learning techniques to help models process image and textual information. The core goal of this tool is to improve the performance of models on visual and mathematical reasoning tasks. It presents two main models, MM-Eureka-8B and MM-Eureka-Zero-38B, which enable efficient training with small amounts of data, such as outperforming other models that require millions of data with only 54K of graphical data. The project is completely open source, and the code, models, and data are freely available on GitHub for researchers and developers exploring multimodal inference techniques.

Function List
- Support for multimodal reasoning: the ability to process images and text simultaneously improves the model's ability to understand complex problems.
- Rule-based reinforcement learning: train models with simple rules to reduce dependence on large-scale data.
- Visual epiphanies: models can revisit image cues in their reasoning, mimicking the process of human reflection.
- Open Source Complete Pipeline: provides code, datasets and training flow for easy reproduction and improvement.
- High data efficiency: performance is comparable to models trained on millions of data with small amounts of data (e.g., 8K or 54K graphic pairs).
- Mathematical reasoning support: specifically optimized for mathematical problem solving for educational and academic scenarios.
Using Help
MM-EUREKA is an open source project based on GitHub, which is mainly aimed at users with a certain programming foundation, especially researchers and developers. The following is a detailed description of how to install and use this tool, including the main features of the actual operation process.
Installation process
- Preparing the environment
- Make sure you have Python 3.8 or later installed on your computer. This can be done with the command
python --versionCheck. - You need to install Git to clone your code. If you don't have Git, you can download and install it from the official website.
- Recommended for Linux systems (e.g. Ubuntu 20.04 or 22.04), Windows users may require additional configuration.
- Make sure you have Python 3.8 or later installed on your computer. This can be done with the command
- Cloning Project Code
- Open a terminal and enter the following command to download the MM-EUREKA source code:
git clone https://github.com/ModalMinds/MM-EUREKA.git - Once the download is complete, go to the project folder:
cd MM-EUREKA
- Open a terminal and enter the following command to download the MM-EUREKA source code:
- Installation of dependencies
- Run the following command to install the basic dependencies:
pip install -e . - If you need to use the vLLM Accelerated reasoning and additional packages need to be installed:
pip install -e .[vllm] - Install Flash-Attention (version 2.3.6) to improve performance:
pip install flash-attn==2.3.6 --no-build-isolationIf you encounter problems, try installing from source:
git clone https://github.com/Dao-AILab/flash-attention.git cd flash-attention git checkout v2.3.6 python setup.py install
- Run the following command to install the basic dependencies:
- Download Dataset
- The project provides training data MM-Eureka-Dataset, which can be downloaded from GitHub Releases.
- After downloading, unzip the file and modify the data as needed in the
image_urlsfield that points to the local image path.
- Verify Installation
- After the installation is complete, run
python -c "import mm_eureka"Check if there are any errors reported. If there are no errors, the installation was successful.
- After the installation is complete, run
Using the main functions
Function 1: Running a multimodal inference model
- Prepare data
- The data needs to be organized in JSONL format, with each row being a dictionary containing the
id,conversations,answercap (a poem)image_urlsFields. Example:{"id": "0", "conversations": [{"role": "user", "content": "这张图里的数学题答案是什么?"}], "answer": "42", "image_urls": ["file:///path/to/image.jpg"]} - Save the data as
dataset.jsonl, placed in the project directory.
- The data needs to be organized in JSONL format, with each row being a dictionary containing the
- running inference
- Enter the following command in the terminal to load the model and reason about it:
python scripts/inference.py --model MM-Eureka-8B --data dataset.jsonl - The output will show the model's reasoning process and answers for each question.
- Enter the following command in the terminal to load the model and reason about it:
Function 2: Train Customized Models
- Configuring Training Parameters
- show (a ticket)
config.yamlfile to set model parameters (e.g., learning rate, batch size) and data paths. - assure
data_pathPoint it at you.dataset.jsonlDocumentation.
- show (a ticket)
- priming training
- Run the following command to start training:
python scripts/train.py --config config.yaml - During training, the model saves checkpoints to the
checkpoints/Folder.
- Run the following command to start training:
Function 3: Testing Visual Epiphanies
- Preparing test data
- Use data from complex math problems that contain images, such as picking a few problems from the K12 dataset.
- operational test
- Enter the command:
python scripts/test_reflection.py --model MM-Eureka-Zero-38B --data test.jsonl - The model will show the reasoning process, including how to re-examine the image cues.
- Enter the command:
Example of an operational process: solving math problems
- Upload data
- Prepare an image (e.g., a geometry problem) and a corresponding problem description, saved in JSONL format.
- operational model
- expense or outlay
inference.pyThe script loads MM-Eureka-8B and enters the data.
- expense or outlay
- View Results
- The model outputs the inference step (
<think>tags) and the final answer (<answer>tags), for example:<think>先看图,圆的半径是 5,面积公式是 πr²,所以是 25π。</think> <answer>25π</answer>
- The model outputs the inference step (
caveat
- If you encounter insufficient GPU memory, adjust the batch size or use MM-Eureka-8B (smaller model).
- The image paths in the data must be valid or the model will not be able to process the image.
With these steps, you can easily get started with MM-EUREKA and experience its multimodal reasoning capabilities.
application scenario
- Educational aids
MM-EUREKA analyzes pictures of math problems and gives detailed steps to solve them, suitable for student practice or teacher preparation. - Scientific Exploration
Researchers can use it to test the effectiveness of reinforcement learning in multimodal tasks, improve algorithms or develop new models. - AR/VR Development
Developers can utilize its visual reasoning capabilities to build smarter interactive applications, such as real-time problem solving assistants.
QA
- What languages does MM-EUREKA support?
Currently, mainly English and Chinese graphic data are supported, and the model has the best inference effect for these two languages. - How strong a computer configuration is needed?
At least 16GB of RAM and a mid-range GPU (e.g. NVIDIA GTX 1660) is recommended. More powerful hardware may be required for training large models. - How do I contribute code?
To submit a Pull Request on GitHub, refer to theCONTRIBUTING.mdThe guidelines in the document.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...