llamafile: Distribute and run LLMs using a single file, simplify LLM deployment, cross-platform support for LLMs

General Introduction
llamafile is a tool from the Mozilla Builders project designed to simplify the deployment and operation of the Large Language Model (LLM). By combining the llama.cpp In conjunction with Cosmopolitan Libc, llamafile simplifies the complex LLM deployment process into a single executable file that supports running locally on a wide range of operating systems with no installation required. The tool not only supports text dialogs, but also handles image input to ensure data privacy.


Function List
- Single file operation: Packages the LLM model and runtime environment into a single executable.
- cross-platform compatibility: Windows, macOS, Linux, FreeBSD, OpenBSD and NetBSD are supported.
- local operation: No internet connection is required and all data processing is done locally to ensure privacy and security.
- multimodal support: Supports text and image input, providing rich interactive features.
- OpenAI API Compatible: Provides an interface compatible with the OpenAI API for easy integration with existing applications.
- high performance: Optimized matrix multiplication kernel for faster operation on CPU and GPU.
- open source project: Open source code, active community contributions, continuous updates and optimizations.
Using Help
Installation and operation
- Download llamafile: Access GitHub Page Download the latest version of llamafile.
- Delegation of executive authority(for macOS, Linux, BSD users):
chmod +x path/to/llamafile - Run llamafile::
- For macOS, Linux, BSD users:
./path/to/llamafile - For Windows users: Rename the file to
.exesuffix and run:.\path\to\llamafile.exe
- For macOS, Linux, BSD users:
Function Operation
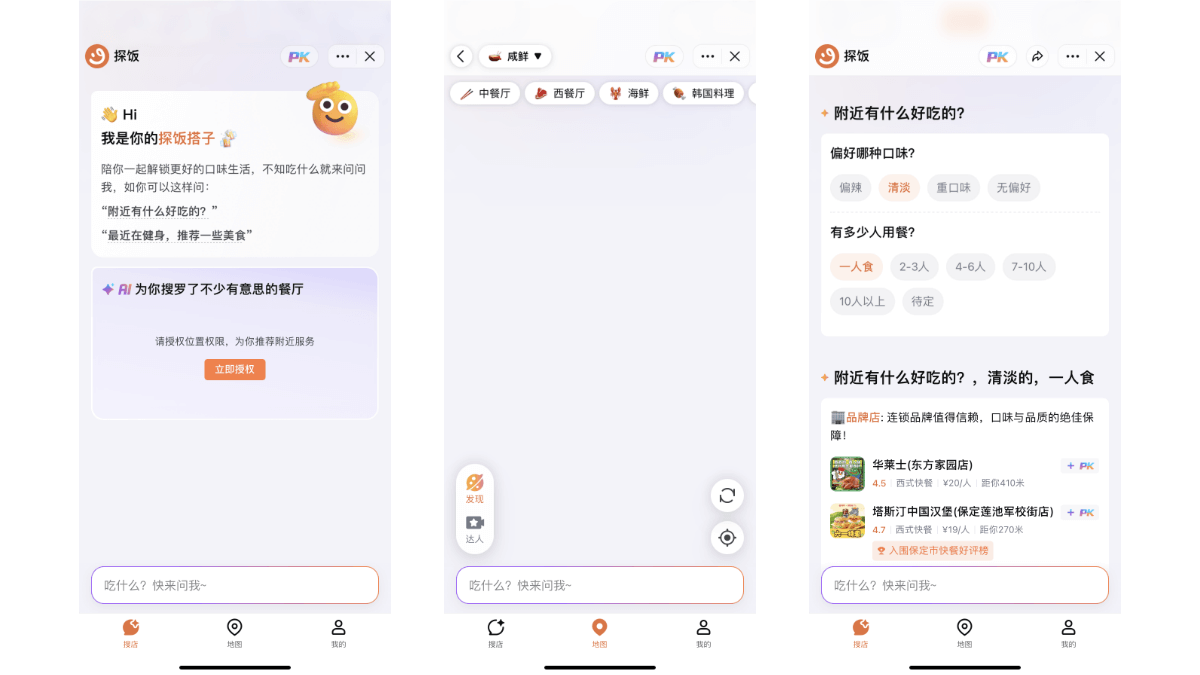
- Launching the Web Interface: After running llamafile, the browser will automatically open a chat screen (if it doesn't, please visit it manually).
http://127.0.0.1:8080/). - Using the OpenAI API Interface: llamafile provides an interface compatible with the OpenAI API and supports common API use cases. It can be invoked with the following commands:
curl http://localhost:8080/v1/chat/completions -H "Content-Type: application/json" -d '{ "model": "LLaMA_CPP", "messages": [{"role": "user", "content": "Hello, world!"}] }' - image input: Upload images and ask questions about them, for example:
curl -X POST http://localhost:8080/v1/images -F "image=@path/to/image.jpg" -F "prompt=Describe this image" - command-line mode: llamafile also supports command line mode for scripted operations:
./path/to/llamafile --cli -p "Your prompt here"
common problems
- Competence issues: If you encounter permissions problems, make sure the file has execute permissions (use the
chmod +x(Command). - File Size Limit: Windows users should note that the size of a single executable file cannot exceed 4GB, and external weight files can be used to resolve this issue.
- dependency issue: macOS users need to install Xcode Command Line Tools, Linux users may need to install the CUDA SDK or ROCm SDK to support GPU acceleration.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...