LLaMA Factory: Efficient fine-tuning of more than a hundred open-source large models, easy model customization

General Introduction
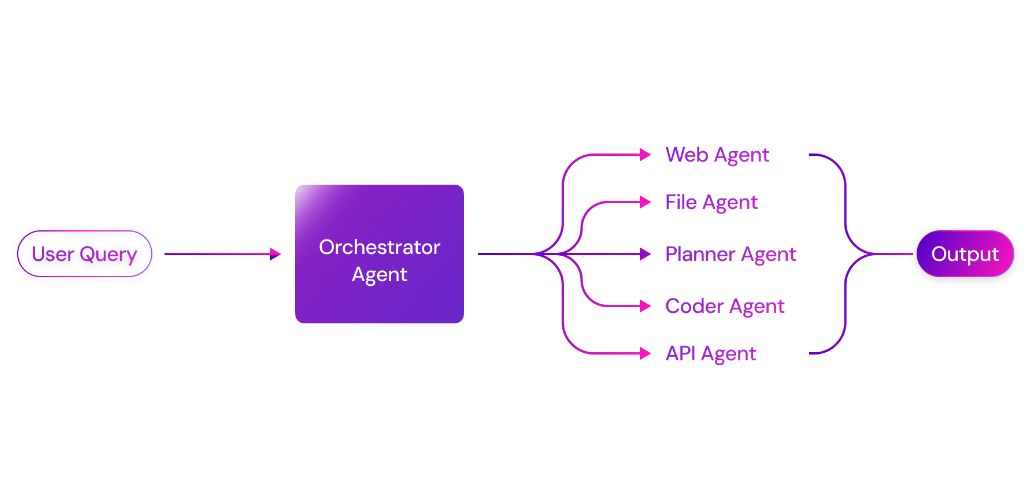
LLaMA-Factory is a unified and efficient fine-tuning framework that supports flexible customization and efficient training of more than 100 large language models (LLMs). Through the built-in LLaMA Board web interface, users can perform model fine-tuning without writing code. The framework integrates a variety of advanced training methods and practical tips to significantly improve training speed and GPU memory utilization.

Function List
- Multi-model support: Supports LLaMA, LLaVA, Mistral, Qwen, and many other language models.
- Multiple training methods: Includes full volume trimming, freeze trimming, LoRA, QLoRA, and more.
- efficient algorithm: Integration of GaLore, BAdam, Adam-mini, DoRA and other advanced algorithms.
- practical skill: Support for FlashAttention-2, Unsloth, Liger Kernel and more.
- Experimental monitoring: Provides monitoring tools such as LlamaBoard, TensorBoard, Wandb, MLflow, and more.
- fast inference: Provides OpenAI-like APIs, Gradio UI, and CLI interfaces.
- Dataset Support: Support for downloading pre-trained models and datasets from HuggingFace, ModelScope, and other platforms.
Using Help
Installation process
- Clone the project code:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
- Install the dependencies:
pip install -e ".[torch,metrics]"
Optional dependencies include: torch, torch-npu, metrics, deepspeed, liger-kernel, bitsandbytes, and more.
Data preparation
please refer to data/README.md Learn more about the dataset file format. You can use datasets on the HuggingFace / ModelScope / Modelers hub, or load datasets on local disk.
Quick Start
Use the following commands to run LoRA to fine-tune, reason about, and merge Llama3-8B-Instruct models:
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
llamafactory-cli chat examples/inference/llama3_lora_sft.yaml
llamafactory-cli export examples/merge_lora/llama3_lora_sft.yaml
For more advanced usage see examples/README.mdThe
Using the LLaMA Board GUI
Fine-tuning is done through the LLaMA Board GUI provided by Gradio:
llamafactory-cli webui
Docker Deployment
For CUDA users:
cd docker/docker-cuda/
docker compose up -d
docker compose exec llamafactory bash
For Ascend NPU users:
cd docker/docker-npu/
docker compose up -d
docker compose exec llamafactory bash
For AMD ROCm users:
cd docker/docker-rocm/
docker compose up -d
docker compose exec llamafactory bash
API Deployment
Use OpenAI-style APIs and vLLM Reasoning:
API_PORT=8000 llamafactory-cli api examples/inference/llama3_vllm.yaml
Visit this page for API documentation.
Download models and datasets
If you have trouble downloading models and datasets from Hugging Face, you can use ModelScope:
export USE_MODELSCOPE_HUB=1
Train a model by specifying the ModelScope Hub's model ID, for example LLM-Research/Meta-Llama-3-8B-InstructThe
Recording Experimental Results with W&B
To use Weights & Biases records the results of the experiment with the following parameters in the yaml file:
wandb:
project: "your_project_name"
entity: "your_entity_name"
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles


No comments...