
Uncovering the Big Model Illusion: HHEM Rankings Provide Insight into the State of Factual Consistency in the LLM

While the capabilities of Large Language Models (LLMs) are constantly evolving, the "illusion" of factual errors or irrelevant information in their outputs has always been a major challenge that has prevented their wider use and deeper trust. In order to quantitatively assess this problem, theHughes Hallucination Evaluation Model (HHEM) Rankingswas born, focusing on measuring the frequency of illusions in mainstream LLMs when generating document summaries.
The term "illusion" refers to the fact that the model introduces "facts" into the summarization that are not contained in the original document, or even contradictory. This is a critical quality bottleneck for information processing scenarios that rely on LLM, especially those based on retrieval-enhanced generation (RAG). After all, if the model is not faithful to the given information, the credibility of its output is greatly reduced.
How does HHEM work?
This ranking uses the HHEM-2.1 hallucination assessment model developed by Vectara. How it works is that for a source document and a summary generated by a particular LLM, the HHEM model outputs a hallucination score between 0 and 1. The closer the score is to 1, the higher the factual consistency of the summary with the source document; the closer it is to 0, the more severe the hallucination, or even completely fabricated content.Vectara also provides an open-source version, HHEM-2.1-Open, for researchers and developers to perform the evaluation locally, and its model cards are published on the Hugging Face platform.
Assessment benchmarks
The evaluation used a dataset of 1006 documents, mainly from publicly available datasets such as the classic CNN/Daily Mail Corpus.The project team generated a summary for each document using the individual LLMs involved in the evaluation, and then computed the HHEM score for each pair (source document, generated summary). To ensure standardization of the evaluation, all model calls were set to temperature parameter is 0, which is intended to obtain the most deterministic output of the model.
The assessment indicators include, inter alia:
- Hallucination Rate. Percentage of abstracts with HHEM scores below 0.5. The lower the value, the better.
- Factual Consistency Rate. 100% minus the rate of hallucinations, reflecting the proportion of abstracts whose content is faithful to the original.
- Answer Rate. Percentage of models successfully generating non-empty summaries. Some models may refuse to answer or make errors due to content security policies or other reasons.
- Average Summary Length. The average number of words in the generated summaries provides a sideways view of the output style of the model.
LLM Illusions Leaderboard Explained
Below are the LLM hallucination rankings based on the HHEM-2.1 model assessment (data as of March 25, 2025, please refer to the actual update):
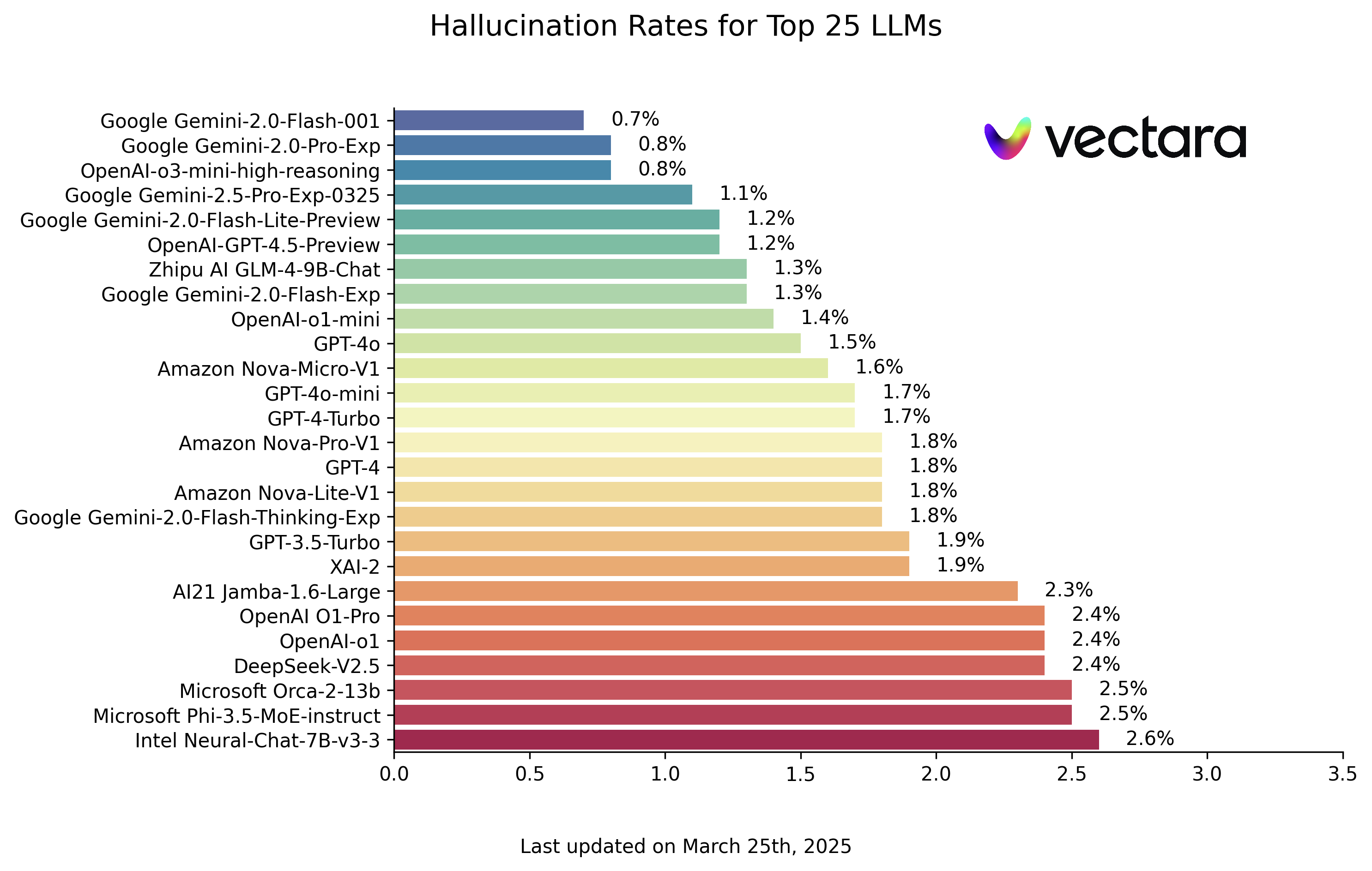
| Model | Hallucination Rate | Factual Consistency Rate | Answer Rate | Average Summary Length (Words) |
|---|---|---|---|---|
| Google Gemini-2.0-Flash-001 | 0.7 % | 99.3 % | 100.0 % | 65.2 |
| Google Gemini-2.0-Pro-Exp | 0.8 % | 99.2 % | 99.7 % | 61.5 |
| OpenAI-o3-mini-high-reasoning | 0.8 % | 99.2 % | 100.0 % | 79.5 |
| Google Gemini-2.5-Pro-Exp-0325 | 1.1 % | 98.9 % | 95.1 % | 72.9 |
| Google Gemini-2.0-Flash-Lite-Preview | 1.2 % | 98.8 % | 99.5 % | 60.9 |
| OpenAI-GPT-4.5-Preview | 1.2 % | 98.8 % | 100.0 % | 77.0 |
| Zhipu AI GLM-4-9B-Chat | 1.3 % | 98.7 % | 100.0 % | 58.1 |
| Google Gemini-2.0-Flash-Exp | 1.3 % | 98.7 % | 99.9 % | 60.0 |
| OpenAI-o1-mini | 1.4 % | 98.6 % | 100.0 % | 78.3 |
| GPT-4o | 1.5 % | 98.5 % | 100.0 % | 77.8 |
| Amazon Nova-Micro-V1 | 1.6 % | 98.4 % | 100.0 % | 90.0 |
| GPT-4o-mini | 1.7 % | 98.3 % | 100.0 % | 76.3 |
| GPT-4-Turbo | 1.7 % | 98.3 % | 100.0 % | 86.2 |
| Google Gemini-2.0-Flash-Thinking-Exp | 1.8 % | 98.2 % | 99.3 % | 73.2 |
| Amazon Nova-Lite-V1 | 1.8 % | 98.2 % | 99.9 % | 80.7 |
| GPT-4 | 1.8 % | 98.2 % | 100.0 % | 81.1 |
| Amazon Nova-Pro-V1 | 1.8 % | 98.2 % | 100.0 % | 85.5 |
| GPT-3.5-Turbo | 1.9 % | 98.1 % | 99.6 % | 84.1 |
| XAI-2 | 1.9 % | 98.1 | 100.0 % | 86.5 |
| AI21 Jamba-1.6-Large | 2.3 % | 97.7 % | 99.9 % | 85.6 |
| OpenAI O1-Pro | 2.4 % | 97.6 % | 100.0 % | 81.0 |
| OpenAI-o1 | 2.4 % | 97.6 % | 99.9 % | 73.0 |
| DeepSeek-V2.5 | 2.4 % | 97.6 % | 100.0 % | 83.2 |
| Microsoft Orca-2-13b | 2.5 % | 97.5 % | 100.0 % | 66.2 |
| Microsoft Phi-3.5-MoE-instruct | 2.5 % | 97.5 % | 96.3 % | 69.7 |
| Intel Neural-Chat-7B-v3-3 | 2.6 % | 97.4 % | 100.0 % | 60.7 |
| Google Gemma-3-12B-Instruct | 2.8 % | 97.2 % | 100.0 % | 69.6 |
| Qwen2.5-7B-Instruct | 2.8 % | 97.2 % | 100.0 % | 71.0 |
| AI21 Jamba-1.5-Mini | 2.9 % | 97.1 % | 95.6 % | 74.5 |
| XAI-2-Vision | 2.9 % | 97.1 | 100.0 % | 79.8 |
| Qwen2.5-Max | 2.9 % | 97.1 % | 88.8 % | 90.4 |
| Google Gemma-3-27B-Instruct | 3.0 % | 97.0 % | 100.0 % | 62.5 |
| Snowflake-Arctic-Instruct | 3.0 % | 97.0 % | 100.0 % | 68.7 |
| Qwen2.5-32B-Instruct | 3.0 % | 97.0 % | 100.0 % | 67.9 |
| Microsoft Phi-3-mini-128k-instruct | 3.1 % | 96.9 % | 100.0 % | 60.1 |
| Mistral Small3 | 3.1 % | 96.9 % | 100.0 % | 74.9 |
| OpenAI-o1-preview | 3.3 % | 96.7 % | 100.0 % | 119.3 |
| Google Gemini-1.5-Flash-002 | 3.4 % | 96.6 % | 99.9 % | 59.4 |
| Microsoft Phi-4-mini-instruct | 3.4 % | 96.6 % | 100.0 % | 69.7 |
| Google Gemma-3-4B-Instruct | 3.7 % | 96.3 % | 100.0 % | 63.7 |
| 01-AI Yi-1.5-34B-Chat | 3.7 % | 96.3 % | 100.0 % | 83.7 |
| Llama-3.1-405B-Instruct | 3.9 % | 96.1 % | 99.6 % | 85.7 |
| DeepSeek-V3 | 3.9 % | 96.1 % | 100.0 % | 88.2 |
| Microsoft Phi-3-mini-4k-instruct | 4.0 % | 96.0 % | 100.0 % | 86.8 |
| Llama-3.3-70B-Instruct | 4.0 % | 96.0 % | 100.0 % | 85.3 |
| InternLM3-8B-Instruct | 4.0 % | 96.0 % | 100.0 % | 97.5 |
| Microsoft Phi-3.5-mini-instruct | 4.1 % | 95.9 % | 100.0 % | 75.0 |
| Mistral-Large2 | 4.1 % | 95.9 % | 100.0 % | 77.4 |
| Llama-3-70B-Chat-hf | 4.1 % | 95.9 % | 99.2 % | 68.5 |
| Qwen2-VL-7B-Instruct | 4.2 % | 95.8 % | 100.0 % | 73.9 |
| Qwen2.5-14B-Instruct | 4.2 % | 95.8 % | 100.0 % | 74.8 |
| Qwen2.5-72B-Instruct | 4.3 % | 95.7 % | 100.0 % | 80.0 |
| Llama-3.2-90B-Vision-Instruct | 4.3 % | 95.7 % | 100.0 % | 79.8 |
| Claude-3.7-Sonnet | 4.4 % | 95.6 % | 100.0 % | 97.8 |
| Claude-3.7-Sonnet-Think | 4.5 % | 95.5 % | 99.8 % | 99.9 |
| Cohere Command-A | 4.5 % | 95.5 % | 100.0 % | 77.3 |
| AI21 Jamba-1.6-Mini | 4.6 % | 95.4 % | 100.0 % | 82.3 |
| XAI Grok | 4.6 % | 95.4 % | 100.0 % | 91.0 |
| Anthropic Claude-3-5-sonnet | 4.6 % | 95.4 % | 100.0 % | 95.9 |
| Qwen2-72B-Instruct | 4.7 % | 95.3 % | 100.0 % | 100.1 |
| Microsoft Phi-4 | 4.7 % | 95.3 % | 100.0 % | 100.3 |
| Mixtral-8x22B-Instruct-v0.1 | 4.7 % | 95.3 % | 99.9 % | 92.0 |
| Anthropic Claude-3-5-haiku | 4.9 % | 95.1 % | 100.0 % | 92.9 |
| 01-AI Yi-1.5-9B-Chat | 4.9 % | 95.1 % | 100.0 % | 85.7 |
| Cohere Command-R | 4.9 % | 95.1 % | 100.0 % | 68.7 |
| Llama-3.1-70B-Instruct | 5.0 % | 95.0 % | 100.0 % | 79.6 |
| Google Gemma-3-1B-Instruct | 5.3 % | 94.7 % | 99.9 % | 57.9 |
| Llama-3.1-8B-Instruct | 5.4 % | 94.6 % | 100.0 % | 71.0 |
| Cohere Command-R-Plus | 5.4 % | 94.6 % | 100.0 % | 68.4 |
| Mistral-Small-3.1-24B-Instruct | 5.6 % | 94.4 % | 100.0 % | 73.1 |
| Llama-3.2-11B-Vision-Instruct | 5.5 % | 94.5 % | 100.0 % | 67.3 |
| Llama-2-70B-Chat-hf | 5.9 % | 94.1 % | 99.9 % | 84.9 |
| IBM Granite-3.0-8B-Instruct | 6.5 % | 93.5 % | 100.0 % | 74.2 |
| Google Gemini-1.5-Pro-002 | 6.6 % | 93.7 % | 99.9 % | 62.0 |
| Google Gemini-1.5-Flash | 6.6 % | 93.4 % | 99.9 % | 63.3 |
| Mistral-Pixtral | 6.6 % | 93.4 % | 100.0 % | 76.4 |
| Microsoft phi-2 | 6.7 % | 93.3 % | 91.5 % | 80.8 |
| Google Gemma-2-2B-it | 7.0 % | 93.0 % | 100.0 % | 62.2 |
| Qwen2.5-3B-Instruct | 7.0 % | 93.0 % | 100.0 % | 70.4 |
| Llama-3-8B-Chat-hf | 7.4 % | 92.6 % | 99.8 % | 79.7 |
| Mistral-Ministral-8B | 7.5 % | 92.5 % | 100.0 % | 62.7 |
| Google Gemini-Pro | 7.7 % | 92.3 % | 98.4 % | 89.5 |
| 01-AI Yi-1.5-6B-Chat | 7.9 % | 92.1 % | 100.0 % | 98.9 |
| Llama-3.2-3B-Instruct | 7.9 % | 92.1 % | 100.0 % | 72.2 |
| DeepSeek-V3-0324 | 8.0 % | 92.0 % | 100.0 % | 78.9 |
| Mistral-Ministral-3B | 8.3 % | 91.7 % | 100.0 % | 73.2 |
| databricks dbrx-instruct | 8.3 % | 91.7 % | 100.0 % | 85.9 |
| Qwen2-VL-2B-Instruct | 8.3 % | 91.7 % | 100.0 % | 81.8 |
| Cohere Aya Expanse 32B | 8.5 % | 91.5 % | 99.9 % | 81.9 |
| IBM Granite-3.1-8B-Instruct | 8.6 % | 91.4 % | 100.0 % | 107.4 |
| Mistral-Small2 | 8.6 % | 91.4 % | 100.0 % | 74.2 |
| IBM Granite-3.2-8B-Instruct | 8.7 % | 91.3 % | 100.0 % | 120.1 |
| IBM Granite-3.0-2B-Instruct | 8.8 % | 91.2 % | 100.0 % | 81.6 |
| Mistral-7B-Instruct-v0.3 | 9.5 % | 90.5 % | 100.0 % | 98.4 |
| Google Gemini-1.5-Pro | 9.1 % | 90.9 % | 99.8 % | 61.6 |
| Anthropic Claude-3-opus | 10.1 % | 89.9 % | 95.5 % | 92.1 |
| Google Gemma-2-9B-it | 10.1 % | 89.9 % | 100.0 % | 70.2 |
| Llama-2-13B-Chat-hf | 10.5 % | 89.5 % | 99.8 % | 82.1 |
| AllenAI-OLMo-2-13B-Instruct | 10.8 % | 89.2 % | 100.0 % | 82.0 |
| AllenAI-OLMo-2-7B-Instruct | 11.1 % | 88.9 % | 100.0 % | 112.6 |
| Mistral-Nemo-Instruct | 11.2 % | 88.8 % | 100.0 % | 69.9 |
| Llama-2-7B-Chat-hf | 11.3 % | 88.7 % | 99.6 % | 119.9 |
| Microsoft WizardLM-2-8x22B | 11.7 % | 88.3 % | 99.9 % | 140.8 |
| Cohere Aya Expanse 8B | 12.2 % | 87.8 % | 99.9 % | 83.9 |
| Amazon Titan-Express | 13.5 % | 86.5 % | 99.5 % | 98.4 |
| Google PaLM-2 | 14.1 % | 85.9 % | 99.8 % | 86.6 |
| DeepSeek-R1 | 14.3 % | 85.7 % | 100.0% | 77.1 |
| Google Gemma-7B-it | 14.8 % | 85.2 % | 100.0 % | 113.0 |
| IBM Granite-3.1-2B-Instruct | 15.7 % | 84.3 % | 100.0 % | 107.7 |
| Qwen2.5-1.5B-Instruct | 15.8 % | 84.2 % | 100.0 % | 70.7 |
| Qwen-QwQ-32B-Preview | 16.1 % | 83.9 % | 100.0 % | 201.5 |
| Anthropic Claude-3-sonnet | 16.3 % | 83.7 % | 100.0 % | 108.5 |
| IBM Granite-3.2-2B-Instruct | 16.5 % | 83.5 % | 100.0 % | 117.7 |
| Google Gemma-1.1-7B-it | 17.0 % | 83.0 % | 100.0 % | 64.3 |
| Anthropic Claude-2 | 17.4 % | 82.6 % | 99.3 % | 87.5 |
| Google Flan-T5-large | 18.3 % | 81.7 % | 99.3 % | 20.9 |
| Mixtral-8x7B-Instruct-v0.1 | 20.1 % | 79.9 % | 99.9 % | 90.7 |
| Llama-3.2-1B-Instruct | 20.7 % | 79.3 % | 100.0 % | 71.5 |
| Apple OpenELM-3B-Instruct | 24.8 % | 75.2 % | 99.3 % | 47.2 |
| Qwen2.5-0.5B-Instruct | 25.2 % | 74.8 % | 100.0 % | 72.6 |
| Google Gemma-1.1-2B-it | 27.8 % | 72.2 % | 100.0 % | 66.8 |
| TII falcon-7B-instruct | 29.9 % | 70.1 % | 90.0 % | 75.5 |
Note: Models are ranked in descending order based on illusion rate. The full list and model access details can be viewed at the original HHEM Leaderboard GitHub repository.
A look at the leaderboard shows that Google's Gemini series of models and some of OpenAI's newer models (e.g., the o3-mini-high-reasoning) performed impressively, with the rate of hallucinations kept at a very low level. This shows the progress made by the head vendors in improving the factoriality of their models. At the same time, significant differences can be seen between models of different sizes and architectures. Some smaller models, such as Microsoft's Phi series or Google's Gemma series, also achieved good results, implying that the number of model parameters is not the only determinant of factual consistency. Some early or specifically optimized models, however, have relatively high rates of illusions.
Mismatch between strong inference models and knowledge bases: the example of DeepSeek-R1
the charts (of best-sellers) DeepSeek-R1 The relatively high rate of hallucinations (14.31 TP3T) raises a question worth exploring: why are some models that perform well on reasoning tasks instead prone to hallucinations in fact-based summarization tasks?
DeepSeek-R1 These models are often designed to handle complex logical reasoning, command following and multi-step thinking. Their core strength is in "deduction" and "deduction" rather than simply "retelling" or "paraphrasing". However, knowledge bases (especially RAG (knowledge base in scenarios) the core requirement is precisely the latter: the model needs to answer or summarize strictly on the basis of the textual information provided, minimizing the introduction of external knowledge or over-extraction.
When a strong reasoning model is restricted to summarizing only with a given document, its "reasoning" instincts can become a double-edged sword. It may:
- Overinterpretation. Extrapolating information from the original text unnecessarily deep and drawing conclusions that are not explicitly stated in the original text.
- Stitching Information. Attempts to connect the fragmented information in the original text through a "reasonable" logical chain that may not be supported by the original text.
- Default external knowledge. Even when asked to rely only on the original text, the vast world knowledge acquired in their training may still seep in unconsciously, leading to deviations from the facts of the original text.
Simply put, such models may "think too much", and in scenarios that require accurate and faithful reproduction of information, they are prone to be "too smart for their own good", creating content that appears to be reasonable but is actually an illusion. This shows that the reasoning ability and factual consistency of the model (especially in the case of restricted information sources) are two different ability dimensions. For scenarios such as knowledge bases and RAGs, it may be more important to choose models with a low rate of hallucination that faithfully reflect the input information than simply pursuing a reasoning score.
Methodology and background
The HHEM ranking did not come out of nowhere, and it builds on a number of previous efforts in the field of factual consistency research, such as the following SUMMAC, TRUE, TrueTeacher The methodology established in the papers of et al. The central idea is to train a model specialized in detecting hallucinations that achieves a level of high correlation with human evaluators in judging the consistency of summaries with the original text.
The summarization task was selected by the evaluation process as a proxy for LLM factuality. This is not only because the summarization task itself requires a high degree of factual consistency, but also because it is highly similar to the working model of the RAG system - in RAG, the LLM plays precisely the role of integrating and summarizing the retrieved information. Therefore, the results of this ranking are informative for assessing the reliability of the model in RAG applications.
It is important to note that the evaluation team excluded documents that the models refused to answer or gave extremely short and invalid answers, and ultimately used the 831 documents (from the original 1006) for which all models were able to successfully generate summaries for the final ranking calculation to ensure fairness. The answer rate and average summary length metrics also reflect the behavioral patterns of the models when processing these requests.
The Prompt template used for the evaluation is as follows:
You are a chat bot answering questions using data. You must stick to the answers provided solely by the text in the passage provided. You are asked the question 'Provide a concise summary of the following passage, covering the core pieces of information described.' <PASSAGE>'
At the time of the actual call, the<PASSAGE> will be replaced with the specific source document content.
looking forward
The HHEM ranking program has indicated that it plans to expand the scope of the evaluation in the future:
- Citation accuracy. Add an assessment of LLM's accuracy in citing sources in RAG scenarios.
- Other RAG tasks. Cover more RAG-related tasks, such as multi-document summarization.
- Multi-language support. Extend the assessment to languages other than English.
The HHEM ranking provides a valuable window for observing and comparing the ability of different LLMs to control illusions and maintain factual consistency. While it is not the only measure of model quality, nor does it cover all types of illusions, it has certainly driven the industry's attention to the issue of LLM reliability and provides an important reference point for developers to select and optimize models. As models and assessment methods continue to be iterated, we can expect to see even more progress in the provision of accurate and trustworthy information from LLMs.
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related posts



No comments...