

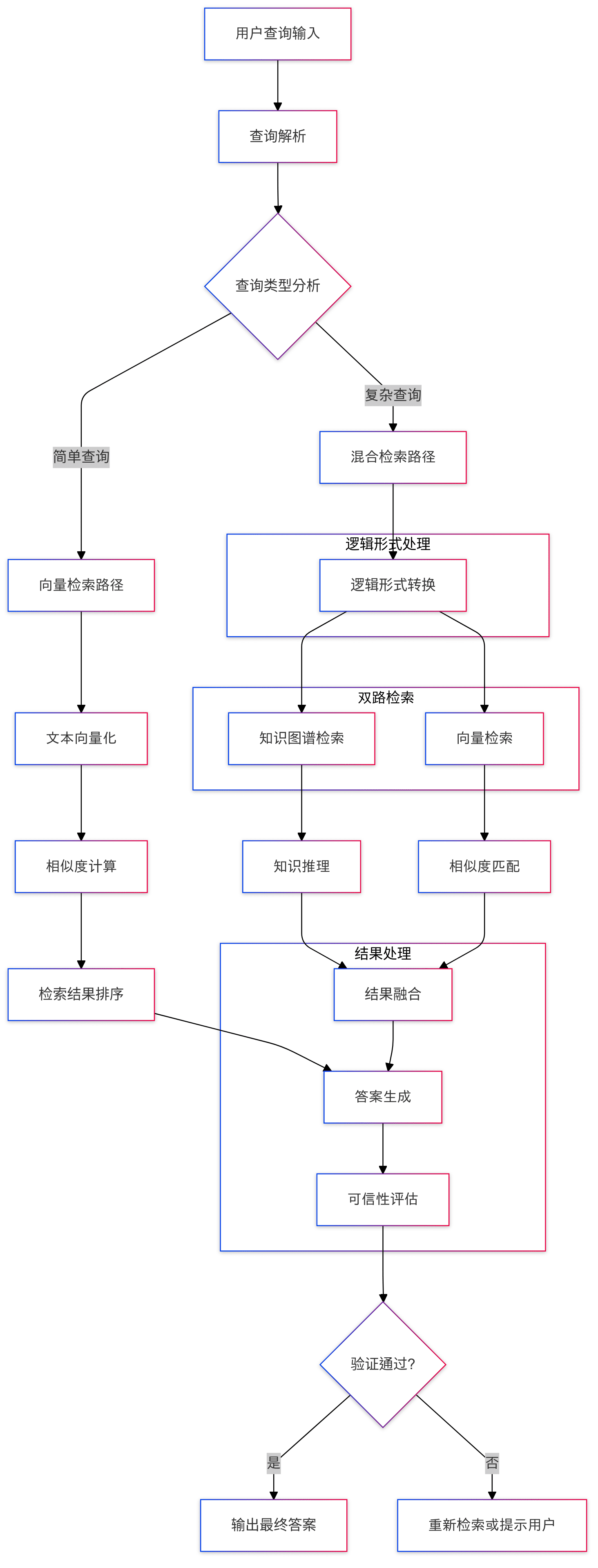
KAG: A Professional Knowledge Base Q&A Framework for Hybrid Knowledge Graph and Vector Retrieval

General Introduction
KAG (Knowledge Augmented Generation) is a logical form-guided reasoning and retrieval framework based on OpenSPG engine and Large Language Models (LLMs). The framework is specifically designed to build logical reasoning and fact-questioning solutions for specialized domain knowledge bases, effectively overcoming the shortcomings of the traditional RAG (Retrieval Augmented Generation) vector similarity computation model.KAG enhances the LLMs and knowledge graphs in four ways in a bidirectional manner by complementing the strengths of Knowledge Graphs and Vector Retrieval: LLM-friendly knowledge representations, inter-indexing between Knowledge Graphs and raw text fragments, hybrid reasoning solver, and hybrid reasoning solver. indexing, hybrid inference solver, and plausibility assessment mechanism. The framework is particularly well suited to handle complex knowledge logic problems such as numerical computation, temporal relations, and expert rules, providing more accurate and reliable question-answering capabilities for specialized domain applications.

Function List
- Ability to support reasoning in complex logical forms
- Provide a hybrid search mechanism of knowledge graph and vector retrieval
- Implementing LLM-friendly knowledge representation conversion
- Supports bi-directional indexing of knowledge structures and text blocks
- Integrating LLM Reasoning, Intellectual Reasoning, and Mathematical Logical Reasoning
- Provide mechanisms for credibility assessment and validation
- Supports multi-hop Q&A and complex query processing
- Provide customized solutions with a specialized domain knowledge base
Using Help
1. Environmental preparation
The first thing you need to do is make sure your system meets the following requirements:
- Python 3.8 or higher
- OpenSPG engine environment
- Supported API interfaces for large language models
2. Installation steps
- Cloning Project Warehouse:
git clone https://github.com/OpenSPG/KAG.git
cd KAG
- Install the dependency packages:
pip install -r requirements.txt
3. Framework utilization process
3.1 Knowledge base preparation
- Import of specialized domain knowledge data
- Configuring the Knowledge Graph Model
- Establishment of a text indexing system
3.2 Query processing
- Question input: the system receives natural language questions from the user
- Conversion of logical forms: converting problems into standardized logical expressions
- Mixed retrieval:
- Perform knowledge graph searches
- Perform a vector similarity search
- Integration of search results
3.3 Reasoning process
- Logical Reasoning: Multi-Step Reasoning with Mixed Reasoning Solvers
- Knowledge fusion: combining LLM reasoning and knowledge graph reasoning results
- Answer generation: forming the final answer
3.4 Credibility Assurance
- Answer verification
- Reasoning Path Tracing
- confidence assessment (math.)
4. Use of advanced functions
4.1 Customized knowledge representation
The knowledge representation format can be customized according to the needs of your area of expertise, ensuring compatibility with LLM:
# 示例代码
knowledge_config = {
"domain": "your_domain",
"schema": your_schema_definition,
"representation": your_custom_representation
}
4.2 Reasoning Rule Configuration
Specialized inference rules can be configured to handle domain-specific logic:
# 示例代码
reasoning_rules = {
"numerical": numerical_processing_rules,
"temporal": temporal_reasoning_rules,
"domain_specific": your_domain_rules
}
5. Best practices
- Ensuring the quality and integrity of knowledge base data
- Optimize search strategies for efficiency
- Regular updating and maintenance of the knowledge base
- Monitor system performance and accuracy
- Collect user feedback for continuous improvement
6. Resolution of common problems
- If you encounter retrieval efficiency problems, you can adjust the indexing parameters appropriately
- For complex queries, a stepwise reasoning strategy can be used
- Check knowledge representation and rule configuration when inference results are inaccurate
KAG Program Presentation
1. Introduction
A few days ago, Ant officially released a professional domain knowledge service framework, called Knowledge Augmented Generation (KAG: Knowledge Augmented Generation), which aims to fully utilize the advantages of Knowledge Graph and Vector Retrieval to solve the problem of the existing RAG Some challenges with the tech stack.
From the ants of this framework warm-up, I have been more interested in some of the core functions of KAG, especially logical symbolic reasoning and knowledge alignment, in the existing mainstream RAG system, these two points of discussion does not seem to be too much, take advantage of this open source, hurry to study a wave.
- KAG thesis address: https://arxiv.org/pdf/2409.13731
- KAG program address: https://github.com/OpenSPG/KAG
2. Overview of the framework
Before reading the code, let's take a brief look at the goals and positioning of the framework.
2.1 What & Why?
In fact, when I see the KAG framework, I believe that the first question that comes to mind for many people is why it is not called RAG but KAG. According to related articles and papers, the KAG framework is mainly designed to solve some of the current challenges faced by large models in knowledge services in specialized domains:
- LLM does not think critically and lacks reasoning skills
- Errors of fact, logic, precision, inability to use predefined domain knowledge structures to constrain model behavior
- Generic RAGs also struggle to address LLM illusions, especially covert misleading information
- Challenges and requirements of specialized knowledge services, lack of rigorous and controlled decision-making processes
Therefore, the Ant team believes that a professional knowledge service framework must have the following characteristics:
- It is important to ensure the accuracy of knowledge, including the integrity of knowledge boundaries and the clarity of knowledge structure and semantics;
- Logical rigor, time sensitivity and numerical sensitivity are required;
- Complete contextual information is also needed to facilitate access to complete supporting information when making knowledge-based decisions;
Ant's official positioning of KAG is: Professional Domain Knowledge Augmentation Service Framework, specifically for the current combination of large language models and knowledge graphs to enhance the following five areas
- Enhanced knowledge of LLM friendly
- Inter-indexing structure between knowledge graphs and original text fragments
- Logic Symbol Guided Hybrid Reasoning Engine
- Knowledge Alignment Mechanisms Based on Semantic Reasoning
- KAG model
This open-source covers the first four core features in their entirety.
Back to the issue of KAG naming, I personally speculate that it may still be to strengthen the concept of knowledge ontology. From the official description as well as the actual code implementation, the KAG framework, whether in the construction or reasoning stage, are constantly emphasizing the knowledge itself, to build a complete and rigorous logical link, in order to improve the RAG technology stack as much as possible some of the known problems.
2.2 What (How) is being achieved?
The KAG framework consists of three parts: KAG-Builder, KAG-Solver and KAG-Model:
- KAG-Builder for offline indexing consists of the above mentioned features 1 and 2: knowledge representation enhancement, mutual indexing structure.
- The KAG-Solver module covers Features 3 and 4: Logic-Symbol Hybrid Reasoning Engine, Knowledge Alignment Mechanism.
- KAG-Model attempts to build an end-to-end KAG model.
3. Source code analysis
This open source mainly involves KAG-Builder and KAG-Solver two modules, directly corresponding to the source code of the builder and solver two subdirectories.
During the actual study of the code, it is recommended to start with the examples The first thing you should do is to start with the directory to understand the flow of the whole framework, and then go deeper into the specific modules. The paths to the entry files of several demos are similar, such as kag/examples/medicine/builder/indexer.py as well as kag/examples/medicine/solver/evaForMedicine.pyAs you can clearly see, the builder combines different modules, while the real entry point for solver is in the kag/solver/logic/solver_pipeline.pyThe
3.1 KAG-Builder
Let's post the full catalog structure first
❯ tree .
.
├── __init__.py
├── component
│ ├── __init__.py
│ ├── aligner
│ │ ├── __init__.py
│ │ ├── kag_post_processor.py
│ │ └── spg_post_processor.py
│ ├── base.py
│ ├── extractor
│ │ ├── __init__.py
│ │ ├── kag_extractor.py
│ │ ├── spg_extractor.py
│ │ └── user_defined_extractor.py
│ ├── mapping
│ │ ├── __init__.py
│ │ ├── relation_mapping.py
│ │ ├── spg_type_mapping.py
│ │ └── spo_mapping.py
│ ├── reader
│ │ ├── __init__.py
│ │ ├── csv_reader.py
│ │ ├── dataset_reader.py
│ │ ├── docx_reader.py
│ │ ├── json_reader.py
│ │ ├── markdown_reader.py
│ │ ├── pdf_reader.py
│ │ ├── txt_reader.py
│ │ └── yuque_reader.py
│ ├── splitter
│ │ ├── __init__.py
│ │ ├── base_table_splitter.py
│ │ ├── length_splitter.py
│ │ ├── outline_splitter.py
│ │ ├── pattern_splitter.py
│ │ └── semantic_splitter.py
│ ├── vectorizer
│ │ ├── __init__.py
│ │ └── batch_vectorizer.py
│ └── writer
│ ├── __init__.py
│ └── kg_writer.py
├── default_chain.py
├── model
│ ├── __init__.py
│ ├── chunk.py
│ ├── spg_record.py
│ └── sub_graph.py
├── operator
│ ├── __init__.py
│ └── base.py
└── prompt
├── __init__.py
├── analyze_table_prompt.py
├── default
│ ├── __init__.py
│ ├── ner.py
│ ├── std.py
│ └── triple.py
├── medical
│ ├── __init__.py
│ ├── ner.py
│ ├── std.py
│ └── triple.py
├── oneke_prompt.py
├── outline_prompt.py
├── semantic_seg_prompt.py
└── spg_prompt.py
The Builder section covers a wide range of functionality, so we'll explore just one of the more critical components here. KAGExtractor The basic flowchart is shown below:

The main thing being done here is to utilize the big model to achieve automatic creation of knowledge graphs from unstructured text to structured knowledge graphs, briefly describing some of the important steps involved.
- The first is the entity recognition module, where specific entity recognition is performed first for predefined knowledge graph types, followed by generic named entity recognition. This two-tier recognition mechanism should be able to ensure that both domain-specific entities are captured and generic entities are not missed.
- The map construction process is actually composed of
assemble_sub_graph_with_spg_recordsmethod accomplishes this, and it's special in that the system converts attributes of non-basic types to nodes and edges in the graph, rather than continuing to keep them as the original attributes of the entity. This bit of change is honestly not very well understood, and to some extent is supposed to simplify the complexity of the entity, but in practice it's not quite clear how much this strategy pays off, and the complexity of the build has definitely increased. - Entity standardization by
named_entity_standardizationcap (a poem)append_official_nameThe two methods are done in concert. First the entity names are normalized and then these normalized names are associated with the original entity information. This process feels similar to Entity Resolution.
Overall, the functionality of the Builder module is quite close to the current common graph building technology stack, and the related articles and code are not too difficult to understand, so I won't repeat them here.
3.2 KAG-Solver
Solver part of the framework involves a lot of core functionality points, especially the logic of symbolic reasoning related content, first look at the overall structure:
❯ tree .
.
├── __init__.py
├── common
│ ├── __init__.py
│ └── base.py
├── implementation
│ ├── __init__.py
│ ├── default_generator.py
│ ├── default_kg_retrieval.py
│ ├── default_lf_planner.py
│ ├── default_memory.py
│ ├── default_reasoner.py
│ ├── default_reflector.py
│ └── lf_chunk_retriever.py
├── logic
│ ├── __init__.py
│ ├── core_modules
│ │ ├── __init__.py
│ │ ├── common
│ │ │ ├── __init__.py
│ │ │ ├── base_model.py
│ │ │ ├── one_hop_graph.py
│ │ │ ├── schema_utils.py
│ │ │ ├── text_sim_by_vector.py
│ │ │ └── utils.py
│ │ ├── config.py
│ │ ├── lf_executor.py
│ │ ├── lf_generator.py
│ │ ├── lf_solver.py
│ │ ├── op_executor
│ │ │ ├── __init__.py
│ │ │ ├── op_deduce
│ │ │ │ ├── __init__.py
│ │ │ │ ├── deduce_executor.py
│ │ │ │ └── module
│ │ │ │ ├── __init__.py
│ │ │ │ ├── choice.py
│ │ │ │ ├── entailment.py
│ │ │ │ ├── judgement.py
│ │ │ │ └── multi_choice.py
│ │ │ ├── op_executor.py
│ │ │ ├── op_math
│ │ │ │ ├── __init__.py
│ │ │ │ └── math_executor.py
│ │ │ ├── op_output
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ └── get_executor.py
│ │ │ │ └── output_executor.py
│ │ │ ├── op_retrieval
│ │ │ │ ├── __init__.py
│ │ │ │ ├── module
│ │ │ │ │ ├── __init__.py
│ │ │ │ │ ├── get_spo_executor.py
│ │ │ │ │ └── search_s.py
│ │ │ │ └── retrieval_executor.py
│ │ │ └── op_sort
│ │ │ ├── __init__.py
│ │ │ └── sort_executor.py
│ │ ├── parser
│ │ │ ├── __init__.py
│ │ │ └── logic_node_parser.py
│ │ ├── retriver
│ │ │ ├── __init__.py
│ │ │ ├── entity_linker.py
│ │ │ ├── graph_retriver
│ │ │ │ ├── __init__.py
│ │ │ │ ├── dsl_executor.py
│ │ │ │ └── dsl_model.py
│ │ │ ├── retrieval_spo.py
│ │ │ └── schema_std.py
│ │ └── rule_runner
│ │ ├── __init__.py
│ │ └── rule_runner.py
│ └── solver_pipeline.py
├── main_solver.py
├── prompt
│ ├── __init__.py
│ ├── default
│ │ ├── __init__.py
│ │ ├── deduce_choice.py
│ │ ├── deduce_entail.py
│ │ ├── deduce_judge.py
│ │ ├── deduce_multi_choice.py
│ │ ├── logic_form_plan.py
│ │ ├── question_ner.py
│ │ ├── resp_extractor.py
│ │ ├── resp_generator.py
│ │ ├── resp_judge.py
│ │ ├── resp_reflector.py
│ │ ├── resp_verifier.py
│ │ ├── solve_question.py
│ │ ├── solve_question_without_docs.py
│ │ ├── solve_question_without_spo.py
│ │ └── spo_retrieval.py
│ ├── lawbench
│ │ ├── __init__.py
│ │ └── logic_form_plan.py
│ └── medical
│ ├── __init__.py
│ └── question_ner.py
└── tools
├── __init__.py
└── info_processor.py
I've mentioned the solver entry file before, so I'll post the code here:
class SolverPipeline:
def __init__(self, max_run=3, reflector: KagReflectorABC = None, reasoner: KagReasonerABC = None,
generator: KAGGeneratorABC = None, **kwargs):
"""
Initializes the think-and-act loop class.
:param max_run: Maximum number of runs to limit the thinking and acting loop, defaults to 3.
:param reflector: Reflector instance for reflect tasks.
:param reasoner: Reasoner instance for reasoning about tasks.
:param generator: Generator instance for generating actions.
"""
self.max_run = max_run
self.memory = DefaultMemory(**kwargs)
self.reflector = reflector or DefaultReflector(**kwargs)
self.reasoner = reasoner or DefaultReasoner(**kwargs)
self.generator = generator or DefaultGenerator(**kwargs)
self.trace_log = []
def run(self, question):
"""
Executes the core logic of the problem-solving system.
Parameters:
- question (str): The question to be answered.
Returns:
- tuple: answer, trace log
"""
instruction = question
if_finished = False
logger.debug('input instruction:{}'.format(instruction))
present_instruction = instruction
run_cnt = 0
while not if_finished and run_cnt < self.max_run:
run_cnt += 1
logger.debug('present_instruction is:{}'.format(present_instruction))
# Attempt to solve the current instruction and get the answer, supporting facts, and history log
solved_answer, supporting_fact, history_log = self.reasoner.reason(present_instruction)
# Extract evidence from supporting facts
self.memory.save_memory(solved_answer, supporting_fact, instruction)
history_log['present_instruction'] = present_instruction
history_log['present_memory'] = self.memory.serialize_memory()
self.trace_log.append(history_log)
# Reflect the current instruction based on the current memory and instruction
if_finished, present_instruction = self.reflector.reflect_query(self.memory, present_instruction)
response = self.generator.generate(instruction, self.memory)
return response, self.trace_log
total SolverPipeline.run() The methodology involves 3 main modules:Reasoner, Reflector cap (a poem) GeneratorThe overall logic is still very clear: first try to answer the question, then reflect on whether the problem has been solved, and if not, continue to think deeply until you get a satisfactory answer or reach the maximum number of attempts. It basically mimics the general way of thinking of human beings in solving complex problems.
The following section further analyzes the three modules mentioned above.
3.3 Reasoner
The reasoning module is probably the most complex part of the whole framework, and its key code is as follows:
class DefaultReasoner(KagReasonerABC):
def __init__(self, lf_planner: LFPlannerABC = None, lf_solver: LFSolver = None, **kwargs):
def reason(self, question: str):
"""
Processes a given question by planning and executing logical forms to derive an answer.
Parameters:
- question (str): The input question to be processed.
Returns:
- solved_answer: The final answer derived from solving the logical forms.
- supporting_fact: Supporting facts gathered during the reasoning process.
- history_log: A dictionary containing the history of QA pairs and re-ranked documents.
"""
# logic form planing
lf_nodes: List[LFPlanResult] = self.lf_planner.lf_planing(question)
# logic form execution
solved_answer, sub_qa_pair, recall_docs, history_qa_log = self.lf_solver.solve(question, lf_nodes)
# Generate supporting facts for sub question-answer pair
supporting_fact = '\n'.join(sub_qa_pair)
# Retrieve and rank documents
sub_querys = [lf.query for lf in lf_nodes]
if self.lf_solver.chunk_retriever:
docs = self.lf_solver.chunk_retriever.rerank_docs([question] + sub_querys, recall_docs)
else:
logger.info("DefaultReasoner not enable chunk retriever")
docs = []
history_log = {
'history': history_qa_log,
'rerank_docs': docs
}
if len(docs) > 0:
# Append supporting facts for retrieved chunks
supporting_fact += f"\nPassages:{str(docs)}"
return solved_answer, supporting_fact, history_log
This results in an overall flowchart of the reasoning module: (logic such as error handling has been omitted)

It is easy to see thatDefaultReasoner.reason() The methodology is broadly divided into three steps:
- Logic Form Planning (LFP): mainly concerned with
LFPlanner.lf_planing - Logic Form Execution: mainly concerned with
LFSolver.solve - Document Reranking: mainly involves
LFSolver.chunk_retriever.rerank_docs
Each of the three steps is analyzed in detail below.
3.3.1 Logic Form Planning
DefaultLFPlanner.lf_planing() method is primarily used to decompose a query into a series of independent logical forms (lf_nodes: List[LFPlanResult]).
lf_nodes: List[LFPlanResult] = self.lf_planner.lf_planing(question)
The logic of its realization can be found in kag/solver/implementation/default_lf_planner.pyThe main focus is on the llm_output Do regularized parsing, or call LLM to generate a new logical form if not provided.
Here's something to keep an eye on kag/solver/prompt/default/logic_form_plan.py relevant provisions of the Basic Law LogicFormPlanPrompt The detailed design centers on how to decompose a complex problem into multiple subqueries and their corresponding logical forms.
3.3.2 Logic Form Execution
LFSolver.solve() Methods are used to solve specific logical form problems, returning answers, pairs of sub-problem answers, associated recall documents and history, etc.
solved_answer, sub_qa_pair, recall_docs, history_qa_log = self.lf_solver.solve(question, lf_nodes)
penetrate deeplykag/solver/logic/core_modules/lf_solver.pyThe source code section, which can be found LFSolver The class (Logical Form Solver) is the core class of the entire reasoning process and is responsible for executing the logical form (LF) and generating the answer:
- The main methods are
solvethat receives a query and a set of logical form nodes (List[LFPlanResult]). - utilization
LogicExecutorto execute logical forms, generate answers, knowledge graph paths, and history. - Processes subqueries and answer pairs, as well as related documentation.
- Error handling and fallback strategy: if no answer or relevant documentation is found, an attempt is made to use the
chunk_retrieverRecall related documents.
The main processes are as follows:

included among these LogicExecutor is one of the more critical classes, so here's the core code:
executor = LogicExecutor(
query, self.project_id, self.schema,
kg_retriever=self.kg_retriever,
chunk_retriever=self.chunk_retriever,
std_schema=self.std_schema,
el=self.el,
text_similarity=self.text_similarity,
dsl_runner=DslRunnerOnGraphStore(...),
generator=self.generator,
report_tool=self.report_tool,
req_id=generate_random_string(10)
)
kg_qa_result, kg_graph, history = executor.execute(lf_nodes, query)
- implementation logic
LogicExecutorThe relevant code for the class is located in thekag/solver/logic/core_modules/lf_executor.py. itsexecuteThe main execution flow of the method is shown below.
This execution flow demonstrates a dual retrieval strategy: prioritize the use of structured graph data for retrieval and inference, and fall back to unstructured textual information retrieval when the graph is unanswerable.
The system first tries to answer the question through the knowledge graph, for each logical expression node, through different actuators (involving thededuce,math,sort,retrieval,outputetc.) are processed, and the retrieval process collects SPO (subject-predicate-object) triples for subsequent answer generation; when the mapping fails to provide a satisfactory answer (returning "I don't know"), the system falls back to text block retrieval: using the previously obtained named entity (NER) results as the retrieval anchor point, and combining them with the historical Q&A records to construct a context-enhanced query, which is then passed through thechunk_retrieverRe-generate the answer based on the retrieved document.
The whole process can be seen as an elegant degradation strategy, and by combining structured knowledge graphs with unstructured text data, this hybrid retrieval is able to provide as complete and contextually coherent answers as possible while maintaining accuracy. - core component
In addition to the specific implementation logic described above, note that theLogicExecutorInitialization needs to pass multiple components. Limited to space, here only a brief description of the core function of each component, the specific implementation can refer to the source code.- kg_retriever: Knowledge Graph Retriever
consultationkag/solver/implementation/default_kg_retrieval.pycenterKGRetrieverByLlm(KGRetrieverABC), which realizes the retrieval of entities and relations, involving multiple matching methods such as exact/fuzzy, one-hop subgraphs, and so on. - chunk_retriever: text chunk retriever
consultationkag/common/retriever/kag_retriever.pycenterDefaultRetriever(ChunkRetrieverABC)The code here is worth studying, firstly, it is standardized in terms of Entity processing, and in addition, the retrieval here refers to HippoRAG, adopting a hybrid retrieval strategy combining DPR (Dense Passage Retrieval) and PPR (Personalized PageRank), and then further based on the integration of DPR and PPR Score. In addition, the hybrid retrieval strategy combining DPR (Dense Passage Retrieval) and PPR (Personalized PageRank) is adopted, and further fused based on the scores of DPR and PPR, which realizes the dynamic weight allocation of the two retrieval methods. - entity_linker (el): entity linker
consultationkag/solver/logic/core_modules/retriver/entity_linker.pycenterDefaultEntityLinker(EntityLinkerBase), the idea of constructing features before parallelizing the processing of entity links is used here. - dsl_runner: graph database querier
consultationkag/solver/logic/core_modules/retriver/graph_retriver/dsl_executor.pycenterDslRunnerOnGraphStore(DslRunner), responsible for the structured query information into a specific graph database query statement , this piece will involve the underlying specific graph database , the details of the relatively complex , but not too much involved .
- kg_retriever: Knowledge Graph Retriever
Going through the above code and flowchart, it can be seen that the entire Logic Form Execution loop utilizes a hierarchical processing architecture:
- the top of a building
LFSolverResponsible for the overall process - mesosphere
LogicExecutorResponsible for implementing specific logical forms (LF) - demersal
DSL RunnerResponsible for interacting with the graph database
3.3.3 Document Reranking
If the chunk_retriever, will also reorder the recalled documents.
if self.lf_solver.chunk_retriever:
docs = self.lf_solver.chunk_retriever.rerank_docs(
[question] + sub_querys, recall_docs
)
3.4 Reflector
Reflector class primarily implements the _can_answer together with _refine_query Two methods, the former for determining whether a question can be answered and the latter for optimizing the intermediate results of a multi-hop query to guide the generation of the final answer.
Related Implementation References kag/solver/prompt/default/resp_judge.py together with kag/solver/prompt/default/resp_reflector.py These two Prompt files are easier to understand.
3.5 Generator
mainly LFGenerator class, dynamically selects prompt word templates based on different scenarios (with or without knowledge graphs, with or without documents, etc.) and generates answers to the corresponding questions.
The relevant implementations are located in the kag/solver/logic/core_modules/lf_generator.py, the code is relatively intuitive and will not be repeated.
4. Some reflections
Ant this open source KAG framework, focusing on professional domain knowledge enhancement services, covering a series of innovative points such as symbolic reasoning, knowledge alignment, etc., a comprehensive study, I personally feel that the framework is particularly suitable for the need for strict constraints on the Schema of the professional knowledge of the scene, both in the indexing and querying stages, the entire workflow is repeatedly reinforced a point of view: must start from the constrained knowledge base to build the graphs or do logical reasoning. This mindset should alleviate to some extent the problem of missing domain knowledge as well as the illusion of large models.
Since Microsoft's GraphRAG framework has been open-sourced, the community has been thinking more about the integration of knowledge graphs and the RAG technology stack, such as the recent LightRAG, StructRAG and other work, which have done a lot of useful exploration. kAG, although there are some differences between the technical route and GraphRAG, can be regarded to a certain extent as a practice in the direction of knowledge enhancement services in the professional domain of GraphRAG, especially to make up for the shortcomings in knowledge alignment and reasoning. Although there are some differences between KAG and GraphRAG in terms of technology, KAG can be regarded as a practice of GraphRAG in the direction of knowledge enhancement services in specialized fields, especially in making up for the shortcomings in knowledge alignment and reasoning. From this perspective, I personally prefer to call it Knowledge constrained GraphRAG.
Native GraphRAG, with hierarchical summarization based on different communities, can answer relatively abstract high level questions, however, it is also because of the excessive focus on Query-focused summarization (QFS), which leads to the possibility that the framework may not perform well on fine-grained factual questions, and then considering the cost issue, the native GraphRAG has a lot of challenges in the pendant domain, while the KAG framework has made more optimizations from the graph construction stage, such as Entity alignment and standardization operations based on specific Schema, and in the query stage, it also introduces knowledge graph reasoning based on symbolic logic, although symbolic reasoning has been researched more in the field of graph, although it is not common to apply it to the RAG scenarios. The enhancement of RAG reasoning capability is a research direction that the author is more optimistic about, and some time ago Microsoft summarized the four layers of reasoning capability of the RAG technology stack:
- Level-1 Explicit Facts, Explicit Facts
- Level-2 Implicit Facts, Hidden Facts
- Level-3 Interpretable Rationales, Interpretable (Pendant Domain) Rationales
- Level-4 Hidden Rationales, invisible (pendant domain) rationales
At present, the reasoning ability of most RAG frameworks is still limited to Level-1 level, and the above Level-3 and Level-4 levels emphasize the importance of vertical reasoning, and the difficulty lies in the lack of knowledge of large models in the vertical domain, and the introduction of symbolic reasoning in the query stage of the KAG framework can be regarded as an exploration of this direction to a certain extent, and it can be foreseen that a wave of new research may be started in the following years on RAG reasoning, such as further integration of the model's own reasoning ability, such as RL or CoT. It is foreseeable that RAG reasoning may set off a wave of new research fervor, such as further fusion of the model's own reasoning ability, such as RL or CoT, etc. At this stage, some attempts have been made in the scene landing there are still more or less limitations.
In addition to the reasoning session, KAG references in Retrieval HippoRAG The hybrid retrieval strategy of DPR and PPR is adopted, and the efficient use of PageRank further demonstrates the advantages of knowledge graphs over traditional vector retrieval, and it is believed that more graph retrieval algorithms will be integrated into the RAG technology stack in the future.
Of course, it is estimated that the KAG framework is still in the early and rapid iteration stage, and there should still be some room for discussion on the concrete realization of the function, such as whether the existing Logic Form Planning and Logic Form Execution have complete theoretical support at the design level, and whether there will be insufficient decomposition and execution failure in the face of the complexity of the problem. Whether there will be insufficient decomposition, execution failure, but this boundary definition and robustness issues are usually very difficult to deal with, but also requires a lot of trial and error costs, if the entire reasoning chain is too complex, the ultimate failure rate may be higher, after all, a variety of degradation and regression strategy is only a certain degree of alleviation of the problem. In addition, I noticed that the GraphStore at the bottom of the framework has actually reserved an incremental update interface, but the upper layer application has not demonstrated the relevant capabilities, which is also a feature that I personally understand that the GraphRAG community calls for more highly.
In summary, the KAG framework is a very hardcore work in the recent past, containing a lot of innovative points, and the code has really done a lot of detail polishing, which is believed to be an important impetus for the landing process of the RAG technology stack.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts


No comments...