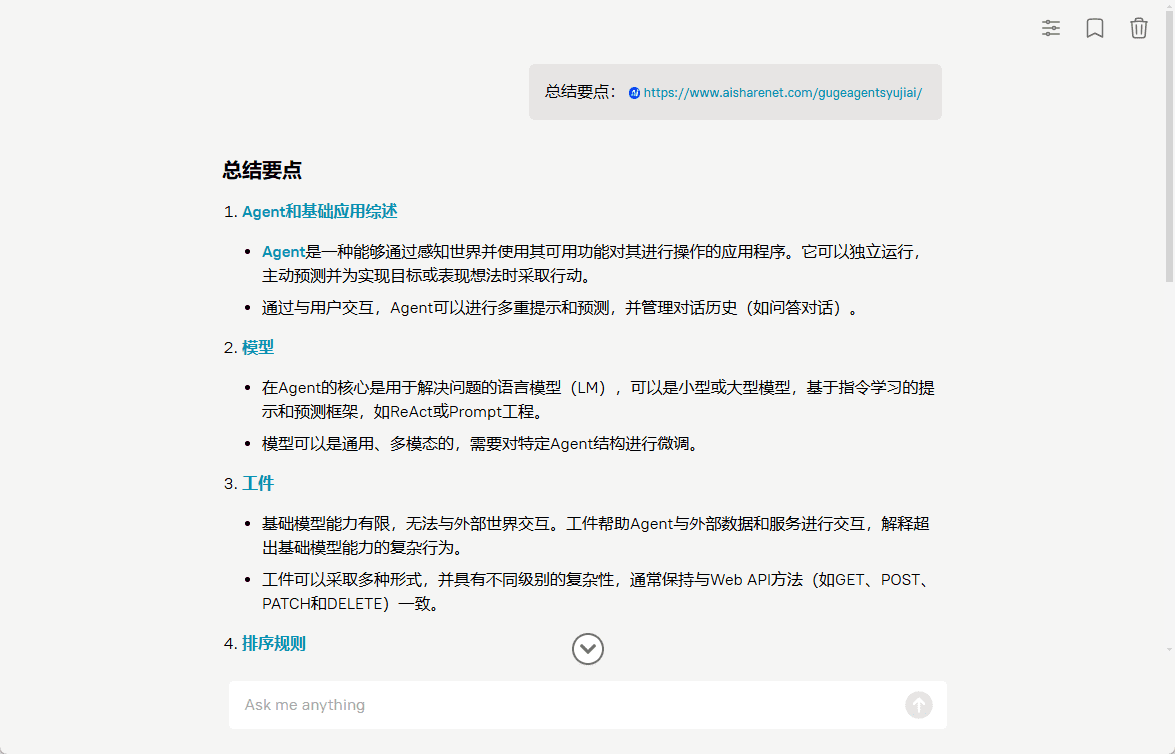
HippoRAG: A multi-hop knowledge retrieval framework based on long term memory

General Introduction
HippoRAG is an open source framework developed by the OSU-NLP group at The Ohio State University, inspired by human long term memory mechanisms. It combines Retrieval Augmented Generation (RAG), Knowledge Graph, and Personalized PageRank techniques to help Large Language Models (LLMs) consistently integrate knowledge from external documents.HippoRAG 2 is the latest version of HippoRAG, which has been demonstrated at NeurIPS 2024. It improves the model's ability to perform multi-hop retrieval and complex context understanding while maintaining low cost and low latency. It is less resource-intensive for offline indexing than solutions such as GraphRAG. Users can get the code via GitHub and deploy it for free.

HippoRAG2 Implementation Methodology
Function List
- Document Indexing: Convert external documents into searchable knowledge structures that support continuous updating.
- multihop search: Answer questions that require multi-step reasoning by making knowledge connections.
- Q&A Generation: Generate accurate responses based on search results.
- Model Support: Compatible with OpenAI models and native vLLM Deployed LLM.
- Efficient processing: Fast online retrieval and low offline indexing resource requirements.
- experimental verification: Provide datasets and scripts to support study replication.
Using Help
Installation process
The installation of HippoRAG is simple and suitable for users with a basic knowledge of Python. Here are the detailed steps:
- Creating a Virtual Environment
Create a Python 3.10 environment by entering the following command in the terminal:
conda create -n hipporag python=3.10
Then activate the environment:
conda activate hipporag
- Installation of HippoRAG
Runs in an activated environment:
pip install hipporag
- Configuring Environment Variables
Set the following variables according to your hardware and requirements. For example, use multiple GPUs:
export CUDA_VISIBLE_DEVICES=0,1,2,3
export HF_HOME=<你的 Huggingface 目录路径>
export OPENAI_API_KEY=<你的 OpenAI API 密钥> # 使用 OpenAI 模型时需要
Activate the environment again to ensure that it takes effect:
conda activate hipporag
Using OpenAI Models
To get started quickly with HippoRAG? you can use the OpenAI model. Here are the steps:
- Prepare the document
Create a list of documents, for example:
docs = [
"张三是一名医生。",
"李四住在北京。",
"北京是中国的首都。"
]
- Initialize HippoRAG
Setting parameters in Python:from hipporag import HippoRAG save_dir = 'outputs' llm_model_name = 'gpt-4o-mini' embedding_model_name = 'nvidia/NV-Embed-v2' hipporag = HippoRAG(save_dir=save_dir, llm_model_name=llm_model_name, embedding_model_name=embedding_model_name) - indexed document
Input documents for indexing:hipporag.index(docs=docs) - Questions and Answers
Enter a question to get the answer:queries = ["张三做什么工作?", "李四住在哪里?"] rag_results = hipporag.rag_qa(queries=queries) print(rag_results)The output may be:
- Zhang San is a doctor.
- Li Si lives in Beijing.
Using the Native vLLM Model
Want to deploy locally? You can run HippoRAG with vLLM. the steps are as follows:
- Starting the vLLM Service
Start the local service in the terminal, e.g. with the Llama model:export CUDA_VISIBLE_DEVICES=0,1 export VLLM_WORKER_MULTIPROC_METHOD=spawn export HF_HOME=<你的 Huggingface 目录路径> conda activate hipporag vllm serve meta-llama/Llama-3.3-70B-Instruct --tensor-parallel-size 2 --max_model_len 4096 --gpu-memory-utilization 0.95 - Initialize HippoRAG
Specify the local service address in Python:hipporag = HippoRAG(save_dir='outputs', llm_model_name='meta-llama/Llama-3.3-70B-Instruct', embedding_model_name='nvidia/NV-Embed-v2', llm_base_url='http://localhost:8000/v1') - Index & Q&A
The operation is the same as for the OpenAI model, just enter the document and the question.
Featured Function Operation
multihop search
The highlight of HippoRAG is the multi-hop search. For example, if you ask "Li Si lives in the capital of which country?" The system will first find "Li Si lives in Beijing", then relate it to "Beijing is the capital of China" and answer "China". To use it, you only need to input the question:
queries = ["李四住在哪个国家的首都?"]
rag_results = hipporag.rag_qa(queries=queries)
print(rag_results)
Experimental Reproduction
Want to validate the results of your paper? HippoRAG provides reproduction tools.
- Preparing the dataset
Download the dataset from GitHub or HuggingFace (e.g.sample.json), put in thereproduce/datasetCatalog. - running experiment
Enter it in the terminal:python main.py --dataset sample --llm_base_url https://api.openai.com/v1 --llm_name gpt-4o-mini --embedding_name nvidia/NV-Embed-v2 - View Results
Check the output to verify multi-hop retrieval and Q&A effectiveness.
offline batch processing
vLLM supports offline mode, and the indexing speed can be increased by more than 3 times. The operation is as follows:
- Running an offline batch
export CUDA_VISIBLE_DEVICES=0,1,2,3 export HF_HOME=<你的 Huggingface 目录路径> export OPENAI_API_KEY='' python main.py --dataset sample --llm_name meta-llama/Llama-3.3-70B-Instruct --openie_mode offline --skip_graph - follow-up operation
When finished, return to online mode to run the vLLM service and Q&A process.
caveat
- lack of memory: If the GPU memory is insufficient, adjust the
max_model_lenmaybegpu-memory-utilizationThe - adjust components during testing: Use of
reproduce/dataset/sample.jsonTest environment. - Clearance of documents: Clear the old data before rerunning the experiment:
rm -rf outputs/sample/*
© Copyright notes
Article copyright AI Sharing Circle All, please do not reproduce without permission.
Related articles

No comments...